Couchbase’s Laurent Doguin (Director, Developer Relation & Strategy) joins RedMonk’s Kelly Fitzpatrick for a discussion on data sprawl: what it is, why it is so ubiquitous these days, and how an integrated data platform can help developers keep it in check. Make sure to stick around for Laurent’s demo, where he updates a Spring Boot app to leverage Couchbase in lieu of MongoDB, Elasticsearch, and Redis.
This was a RedMonk video, sponsored by Couchbase.
Related resources:
- Join the Couchbase community on Discord
- Laurent on the Couchbase blog
- Try Couchbase Capella for free, no credit card required:
- Try the Couchbase live playground
- Code used in the demo
Transcript
Kelly Fitzpatrick: Hello, welcome. This is Kelly Fitzpatrick with RedMonk here with another What is/How to. Today we’ll be talking about data sprawl. With me today is Laurent from Couchbase. Laurent, can you tell us a little bit about who you are and what you do?
Laurent Doguin: Yes. My name is Laurent Doguin. I am from France and can make that very obvious, I live in Paris, and I’m Director of Developer Relation and Strategy at Couchbase, where I basically run the DevRel team and some of the global developer efforts at Couchbase. We are making our company culture a lot more friendlier to developers.
Kelly: Which is what we love to hear. Like, make everything developer friendly, I think, is a good idea. Well, thank you so much for joining me today. A little bit on data sprawl, before we jump in. I know you have a whole bunch of slides that illustrate this concept brilliantly, but data sprawl: this is something that is fairly widespread. It has to do with the fact that in 2023, organizations just have more data than ever before and more varied types of data. But also we’re building apps differently than we were, say, ten years ago. So think of the monolith model where you have this one app and maybe usually one database. Folks have moved on to say microservices architectures, we have mobile applications, there’s different expectations for data at the edge. And we’ve seen this kind of emergence of specialized databases, data stores and tools for different types of data and use cases. And this often means that a single application can be using data from all these different sources. And then when you multiply that by the number of applications that a given organization has, that is data sprawl right there. So one trend we’re seeing in part because of data sprawl is this appetite for integrated platforms. And this is where we end up today. This is the kind of the problem we’re looking at and a potential solution for it. So, Laurent, on to you.
Laurent: Thank you. I guess that’s the first slide. That’s a very overwhelming slide to show you.
Kelly: It is!
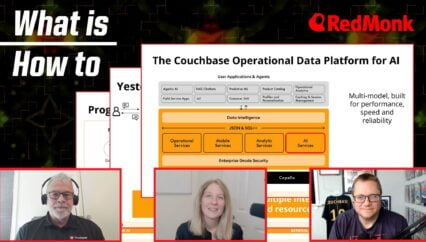
Laurent: Well, something to start with when we talk about data sprawl, is that your query efficiency, the way you get the data out, the efficiency of that is completely tied to how it’s written. And so to get something efficiently, you need to write it the right way. So if you have a graph query, you need to have graph indexes. And if you have SQL data, SQL queries, you need to have SQL indexes, etc., etc., which gives us this whole world of specialized solutions. So here you can see there’s some document database and caching, some SQL, some geo search, full text search, lots of different things. Most of them are data, most of them are data stores that work on prem. This is a very simple slide because there’s a whole world of complexity between the first data layer and your infrastructure and the stuff at the very top, which is your business code and all the middleware in the middle can complexify this even more. So it’s a mess. And you talked about microservices. I’m not sure if it’s a good or a bad idea, but it’s a reality. And this is where we are. And so from the very bottom to the top, it’s all about choosing the right tool for the right job. And so lots of complexity showing up. And so as you can see, a lot of interactions, a lot of arrows going to every service.
Laurent: And actually there’s some arrows missing in there, which is the arrows between all those data stores, which you don’t see here. We’ll talk about it a little later. But that’s also a problem that we don’t talk about. And we don’t talk about who’s managing this. And usually it’s developers because you can manage it for yourself. You can have managed services and managed services and all those on site as well. So you could have a mix of those, which would be — I was going to say it’s going to be bad — it would be more complicated. If you’re –when you talk about digital transformation, it’s not just a marketing word,it has a reality. And if you’re transforming, you need to move that goal data to the cloud. If you’re going to the cloud and you will have at some point, some of those — or on prem, some of those data stores as a service managed. And so you get all the network integration to manage as well. And then once you have moved everything to the cloud, usually on one cloud, because that’s how it works, it’s too expensive to move data from two or more clouds because of egress costs. Then you start adding more middleware on top of that because you start adding more specialized solutions. So it’s even more complicated. And it’s even more complicated for developers because they have to use all those things.
Kelly: They do, not only use all those things, but then figure out which options to use in all of the different categories, which I think brings like a — we talk about complexity, but also, bring over that overabundance of choice, which in some ways is great, but in others I think can be kind of paralyzing.
Laurent: We talk about — I’m not sure if there’s a right word in English, but “charge mentale” would be “mental load” in English.
Kelly: Yes!
Laurent: Which is applied to not necessarily tech, but it applies here. And yeah, just the thought of thinking about this… Is work. The thought of thinking about those interactions is work. It’s not just writing the code. Writing the code is probably the smallest part of this. It’s all the thing that’s around.
Kelly: Yeah, absolutely.
Laurent: That’s overwhelming. And so what do we do as developers is we reach for the higher level of abstraction and we try to consolidate things. That’s usually how it goes. So with all this comes different, classic problems that you might have seen in a classic marketing presentation. Which is, you’re paying for more licenses, you’re paying for more infrastructure, you have to learn all those different tools. You have to manage all those different SDKs, or think about all those interactions. We talk a lot about interaction, about run prices and about license prices. We don’t talk too much about TCO (total cost of ownership) in terms of developer velocity. And I think that’s a problem because as a software company, a huge part of the money you’re spending is probably on developer salaries and licenses. And developers salaries can, you know, you don’t want them to spend some time doing things that could be automated probably, or that doesn’t bring any business value, it’s just a requirement for your business to be running. You want them to write business code. So all that stuff, all those interactions or learning all those different SDKs, it’s stuff that they’re doing that doesn’t bring business value. And so, there must be a solution to manage all of that.
Kelly: One hopes so, because I think it’s not just developer velocity. And we are asking developers to go, I think even faster, and to be more efficient than ever before. But also developer happiness. Nobody wants to spend time on all that other stuff, to your point.
Laurent: I think some developers love to play Lego and they love to — they actually love that part. But it’s not our job. Our job is to make business move forward. You know, to increase our time to market, that decreases sales. Basically what it is, if we ship faster and if we have a better time doing it, then then everybody is happier, right? So how do we do this? I’ve built a small demo for that, a small demo app. It doesn’t showcase every possible data solution you might need, but it does four of those. There’s a CRUD interface, a create read, update, delete document store. There’s the caching part so that everything is in memory so it’s fast. There’s the query. How do you query those documents that you’ve put in that document store? And search. Full text search. And so there’s different ways you could do that. And here are some of the classical architectures you could use to do so. In the middle of the first section, you have a full text search engine, a cache database and a document database, and they are all tied into an event streaming box. So, you know, Kafka, Apache Pulsar, any messaging solution that would allow you to synchronize more or less automatically. The cache, the search index and the document database. Because each time you store something in your document database, you want to update the cache, you want to update the search index so that you can find them.
Laurent: And if you do it manually, that’s the second schemas. So basically every arrow that you see on that schema is, as a developer, I need to think how those two components interact together and probably code something that works with them. And so let’s say I have Kafka and Elasticsearch and Redis and MongoDB, or let’s say because I don’t want to use Kafka because it’s a short demo and it’s a short talk, so let’s forget about this and do everything manually. Let’s take the second example where I have a series of queries in Mongo and I update those manually. So that’s still six interactions, six arrows and three databases. And so what we propose at Couchbase is to reduce as much as possible all those interactions because, well, it’s an all-in-one integrated platform. So the scope of the demo, the flow of the demo, is going to be removing the cache because it’s fully integrated. So now we don’t need to have links between my document service, my CRUD service, and the cache. And once I’ve removed our cache, I can also remove the specific search engine and the interaction I had between the CRUD service and the indexes to make sure they were updated. And so, yes, that’s what we’re going to do.
Kelly: And to clarify, we’re starting out with an app that is using separate document DB search and cache, and you’re doing a migration to what it would be like on Couchbase where everything is all in one.
Laurent: Absolutely. So I’m going to try to rush through this like a crazy person. It’s a Spring Boot Java app. This is the Redis part of things that you can see implements the cache interface. So that’s the box you saw earlier. So cache: you can write in the cache, you can read from the cache, you can update or you can remove something from the cache. CRUD, it’s create, read, update, delete, and so on. Get the query methods and then you get the search method. An important thing about the search part is that you have two different methods to update the index or to well, to add stuff to the index or to remove stuff from the index. And then you have the search method. The point is, I do not need the Redis implementation and the Elasticsearch implementation because I’m going to use Couchbase instead. So I can just delete all the things. And we know that developers love to delete code.
Kelly: The less code, the better. The more code you delete, the more code you can write somewhere else.
Laurent: And the less code you have to maintain. And maintaining has a cost. And so if you’re maintaining more codes that are connecting to more databases, then that’s technically higher cost. I’m also going to remove the Mongo configuration. You can see that it’s basically giving me access to a MongoDB collection, so I will replace it by access to a Couchbase collection. So I’m going to remove that. Goodbye, goodbye. Going to remove the initial setup as well because I don’t need it. And now I need to rename all the things. I’m going to cheat. I’m going to copy and paste my Couchbase configuration because you need to see that. What’s important is how we change the interaction between the different services to show that it’s gone much simpler. So I’m going to rename that to CouchbaseCRUD and that to CouchbaseQuery and that to CouchbaseSearch. Which is the boring part. All right. Now I’m going to go into the CRUD interface that used to be Mongo. Now nothing’s broken because I’ve done things right and I’m using interface and dependency injection, so I still have my interface, but there’s no implementation for that anymore. So let’s actually make sure that it’s properly broken by removing the cache and search service that were available in my CRUD service. Let’s remove the Mongo collection and have a Couchbase collection instead. There we are. And now I’m in a position where I can show you the different interactions between the different services and clean this up.
Laurent: Let’s start by the read function. The read function was going to read something from the cache. So you have to think about that when you are storing documents or reading documents. And then if it wasn’t in the cache, it was going to ask the document database where it is and if it’s there, put it in the cache and if it was already in the cache, it would update the time to live, which is the life duration of the document in the cache. Now all I need to do is basically get rid of all of that and get my content. And so the reason why I need to do that is that Couchbase was, at the beginning,a key-value store, and it has an integrated caching layer, so there’s no need to have an external caching solution. We need to figure out what goes in, how it’s updated. So you can see that I’m removing all the updates from the cache and now it’s removed from the cache.
Laurent: So now I got rid of the cache. I need to also get rid of the search service interaction because of course each time you create something you need to update the full text index. So let’s go ahead and remove that. And so this works because Couchbase has a built-in sort of internal little Kafka–I will show you more afterwards–that updates everything automatically. So more on that later. It’s going to be more or less the same code. Here you can see that with Mongo because Mongo is a document store, not a key-value store, you need to query the document first and then update it. I have to do that here.
Laurent: (I always get mixed up, it’s “replace”, not “update”.) And then remove. And so I’ve successfully removed all the links that I had to external services because Couchbase makes that more simple, because it automates all the things. Now if I go into query and search, I’m not going to show you everything. I’m just going to show you the code. This is the query code that you have from Couchbase basically running a SQL query. It’s not that extraordinary. What’s funny though, is the search code. So first of all, I do not need to implement index and delete because everything’s done automatically. And the second cool thing is that because everything is integrated, instead of querying the full text search index directly because it’s integrated, I can do that from my SQL query. So usually what people do is they query Elastic and then Elastic gives them all the results. And because usually you have security and permissions in the document database, you need to merge the two results to offer proper results. Now, you don’t need to do that. All I can do is use my full text index. So that’s what you see here directly into my SQL query. So that was the demo part. And so at the end you have something like this, which is just Couchbase! Now, the reason this works is because of all the possibilities, all the features that Couchbase as a data platform gives you. So here you’ve seen the caching, you’ve seen the key-value parts, you’ve seen the document parts, you’ve seen some relational SQL parts with the query service.
Laurent: I briefly showed the search service and then there are other things that realtime analytics that eventing. Think of eventing as user defined function. Really, that’s what it is. Triggers. And then there’s a whole other scope about mobile replication, mobile databases and those mobile phones sync automatically to the server, which is pretty cool and pretty useful. Now again, the reason this works, is because of Couchbase architecture. If you remember, one of the first schemas I showed you there was the message service, which would be Kafka in most cases. Here we have something called DCP, the Database Change Protocol, and that’s our own messaging service integrated into Couchbase. And what it does is basically hydrates, updates, all the different services. Because, the way you query stuff depends on the way you store them. We have different services that allow you to store documents differently. So if I put everything into the data service, you can see here that the data service updates the DCP stream and then the DCP stream sends updates to the index service, which is our SQL indexes. The full text service, which is the, you know, full text index I showed you earlier, and then it can do a whole bunch of other things like updating the eventing service. You can create a function, putting some data into other sources like Kafka. If you still really want to do data sprawl, you can do that as well with the platform analytics service. So you know, you can do a little bit of everything. Cluster geo replication between different clusters. Active, active replication. That’s quite cool. Everything works automatically because we have that sort of internal Kafka layer, basically.
Kelly: Yeah. I don’t think I’ve ever hosted a demo where there was more stuff deleted than added, which I thought was very cool. And I think this slide kind of gets at the overall idea of efficiency. So it’s less to maintain, it’s less to think about. There’s so much where the platform is doing stuff for you. So it’s no longer something a developer has to concern themselves with, unless they want to, as you said, do some data sprawl. There’s always a way to bring in some more data complexity if you want.
Laurent: There’s always a use case, a new use case that doesn’t fit the platform like vector databases. We don’t support vector storage right now. I mean, that’s not true. We do a little bit of vector search in Couchbase Lite, the mobile database. But yeah, it’s not the full fledged GPU focused whatever vector stuff for AI yet.
Kelly: Yeah. Well, Laurent, thank you. This has been great. Do you have any last thoughts or if anybody wanted to give Couchbase a try, is there any place that they should go as like a starting point?
Laurent: Yes. So I get this was a very simplified version of what it would be. So if you’re unhappy with that, please bear in mind that this is just a demo, you that are watching this. And then yeah, if you want to try Couchbase, cloud.couchbase.com (free trial, no credit cards required). And if you want to go even faster, we have something called couchbase.live, which is a playground, so it’s just a website. You see the code directly and you can execute the code directly in your browser and so you can use our different SDKs, you can run SQL queries directly. This is also integrated into Couchbase Capella–that’s Database-as-a-Service available on couchbase.com and I will send you the link for the code of the demo as well.
Kelly: Yep. And we’ll put everything in the show notes. So thank you all for joining us today. And Laurent, thank you. This has been great.
Laurent: Thank you.