This is a cool demo of how IBM is enabling customers to modernize and maintain their mainframe applications with generative AI using IBM watsonx Code Assistant for Z.
The tool enables refactoring of monolithic applications, and mixed-language debugging, providing a unified developer experience across Java and COBOL using modern IDEs such as Visual Studio Code. The platform really brings modern developer experiences to mainframe modernisation. The AI model, trained with human-written code pairs and synthetic test generators, ensures trustworthiness and integration without context shifting in the application modernization life cycle across Java and COBOL. IBM watsonx Code Assistant for Z can describe COBOL-based functions, enabling refactoring, before generating Java-based code to support the same function.
This was a RedMonk video, sponsored by IBM.
Transcript
James Governor: Hey everybody, it’s James from RedMonk here. Yeah, I’ve got an interesting one today. We’ve got another What Is/How To video looking at some very specific technology. This is actually a follow up to a recent interview I did with Keri Olson, VP of AI for Code at IBM. But I’ve got a couple of other guests today in the shape of Husein Shamshudin, product manager for IBM Watson Code Assistant for Z, and Kyle Charlet, IBM fellow, CTO IBM Z Software. So IBM doesn’t specialize in short product names or even short job titles, but Kyle and Husein, great to see you today. Thanks for joining us.
Husein Shamshudin: Thanks for having us, James.
Kyle Charlet: Looking forward to it.
James: Okay, well, let’s jump in first with what even is watsonx Code Assistant for Z? Because we do have a use case. We’re going to talk today application modernization. What is the product?
Husein: Yeah, so IBM watsonx Code Assistant for Z is a generative AI infused application modernization set of tools to really help our clients solve one of the biggest problems they have. There’s a skills gap in the industry. People have been working on application modernization for quite some time. It’s a complex process. There have been a lot of false starts. What IBM has done is taken a step back, looked at the entire journey and brought generative AI smartly into that journey in order to help our clients modernize their mainframe applications.
James: Okay. And then in terms of the, I mean, I’ve got some questions. So. Yeah, what, I mean, like, I guess one of the questions I would have, and it’s about the model. I mean, you know, I’m not sure I’d exactly want to go to chatGPT and ask it to generate some COBOL code. So, why is your approach different? And why does it make sense for me to go and actually dive into using your tool for environments that perhaps might be underserved by some of the other players in market.
Husein: Well, let me share my screen. I’ll show you a little picture that talks about our differentiation. So hopefully you can see.
James: Yep.
Husein: So what we’ve done is we’ve looked at that mainframe application modernization journey end to end. This is not a case of just taking some COBOL and throwing it into an LLM and hoping for the best. We’ve seen that actually that doesn’t work. And so what we do is we take the clients through a step of understanding what they have today, which is sometimes they don’t even know. Right. People have left or moved on. They don’t know what their applications do. So we help them solve that problem, then we help refactor. So what this means is you could take a monolithic application, but we break it down into business services that you may then choose to transform from COBOL to Java. And this is where we bring the generative AI into the mix with our transform step. Step number three on the right side there. And then the last step, of course, you had COBOL, you’ve now got Java. And we want to validate that and make sure that the COBOL that you started with and the Java you have are semantically equivalent. And so this is a unique take. This is again, more than just throw some data into an LLM and hope for the best.
But you did ask about the model. Let me touch on that. We are one of what we consider one of the best code models in the industry. And we further train that with additional COBOL information, additional Java information. We’ve pulled in all of IBM’s expertise. We have hundreds of experts writing semantically equivalent COBOL and Java code pairs. And we’ve put all of that training into our model to really deliver a high value model. It’s even beyond just COBOL. It’s even the subsystems, because anyone in this space will know there’s the application than just the COBOL. You’re pulling in IMS, you’ve got KICKS, you’ve got all of these z/OS subsystems. We’ve trained the model on those two so that the Java you get understands the reality of the application and that’s unique. We’ve not seen anyone do that.
James: Okay. Yeah, it is a very specific use case, but it’s a very important use case. Every time I use a bank, every time I book a flight, that’s still all running on a mainframe. And yeah, the person that wrote the applications probably may well not be working there anymore, so. Okay. Understand the lifecycle. Understand then a little bit about the model. Should we just jump straight into a demo and show people what this actually looks like?
Husein: Absolutely. I’ll stop sharing and I’ll hand it over to Kyle.
James: Great. Okay, Kyle, so yeah, let’s have a look, let’s see it in action.
Kyle: That sounds good to me. So I’m going to dive right into it. On your previous interview with Keri, you asked specifically about the developer experience and what is the IDE experience there? So what I’m going to show you now is steps two, three and four, which are refactor, transform, validate. We brought all these together into a single id experience, which is VS code as you’re seeing in front of you here today. This is obviously important for a number of reasons.
James: This looks like a modern editor. To anybody that watches this show, they’d be like, oh I know that.
Kyle: Yeah, exactly right. And there’s a reason for this obviously, right? I mean, we don’t want developers context switching between which are different tools to do developer motion oriented tasks. Think about what you need to do to refactor, to transform, to validate. This is all a consistent and common developer motion. To switch between different tools and ides to accomplish this task is not something that we had an appetite for. Nor will clients have an appetite for this as well. This becomes equally important as you’re just doing just development in general. We have a lot of full stack developers. They aren’t just a COBOL specialist, they aren’t just a node specialist, they aren’t just a Java specialist. They’re actually full stack. To be able to operate in that single environment of VS code, to be able to actually do your development across all those languages, do mixed language debug across these different environments is a really big deal. As a developer, when I step into, step over, step through, set breakpoints in my code, I want to do it the exact same way, regardless of the language. And IBM bringing our languages to these top IDEs in the market is how we’re addressing that specifically.
James: Okay. I mean, I think that’s interesting. Partly the guy called Simon Willison, I think one of the most interesting people to follow in this industry, because of the way he’s helping people understand how LLMs are useful in writing code. And one of the things that he does talk about a lot is, it’s a different skills gap, but it is a skills gap. He’ll be in a thing where he wants to… he’ll have an idea for a tool to help build the tool and he’s like oh no, I’d have to learn this new thing to do it because he doesn’t have as much domain knowledge. So he’ll just go and use some of the tools that are out there to begin to understand what could be generated and then get an understanding of how that could be used. So this use case, even though it’s particularly application modernization here, this is something that developers across the industry are facing.
Kyle: Yeah, 100% absolutely right. I mean, honestly, I used to be one of those people that thought, hey, in IT you learn a new language all the time. I mean there’s been dozens of new languages brought to market since I got out of college. Dozens. More than that. And my ability to learn one was never really negatively impacted. It was always easy to learn something new. And so I sort of thought, well, isn’t COBOL the same? Isn’t PL/I the same? Well, the reality was it wasn’t the same, not because the language itself, but because of the ecosystem that surrounded that language. All the tools that I would have had to learn in order to learn how to write a COBOL application, the tools that I have to learn to debug that application, which was widely different than anything I’d ever learned before. Right? So it wasn’t just about the language, it was about the entire experience and ecosystem of tools and support around that language. Which is why bringing the languages to the editors was a strategic decision for IBM, because now it literally is the same. It is the same motions that a developer takes for COBOL as it is for Java, Node, Go, Python, what have you.
James: Perfect. And here’s me saying, let’s do a demo. And then I ask you a question. We don’t even jump into the demo. Show me what you got.
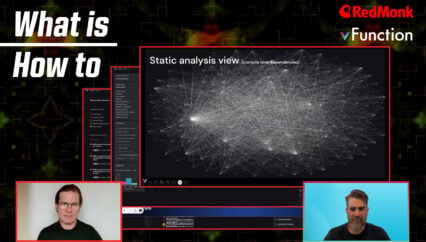
Kyle: Right on. So what we’ve done already is we’ve gone through the understand phase. This is where we have some scanners that’ll scan your git repos or scan directly in your mainframe, in your Z estate. We’ll scan the entirety of your application, of your entire application estate, take all that information and store it in a metadata repository. Then we enter the refactor phase. Refactor actually connects up to that metadata repository and pulls information related to a specific application I’m targeting. In this case, I’m targeting a CICS application. That what it does is it’s basically an insurance application. It’s got a number of services in it. Let me zoom out so you can see. So this right now on the glass, what we’re showing you is all of the different module dependencies and all the different data dependencies for this insurance application. Pretty simplistic version of an application that you’re seeing in front of you. I’ve worked with clients that just to do a simple account balance read, just a read account balance spanned 40 different COBOL modules. It was that sort of, I’m going to use the term over engineered. But when we talk about monolith, right, we talk about it typically kind of in a pejorative manner, but it’s really not. What we mean by monolith is a direct byproduct of an application surviving for decades and being relevant for decades. And being able to be supported for decades on our platform.
What happens when you have that situation is you have developers, different authors over the years of that same application that have a different design voice, a different architectural voice. And so you end up with these layers upon layers that get built in these applications over the years. And sometimes the developer wants a service that they don’t realize already existed because it was written 15 years ago, 20 years ago. So they reimplement that same service. So you get a lot of complexity in these applications. This is the way to start teasing that complexity out, to start saying, okay, I want to refactor out a specific business service as a part of this monolithic application. In this case, the business service we want to extract is the service that onboards a net new client, a net new customer. Now we know that this actually ultimately adds this new customer into a specific Db2 table. We can go and what we can do is we can select any single module. It’ll show us really the call path along the way.
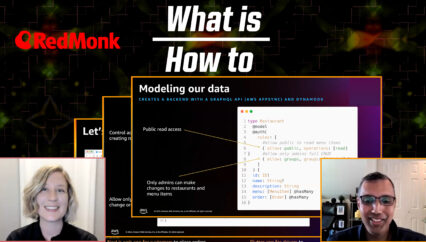
Let me actually zoom in a little. I zoomed out a little too much. What this tool is showing you is the ability to look at all the module data dependencies. And more specifically to do now is extract the business service that onboards a net new customer. We know the service is an ultimately insert the new customer into a specific table in a specific database. So if we select the actual table itself, we’ll see all the modules that end up being along the path to any activity against this actual Db2 datastore. So in this case we’re going to go to the head of this. We’re going to actually identify all the paragraphs in this particular COBOL module. So what it’s going to do is inspect this COBOL module and give us a list here on the left so you can see how it’s really integrated into the VS code experience.
It’ll give us a list of all the paragraphs in this particular module which is really the head of the snake here. We’ll notice there’s one called onboard customer. This is our starting point. This is where you want to extract and start actually extracting the code starting at this point and actually trace it all the way down through all the different modules along the path to the actual insert into the database, which is what we’re going to do now. But first I’m going to show you something that’s not yet generally available, but that’s coming very, very soon. The ability to explain the COBOL itself. So I can right click here, I can generate a detailed or summary explanation. We’ll start with summary. What it’s doing now is it’s prompting our LLM with the context of this entire paragraph and saying explain it to me. So here we’ll see just a very generic but very accurate summary of what this actual paragraph is doing. In a moment I’m going to show you a more detailed explanation as well. So explanation is coming. It’s very, very important. So as you might imagine, right —
James: Yeah, that was great, by the way. That was instantly like. I could just see how useful that was. It’s like, ok, we’ve got this context here that’s going to be extremely helpful. That’s a great use of LLMs.
Kyle: Absolutely, absolutely. What we’ll do next, we’ll go ahead, we’ll say let’s create a new service based on this starting point. It’s doing that right now. What you’ll see is it extracted code across several… I’ll go a little slowly here.
James: I’m not sure about your naming convention, Kyle. That’s going to make it real difficult for someone in another ten years. Come on, man.
Kyle: I should have thought that through. It’s all about me. So we’ll see here that it actually extracted several modules, several snippets of code across multiple modules in my estate. What I’m going to do now is say, you know what? That’s my starting point. Now generate an actual service from that. So a fully ready to compile COBOL service, which I’ve just done. Let me give us some little real estate. So it did was it actually crawled through the code from that module, across all the different modules to the ultimate destination of the insertion of the new customer. And now I’ve extracted that and said give me a brand new COBOL application, which is what I have now. Let me go in here and show you something that again, this element isn’t available today yet. It’s coming shortly. Let me now just double click on that and let me actually generate a detailed explanation now. Again, this takes a little bit longer because it’s getting, it’s the prompting that we’re doing, inference we’re doing is much richer than the summary explanation, but it’s communicating with our LLM and it’s going to give us back a much more detailed summary of what is actually happening within this COBOL paragraph itself.
When it actually comes through, I can choose to actually extract it or it can actually insert it in line right there in the code. But you’ll see here, just to scroll shortly, it is a significantly more detailed summary of what is actually happening in here, along with what happens when there’s an error, what happens when things are successful. Again, a lot of effort and work has gone into, let’s make sure we can explain this COBOL, because that in many cases needs to be the first step. Right. I might need to understand what this thing is doing to make sure I’m transforming exactly what I actually intend to transform.
James: Well, I mean, a lot of customers just don’t change their apps because they’re just not, don’t have the comfort factors.
Kyle: Yes.
James: So, yeah, okay, that’s legit.
Kyle: Yeah, we’re going to straight into our watsonx Code Assistant for Z plugin. I’m going to select COBOL. I’m going to select that transfer of COBOL, you’ll see from the timestamp, is exactly the one we just did a moment ago. I’m going to import that. Now I have this imported, I’m going to generate our Java classes from this. We do a couple of things which makes our transform step very, very unique. We don’t just ship all the code, the LLM and say transform this, because what we’re going to get is basically COBOL in JOBOL out. We’re going to get very, very procedural looking Java. As well, most in the market they do a line by line syntax translation of COBOL to Java. So you get COBOL syntax expressed in Java. That’s not lovely at all. It’s actually quite awful. Not that COBOL’s bad, but when you get COBOL syntax expressed in Java, that’s where it gets really gross. Step one is let’s actually take a look at all of the data structures used, all of the database schemas used. Let’s generate, and the actual business logic itself. Let’s generate several Java classes that support the data model as well as the actual business logic itself. Here you have some control over what you want to do and naming and all kinds of conventions here, but we’re going to straight generate the Java classes.
What you’ll see is we generated 26 Java classes. Let me pop in right in here. We’ll see several data model classes here as we analyze all the data structures, the COBOL copybooks, for example, the database schemas, and then implementation, we generated a bunch of real estate, a bunch of Java classes here as well. Now this is Generative AI. This is actually an AI assisted approach. It does not replace a developer. You’ll see, because this is real, there are a couple of errors across a few of these classes. Now these errors are simply based on statics. They were using statics and they should have actually used instance variables. So just basic stuff for a developer to come and clean up. But honestly it’s really quite pure when you look at it from out of the gate, out of the jump, very very few compiler errors. Let’s now go into the logic itself. Let you actually see specifically, go until you’ll notice here the actual insertion of the customer is just a method signature with no implementation whatsoever. So let’s actually transform this specifically. I’m going to generate the Java for this particular method. Internally now, we know how to map this back to the COBOL asset itself.
We know how to create and form the prompt, whether it’s zero, one or two shot prompting. We know how to build all the necessary metadata so it understands the Java class hierarchy that we’ve created previously? It needs to understand that because it needs to know what classes it has to even reference to get this, make this real. Right? So we’re actually prompting the model now, generating the code. Here we go. We can thumbs up, thumbs down, we can insert it inline in the code. And now you’ll see we’ve actually taken that code and thrown it in here. Now you’ll see there are a couple of errors. Let’s take a look at them. These are all basic, these are because the imports, the LLM didn’t actually add in the missing import statements for these particular libraries. So we’ll add them in for each one and you’ll see every error but two goes away. And there’s, there’s a silliness with actually trying to write narrow metrics with abstract requests that the LLM is getting a little turned around on. But that’s really it. We now have a fully baked and ready to roll method with all the implementation to actually insert that new customer.
There’s other methods in here that we can do the same thing too. We intentionally do this one method at a time because when developers are dealing at scale here they get much more control and they have much more awareness of what’s happening versus we just do the entire — we don’t want to do you know, 20,000 lines in to the model and say, here’s your new Java, right? They’re not going to know where to turn, they’re not going to what was done, they’re not going to follow the process. This is really important we do it this way. So this is again refactor. This is transform, right? Let’s get into validate, which is, you know, very important. So it’s like, hey, how do you prove to me that what you did is what you should have been doing? How do I know this job doing the right things? It sounds like you might have a question there.
James: No, no, I said 100%. I mean, it’s still going to be like, well, I’m not really sure I’m ready to ship this. This is scary.
Kyle: Exactly right. So here, what we have now is the output of a compilation of that COBOL class that we just generated over here. We start with that. And what’s happening here is that, and I’m going to actually point it to my load library here, aptly named Kyle, as it should be. This is where what we do now is we have the listing file and we actually have the compiled binary and we start at that level because you don’t trust the source, we trust the binary. So what’s happening here, let me actually give you some access to some real estate here, is it’s actually going through with that listing file overlaid on the binary. It’s actually reconstituting line by line the actual COBOL code itself. Then what is it doing? It’s actually generating values for input for each of the different paragraph domains in that COBOL asset and then capturing the output that it receives from that based on generated input. It’s squirreling and storing that away. Now we know exactly what the COBOL is doing. Now the next step we’re going to say we know what the COBOL is doing now. Let’s capture that and come right back to our Java.
Let’s actually run an equivalence test. What’s happening here is for the Java side, it’s actually generating standard Junit test case with standard open source automation framework for Java for both unit tests and even functional tests with Mockito to Mocking libraries and generating and running these tests. I can pop down here, I can see in this case it had two out of two equivalence test pass. Why only two in this case? Very simple reason. This code only has two code branches. There’s an if branch and an else branch. So we made sure we generated code that was going to ensure coverage across those two branches, then executed the code with all of the assertions that we received from the COBOL asset. We’re now applying those assertions, those validations to the Java asset via Junit test cases that are take home for our clients to integrate in their own DevOps pipelines for their own unit testing as they roll their code out for production usage. So that’s the demo. That’s what we really want to take you through, which was the refactor transform validate and with a little teaser for explanation moving forward. So we can use any COBOL file and start saying, tell me what this — we can actually write — we can actually just highlight code in COBOL, right click and say explain this code that I just highlighted. All of those important things are coming very, very shortly. Any questions or reactions?
James: No, I think it’s pretty cool. I mean, quite honestly, I think that the question I would have is maybe for people watching the video, because the interesting thing is that you could really, regardless of what language you knew, begin to get a sense for… I mean, obviously if you’re a Java programmer, that’s going to make the most sense. But certainly, yeah, I suspect that a lot of the people looking at this will also, if you’re going to watch the video that’s about mainframe modernization, you may be at least COBOL curious, but I think at least in terms of the explanations and that the sort of the interchangeability with the understanding the differences, you know, object oriented versus procedural. And you know, that’s quite a compelling demo. I thought that was, yeah, that was pretty cool.
Kyle: Yeah, glad to hear it.
James: Yeah, that’s a terrible question, but it’s, it is a reaction to the demo.
Kyle: I’ll take the observation. I’ll tell you, it’s really exciting. And our ability to be able to do this whole lifecycle around AppMod is critical. Right. I mean, point of fact, right, we just extracted a single business service from a COBOL application. So we have a COBOL application now with a tightly coupled, or it’s actually, could be tightly coupled or loosely coupled, but we have a nice well defined Java business service. We actually are experts on our platform of doing mixed language interoperability in the same transaction work so that Java can run right alongside that COBOL inside of an app server, inside of a KICKS app server, inside of a batch environment, because we know how to mix operate mixed language workloads.
James: Is it going to get better? Like there’s a couple of sort of cases where you’re like, hang on a second… Will the model improve so there’s less of that? Or is that more it’s a human in the loop. You’re going to need that. Like, yeah.
Kyle: I’d say it’s both. The model is going to get a heck of a lot better. Like, this model is smarter than it was two weeks ago, smarter than it was two weeks previous to that, and a heck of a lot smarter than it was four months ago. Why? Because we are continually training it with these code pairs so it understands COBOL and Java equivalents in these code pairs. And also, as Husein mentioned, we are training it on our specific mainframe environments as well. It’s not just generic COBOL. Like, anyone can say transform or generate me a merge sort in COBOL.
James: So have you got humans writing the code pairs, then feeding the model with those code pairs, or are you generating code pairs and then… yeah, what is that?
Kyle: It’s both. So we had humans that initially started training the model with writing kind of golden code pairs, identifying over 400 patterns in COBOL, right. And then saying, I’m going to write code pairs for these patterns. But in addition, we have synthetic test generators that’ll take those code pairs and then with all kinds of permutations, generate hundreds of thousands of permutations of each of these different code pairs, because a model only gets better the more and more data that we feed into it. So it’s that, and what we’re feeding into it now is specific knowledge about not just the IMS environment, but the Java SDKs have been around for 20 years that operate within the context of an IMS environment. Same for CICS, same for Db2, same for batch. We’ve had Java on our platform since 1997. We’ve had SDKs for decades now. And this is leaning on those SDKs as well.
James: And so what job is it? Yeah, what version are we running? Like, what control do you have there? Like, some customers are running older versions of Java.
Kyle: Yeah, we’re generating this for the most recent release, Java 17. We obviously have support for Java 11 and even earlier, but we’re training the model largely on Java 17. And that’s important, because we want to bring clients along. From the COBOL perspective, COBOL 6 is the latest version, so the model is largely trained on COBOL 6, but the model also does understand earlier versions of COBOL. So we’ve had clients that have COBOL 4, and they’re using that to help transform that to Java. There are some additional challenges with COBOL 4, but largely COBOL 6 is a superset of everything in COBOL 4. So we can kind of, you know, the model gets a luxury of sort of understanding that path as our clients really do want to get to COBOL 6 as well. If they’re continuing, if COBOL is their strategic direction, they are wanting to get to COBOL 6, but they also want to bring Java into their ecosystem on their platform as well. Even COBOL purists, if you will, COBOL is their strategy. They do want to bring more and more Java workload to the platform in addition to that.
James: Okay, well, I mean, that’s great. A cool demo. Yeah. Not much to say, useful piece of technology. It’s definitely going to be interesting to see how it does in market and, yeah, nothing to say other than Kyle and Husein, thanks very much. That’s another What Is/How To. And you didn’t know you were going to see COBOL generated from an IDE running on a Mac, did you, when you started? I’m saying that to the audience, but perhaps Kyle also for you, that was an interesting one. So there you go. Thanks very much. And that’s another What Is/How To.
Kyle: Have a good one.
Husein: Thank you.
James: Thanks.