“We’re going GraphQL, we’re replacing everything with GraphQL”
Sid Sijbrandij, GitLab founder and CEO
GraphQL is an open source technology created by Facebook that is getting a fair bit of attention of late. It is set to make a major impact on how APIs are designed.
As is so often the case with these things, it’s not terribly well named. It sounds like a general purpose query language for graph traversal, am I right? Something like Cypher.
It isn’t. The name is a little deceptive. GraphQL is about graphs if you see everything as graphs, but reading the the excellent, crisp docs GraphQL is primarily about designing your APIs more effectively, and being more specific about access to your data sources.
“GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data.”
With REST you can only pass a single set of arguments, but with GraphQL you can access a particular field or nested object without making multiple API fetches. You can call many resources in a single request. That in itself is a win. GraphQL has a set of standard types but you can also set custom types. A GraphQL query is a string sent to the runtime that returns JSON to the client.
Ah… I remember having a really similar feeling when I first came across jQuery, which is for adding flare to Javascript apps.
A few weeks back Chris Wanstrath, GitHub’s CEO, said all GitHub APIs would be developed GraphQL-first from here on in. This announcement came during a section labeled The Future of APIs at GitHub’s Satellite conference in London. Wanstrath said GitHub needs to engineer differently because its site gets more API calls than UI visits. Now when we GitHub builds a new feature first it builds a GraphQL API, which it then uses internally before roll out. One suggested graph use case was suggested reviewers for code. GitHub’s project boards are also now backed by GraphQL – and the service is seeing 125m queries per day.
More and more companies are seeing APIs as their primary access mechanism. Twilio, for example, one of the few successful IPOs in tech of recent times. REST, which has got us through the last few years of Web engineering, is looking a little creaky.
Github is not alone. The NY Times has just gone through a major back end redesign.
https://twitter.com/wonderboymusic/status/875006245190684673
So what about Facebook? It built GraphQL because it needed something powerful enough to describe Facebook’s API structure, but easy to learn by mobile developers. It is seeing billions of API calls a day now, so we know it scales. As Facebook points out, the shape of the query mirrors the shape of the response, which is cool.

The tree-based shape of the queries is one thing that attracted Neo4J to GraphQL. As a native Graph database it’s interested in the possibilities of extending GraphQL, with Cypher, but not modifying it so it can’t be used by other tools. The sandbox and integration are well worth checking out.
So does GraphQL replace REST? Phil Sturgeon has a very useful post summarising the philosophies of the two approaches, which he sees as complementary.
“Having one GraphQL server act as a sort of data proxy, giving one entry point for mixed data, one Authentication scheme despite each REST API having its own “unique” approach to tokens, one HTTP call for clients – despite it hitting multiple actual REST APIs, etc., would be a damn powerful thing.”
“If you need a highly query-able API, expect an array of clients that need small and different data, and can restructure your data to be inexpensive to query, then GraphQL is likely to fit your needs.”
I strongly agree with Sturgeon on the docs and developer experience.
“An alternative that is well documented, with a full specification, with a lovely marketing page, with an official reference implementation in JavaScript, and which avoids some of the tricky design choices REST forces you to make.”
Some of this stuff is fashion of course. REST has had a really good run, but is definitely looking less shiny these days. Developers like to try new things, and GraphQL’s timing is good. The companies adopting it are those that people want to emulate. But there are of course some dragons out there. In a followup Sturgeon points out that current caching models don’t map to GraphQL.
“Due to the way GraphQL operates as a query language POSTing against a single endpoint, HTTP is demoted to the role of a dumb tunnel, making network caching tools like Varnish, Squid, Fastly, etc. entirely useless.”
A web where Fastly doesn’t work, where HTTP is a problem, sounds problematical.
Kelly Sutton expands on the theme in a post Do We Need GraphQL?
“In the world of GraphQL, HTTP is an unfortunate transport mechanism rather than something to be embraced. Rather than using the standard semantics, we ignore them completely by treating HTTP like a dumb pipe. For companies with enough resources, treating HTTP like a dumb pipe is feasible. You can develop GraphQL-aware caching layers and deploy that logic to edge nodes around the globe. But most of us are not Facebook, so we need to stick with the standards we’ve got. This means using standards like HTTP to the fullest, so that we can be sure that our applications play nicely with vendors.”
But the benefits keep on twinkling. GraphQL introspection is interesting, as we grope towards self-documenting APIs with things like Swagger. Sashko Stubailo has some interesting ideas here. Check out GraphiQL – an inbrowser IDE for GraphQL.
There are some intriguing new services emerging to take advantage of GraphQL like graph.cool – which is effectively serverless or back end as a service GraphQL, which you’d use if you take the Joe Emison view of serverless not so much as Function as a Service (AWS Lambda) but as a model for building apps and services comprised of third party services such as Auth0, Algolia and Prerender.io. . Authory seems to be doing exactly that with its service for journalists wanting a single point of access for all their published content.Here we begin to edge into GraphQL not competing with REST so much as Firebase.
Scaphold is moving forward with a similar model – focusing on simplifying GraphQL-first apps deployment to Amazon Web Services (AWS) cloud. Early customers include Visa. These services are like Parse or Firebase for GraphQL.
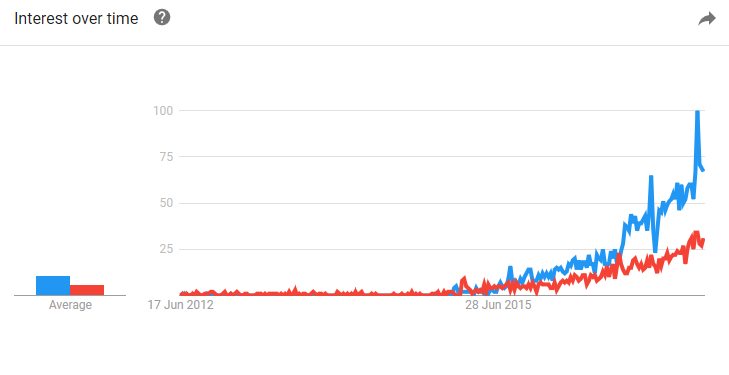
In summary GraphQL maps pretty well to new API-driven models such as serverless. Michael Hunger from Neo4j feels REST is worth retiring. That said, technologies don’t die overnight. REST is hardly going to disappear overnight. But for a class of problems for high scale sites it’s we’re going to see significant adoption of GraphQL. The Google Trends chart at the top of the page shows growing interest in GraphQL and gRPC – GraphQL is blue. GraphQL maps to external consumption of APIs, with gRPC for internal. They’re both clearly spiking in interest.
Let me know if you’re using or considering GraphQL. Certainly chatter is growing, and some very well respected engineers are choosing to run with it.
Google and Neo4J are clients.
Danno says:
June 15, 2017 at 7:04 pm
It looks fairly interesting. I’d have to spend a fair bit more time with it to see if it makes sense for what I’m doing, but I have long thought that a structured, type-oriented, non-language specific data interchange format is a good idea. GraphQL seems to be focused much more on describing data than being tied to a transport or serialization format. That’s good!
If HTTP isn’t the right way to issue those queries, then there’s no reason to transmit that data through those mechanisms. Hell, from the looks of it, JSON might not be the best way to actually serialize the data either.
Maybe this is being a bit premature, but maybe GraphQL is the replacement for arbitrary text formats in the Unix pipeline of the future.
jgovernor says:
June 15, 2017 at 9:07 pm
ayup danno! cool. glad to be of assistance. please let me know what you think once you have dug in.
Michael Hunger says:
June 16, 2017 at 12:40 pm
James,
really good introductory article. Looking forward to further observations from you in this exciting area.
here is my more detailed statement on GraphQL vs. REST:
GraphQL vs. REST
There has not been a lot of activity in the HTTP API area since the departure of SOAP and the establishment of REST and HATEOAS.
For REST, entities are made available to clients as representations via URIs and access to them by means of the existing HTTP verbs (GET, POST, PUT, DELETE, …). Navigation between entities and possible actions is achieved using links that are part of the server’s response. The granularity of the entity is generally fixed, but is often adaptable in practice by additional URL parameters.
The main critiques of GraphQL advocates to REST are the fixed granularity of entities, which often forces them to provide different resources of the same entity for different applications (e.g., mobile vs. desktop browsers or overview vs. detail view).
Furthermore, the limitation to the HTTP verbs is a shortcoming, because in many applications rather domain specific concrete actions (commands) with well-defined parameters are needed. And the lack of specification and type safety for query parameters, request payloads, links, and results is another important point of criticism.
Like REST, GraphQL is also located at the interface between services and their consumers.
The main focus is on the strongly typed, specific communication between both layers by means of flexible queries and actions. From this perspective, GraphQL is a clear representative of the communication patterns from Command Query Response Separation (CQRS).
The “root” queries correspond to the REST resources, but with flexible, defined parameterization. For neat projections of any width and depth, the nested projection of GraphQL is well suited. Fields can also provide calculated values or meta information.
And mutations are a more dynamic and meaningful improvement over the HTTP verbs.
While GraphQL is very strict in many regards, it’s composability makes it very powerful. And the language designers added extensibility at all levels with the use of parameters and custom @directives which are used by all vendors you mentioned in the article.
GraphQL is still a young language and specification but due to a great feedback process the development is driven by pragmatic needs of its user community balanced by the requirements of a stable language as the foundation of widely used APIs.
Due to the strong focus on middleware in the GraphQL stack, proxies are common, offering the integration of multiple backends, caching and monitoring. Of course you can also HTTP-GET operations for queries, which then re-enables the caching infrastructure of the web. But nowadays the use that infrastructure is already limited by security and personalized responses.
Cheers, Michael
PS: Can you fix the spelling of my last name.
What Is GraphQL and Why Should You Care? The Future of APIs - Nerd Junkie says:
June 21, 2017 at 2:19 am
[…] Read more at RedMonk […]
Internet of Things News of the Week, June 23 2017 | Stacey on IoT | Internet of Things news and analysis says:
June 23, 2017 at 1:38 pm
[…] Pay attention to this development for APIs: In some ways IoT is basically a bunch of web services cobbled together via APIs, which is why I enjoyed reading about Facebook’s development of GraphQL. The effort is basically a way to access many features from a complex API without making separate API calls for each function. It reduces the back and forth chatter between devices and services. That’s going to be good for users worried about using up computing resources and building services that are too complicated. (Redmonk) […]
Internet of Things News of the Week, June 23 2017 | Internet Of Things | IoT says:
June 23, 2017 at 4:25 pm
[…] Pay attention to this development for APIs: In some ways IoT is basically a bunch of web services cobbled together via APIs, which is why I enjoyed reading about Facebook’s development of GraphQL. The effort is basically a way to access many features from a complex API without making separate API calls for each function. It reduces the back and forth chatter between devices and services. That’s going to be good for users worried about using up computing resources and building services that are too complicated. (Redmonk) […]
Internet of Things News of the Week, June 23 2017 | Latest Mobile Technology Information says:
June 23, 2017 at 9:21 pm
[…] Pay attention to this development for APIs: In some ways IoT is basically a bunch of web services cobbled together via APIs, which is why I enjoyed reading about Facebook’s development of GraphQL. The effort is basically a way to access many features from a complex API without making separate API calls for each function. It reduces the back and forth chatter between devices and services. That’s going to be good for users worried about using up computing resources and building services that are too complicated. (Redmonk) […]