In this What Is/ How To, Kate Holterhoff, senior analyst at RedMonk, chats with Andrew Betts, principal developer advocate at Fastly, and Dora Militaru, senior software engineer at Fastly. Andrew and Dora share a demo of Fastly Compute, a platform powered by WebAssembly that runs any language and allows developers to rethink application architectures around edge computing. They also discuss Fastly’s developer platform Glitch, KV Store, as well as how Fastly is bringing AI to the edge using machine learning models.
This was a RedMonk video, sponsored by Fastly.
Transcript
Kate Holterhoff
Hello and welcome to this RedMonk What Is How To video. My name is Kate Holterhoff, Senior Analyst at RedMonk, and with me today is Andrew Betts, Principal Developer Advocate at Fastly, and Dora Militaru, Senior Software Engineer at Fastly. Andrew and Dora, thank you so much for joining me. All right, my pleasure. To begin, what does Fastly do and why are you of so much interest to developers today?
Andrew Betts
So Fastly is an edge compute network. You would have previously called us a CDN, content delivery network. And we are known for being a large network of machines that are close to your customers, close to your end users, that you can use to cache content close to where people are consuming it. But today, we are so much more than that. And that’s what we’re here to talk about, because we want developers to use Fastly as part of their applications. We don’t want you to put Fastly in front of your app. We want you to make Fastly part of your app. And we think that there is huge value in doing that, in harnessing this enormously powerful network of machines that we basically put at your disposal.
Dora Militaru
We want you to use something called Fastly Compute.
Andrew Betts
Yes, that’s right. We have this new platform. It is powered by WebAssembly. It runs any language you want. We have SDKs that we provide for Rust, JavaScript, and Go. And we think that this is a really exciting opportunity to rethink application architectures around the use of edge computing. So if you’re just starting a project now. We have free developer accounts and we’d love you to try faster and see how you can fit us into the solution that we’re designing.
Kate Holterhoff
All right. Everyone is excited about AI right now. It’s probably an understatement. So here, Redmonk, I can say that the majority of our research intersects with AI and machine learning, at least in some capacity. Can you explain how the edge factors into these conversations and maybe talk a little bit about how you are using the term edge in this context? Like, how is AI being used at the edge?
Andrew Betts
Sure, absolutely. So AI is, you know, something that everyone is trying to find a way to fit into their applications. So we looked at what people are doing with AI and we thought, what’s the best way for Fastly to help? And I think one of the best ways we can help in a very simple way is to make use of the cache that we have available at the edge. We have this vast amount of storage that we can use. And typically, we will store things by URL. So if somebody requests a web page, we store it.
Next time somebody requests the same web page, we can serve it from the cache that’s local to that user. We thought, well, why can’t we store prompts? We could semantically parse prompts, and we can store AI responses. So if you’re spending a lot of money with OpenAI, for example, then we can reduce that by identifying when users are asking things that other users have asked before and then reusing your OpenAI responses. Can I give you a demo of that?
Kate Holterhoff
I would love to see a demo.
Andrew Betts
Okay, let’s have a look.
Okay, so here I have an app I built on Glitch, which is a lovely platform as part of Fastly that allows you to just experiment and build web apps for free. And I can ask it, for example, how do I purge Fastly from GitHub actions?
So it’s using OpenAI here to read Fastly’s documentation and produce a response that answers this question. And as it finishes, you’ll see that this has actually generated 185 billable tokens. So we had to pay OpenAI to generate that response. Now, if we take this same response, I’m going to refresh to start a new conversation here and ask the same question again. But let’s say I just change a little bit how to purge Fastly from different actions.
The response is generated way faster, and this time is accelerated by fastly and exactly the same number of tokens, but none of those we had to pay for because we were able to use that response from cache. So it’s just simple things like that that we can begin to introduce into your AI solutions and just help to make your AI solutions better.
Kate Holterhoff
That makes a lot of sense. And for folks who maybe aren’t familiar with all of Fastly’s products, what is Glitch?
Andrew Betts
Well, Glitch is a developer platform that allows anyone to just create web applications, whether they be like powered by Node.js or just front-end, sparsely generated sites, maybe with a build process around a framework. And you can host them free. They give you free domains. And it’s a lovely community as well. About 2 million developers make use of Glitch and helping each other, learning, sharing together. Glitch is also one of the most popular places for schools and educational institutions to teach web development. So we’re pretty proud of it. We love having it part of the family.
Kate Holterhoff
Sounds super. Can you talk a bit more about trying it out?
Dora Militaru
You should head over to glitch.com. You don’t even need to have prior knowledge of software development, really. Just pick an example that you like from one of our community examples, click remix and have a go.
Andrew Betts
Glitch is really focused very hard on helping people to get started very quickly. Any existing Glitch application that you like, including the one that I just showed you, you can just click Remix and then you immediately have your own copy of it with a copy of the code and you can go from there. Start coding, changing it, bending it to whatever design you have in your own mind.
And we’ve been trying to do more of that with Fastly as well. So we launched free developer accounts a couple of months ago, and we’re trying to make it as easy as possible for developers to get started with the platform. Can I give you a quick demo of setting up a Fastly app on our Compute platform and show you how easy that is? OK. So here I’m logged into the Fastly web interface, and I’m going to click Create Service, choose Compute.
And I get the choice here immediately of starting something new or bringing my own code. So I might have an existing project that I just want to publish to Fastly, but I’m going to say, use a starter kit. It will immediately generate a domain for me. So I don’t need to bring my own domain, but I can add a domain if I want to. I’m going to accept the existing one. And then I can choose a starter kit. So we provide starter kits for all the languages we support. I’m going to choose the JavaScript one. Finalize and deploy.
And that really is all there is to it in terms of creating a compute service and getting it out into the world. So it’s now deploying and sending the code across the Fastly network. So while that’s happening, I’m going to follow these instructions here to get this set up on my local system. Now, I already have the Fastly ID installed. I know it’s up to date. So I’m going to copy this command here to install a local environment of this compute project. So over here, I have my IDE.
I can paste the command from the WebUI, and that will scaffold out this project. Now, while I’ve been doing that, it has successfully deployed the project to the Edge. So I can click over to here and see that it has deployed to this domain that we created, sharply-viable-heron.edgecompute.app. And I can edit it here on my local system. So I can change it to, say, Welcome to Andrew’s Compute. And save that to do an npm install because this is a JavaScript project. And then once I’ve done that, I can publish it using the Fastly compute. That will recompile my application, create a WASM binary, and then push it to the Fastly platform, which is what it’s doing right now. Uploading package, activating version two. So that will take up to a minute to go live, at which point we should see the change that I made reflected on the live site. Welcome to Andrew’s Compute. Reload, and here we go. Welcome to Andrew’s compute. So I’ve changed the title of the range, and it’s deployed to the Edge. So that’s deployed to every one of Fastly’s hundreds or so data centers around the world and to tens of thousands of machines. And I’m getting this response from my local Fastly Edge data center. So that’s pretty cool. And it is a very quick process to get started and experiment with application at the edge.
Kate Holterhoff
And can we use AI entirely at the edge?
Andrew Betts
Absolutely. So we looked at how to use Fastly to help with using the existing AI service like OpenAI. But of course, this being a general purpose computer platform, you can actually do pretty much whatever you like with it, including building AI features into your application.
So we’ve been experimenting with what we can do with this. And it’s very early days. People are inventing all kinds of different, really wonderful ways of using AI. So we thought we would have a go with a data set that we quite like, which is the New York Metropolitan Museum of Art’s open access data set of their art collection. So if I look at this, if I show you this page, for example, this is a page on the New York metmuseum.org website. And you can see we’re on one of the item pages. If I scroll down, I get some related artworks. These are generated by the Met themselves. But then we’ve injected this extra piece of content here that gives you recommendations powered by your browsing history. So as you browse through metmuseum.org, we’re able to detect what it is that you’re viewing and show you recommendations that are tailored to the path that you’ve taken through the website.
And of course, that’s something we can’t generate into the website ahead of time. It has to be added in a very personalized way. It’s unique to each individual. So this is something that we can insert at the edge while still maintaining the performance of a stuff we generated website. So let’s talk a little bit about how we did this. One of the basic principles of machine learning is that we can take any piece of unstructured data, whether it be an image or a question or a piece of unstructured text, and we can put it through a system which can create an embedding of that content. And what that means is it basically is just a set of numbers. And those numbers describe that content on a set of dimensions. When you think of this a little bit like, say you have a bunch of fruits, and we can plot them on two dimensions of size and color. And then if we came across an unidentified fruit that we don’t know, we can say, OK, well, what other things do we already know about that are a similar size and a similar hue?
And then we can figure out that, this is probably a blueberry or it’s probably a pear. Basic principle of how machine learning creates a way of describing unstructured data. Now, machine learning models are much more complicated than that. And we can’t describe a dimension so succinctly. And also, that has a lot more dimensions. So if you ask a large language model, for example, to embed a prompt or a description, it will give you hundreds of dimensions. So what we did is we took the Met Museum data and we started to think about how we could use a large language model to create a way of generating recommendations based on the previous things that you had viewed on the website. So this is the data that comes straight out of their GitHub. We used it to generate this, which is a set of descriptions, like a single line of text that describes each item. And then…
When we put that through a language model, we can generate a set of embeddings. So for each item, we have an ID and we have a vector, which is a set of numbers on five different dimensions that describes that particular item.
Now, the problem that we have is that the Met’s database is enormous, about half a million items, and we can’t fit all of those items into one edge application. The constraints of what you can do at the edge are very different to what you can do if you have all the resources of GCP or AWS available and you can just set up your own VMs. So we needed to come up with a better solution to that.
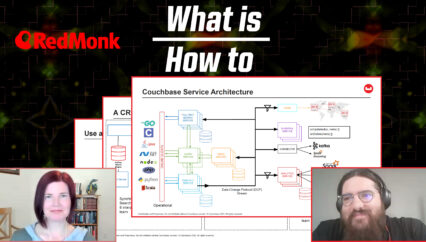
Dora Militaru
There’s a good reason why we don’t have enough space in a compute app to include a search graph of half a million objects. That reason is that you shouldn’t. Fastly compute apps are incredibly performant. If you don’t know what edge computers in general, just imagine traditional serverless compute and take away any concerns about orchestrating deployments, scaling, regional availability. It’s all just global instantly. And there is no cold start time. Now, this is accomplished with a technology called WebAssembly, which is a very small assembly-like language that in and of itself doesn’t do very much. There’s no access to file systems. There’s threads. It’s kind of interesting trying to reason about machine learning in the context of constraining WebAssembly.
We also don’t use infinite memory space, right? This is a shared resource. We want things to be fast consistently for everybody in perpetuity. So there is a ceiling of memory that we don’t use inside a compute application. There’s also a limited package size. The Met museum data set even reduced to those five dimensions. It is still in over 100 megabytes. If you encounter, I don’t know, I don’t have the exact size, but it’s really big. We also want to do code.
Because as an engineer, that’s what excites me. I want to do code that creates some recommendations based on this data. So we’re going to need a different approach here. Now traditionally, you do something called a vector database. So you would ship these embeddings off to a third party. The way that works under the hood is this data would then get sharded. So it gets split up into different shards. And then when you make a query to a vector database, that query is spread across all the shards.
And in principle, that is a good architecture. And that works really well when you have a long running process with many queries that have to spread across the entire corpus. But it’s not so efficient when you have on -demand queries over large data sets where only a part of the data is relevant, as is the case with our recommendations engine. Because if you think about it, the more you visit, you start browsing through these objects your recommendations become more focused. Your interests become more focused. We want to reflect that. And this is one of the cases where edge computing lends itself very, very well to building something performant. So because only part of the data set is relevant, the approach we took is partitioning our data. Imagine that we have
All of these vectors, their mathematical representations of various subjects in the Met Museum’s collection, it doesn’t make sense to me reading it as a user. But I can use various algorithms to partition this data into a set number of partitions. There’s many ways of doing that. We chose something called centroid -based clustering because we wanted to have a predefined number of partitions or clusters to guarantee that any given partition will fit into our compute memory space.
And also we wanted to have a consistent way of representing each group by the average of its data points. That’s called a centroid. So we partitioned this giant data set into 500 partitions. That was an arbitrary number that I chose. You could probably play around with that. But I know that changing to 500 partitions will give me a small amount of memory space, will keep things very zippy. And the next thing we did, was we instantiated and populated search graph. We used Rust to do this. That’s my language of choice. But Andrew rooted in JavaScript. But I use Rust. So we used an algorithm for search graphs called hierarchical navigable small worlds that will give you approximate nearest neighbors. depending on the use case, you use another algorithm that’s still in use for this, we instantiate those graphs.
And then what we did was basically take a memory snapshot and store that into our edge data store, our KV store. So with Fastly Compute, you have access to various stores, config store, secret store, and KV store. And these are globally distributed, very fast, very low latency to put data in, take data out, especially read latency. It’s incredibly low. So it’s really good for us. We pre -compiled all of these search graphs. So imagine having a map, but knowing all the routes in advance.
Andrew Betts
Yeah. So this is the function that actually generates the recommendations when we receive a request. And as Dora’s just explained, basically taking a list of IDs. These are the IDs that you have the objects that you’ve been visiting. We can then figure out like where is the average of those kind of those vectors. You so if we think about like where all of those objects are semantically, what’s the average and then what is around that area in our data set. So the first thing we need to do is find the nearest cluster, like find the central weight that is closest to that target point. And then once we’ve done that, we can find the map for that particular cluster, which we can pull out of KV store, and then we can search it.
Dora Militaru
All of this happens really quickly. We never loaded the entire data set in memory. We zoomed and identified the part that is relevant to us first based on someone’s browsing history, and then we loaded the right search index. And all of this happened really fast. There’s no bloat. It’s all in a matter of microseconds. It’s very efficient and also cost effective.
Andrew Betts
So in doing this demo, we’re not trying to suggest that people sort of follow along with this video and implement this themselves. But what we’re saying is there are lots of different ways you can think about using AI. And we would like people to think about how they can use the edge to power applications that incorporate AI as part of the solution. So, you know, whatever you’re building, whatever kind of solution you’re creating, if it includes elements of Edge Compute, then we’d love to hear about it and we’d love to try and help you use Fastly to do it.
Kate Holterhoff
All right. Now that we’ve talked a little bit about the problem that developers are trying to solve in terms of AI at the Edge, Andrew and Dora, why don’t you walk us through a little bit of the sort of practical example that you showed briefly about the Art Museum website.
Andrew Betts
Sure. So let’s go back to the user experience again. And here we have an object. And down here, you have the related object. So this section of the page that’s related to works, this is inserted by the MET themselves. You’ll notice, by the way, that this is our own domain here. We’re not hijacking their website. We’ve placed a Farsi service in front of metmuseum .org to produce this demo. And then.
These are the recommendations that we’re generating. Now these recommendations will be different if you view this same object page. And that’s because the objects that I viewed prior to this object are different to the ones that you viewed prior to this object. And the other thing that’s interesting here is that as I scroll down, we’re actually adding more and more recommendations. You can kind of see my scroll bar jump as I scroll down. And that just gives you an sense of how quickly we’re able to compute these recommendations and just keep adding them to the page.
We do stop after a because there is a footer and it’s kind of annoying when infinite scrolling pages don’t let you get to the footer of the page. But it just is a nice technology demonstration of how we can solve quite a complex problem and compute something that’s quite complicated and then add that into something that we want to deliver very, very fast. So, in principle, we want the end user to get the page that they’re loading really, really quickly.
We don’t want any element of that page to slow down that experience, especially if it’s an element of the page that the user may not end up engaging with. This was something that I remember from earlier on in my career was a really big problem when things like the Facebook button and the Twitter button started to become popular on sites where everything had a whole big row of social media buttons. And it was slowing down the entire page load, even though those buttons were things people didn’t end up engaging with most of the time. So I think it’s there is obvious value in creating these really high value, really personalized elements of the page. We want those elements to be on the page. We want to generate them really fast. And we don’t want them to detract from the performance of the very best performance that we can get from a statically generated page.
Kate Holterhoff
We are about out of time. But before we do go, do you have any final thoughts to wrap up how Fastly is bringing AI to the edge? And do you have any resources viewers should be checking out if they want to learn more?
Andrew Betts
Yeah, absolutely. So I think the bottom line of what we’re saying is that Edge Compute in general can do everything that a CDN normally would, everything that you’ve kind of come to know and love from CDNs that have made your sites more performant and more reliable, more available. But we can now be a much more integral part of your application architecture and we can do all kinds of interesting things, AI being a really great example.
There is a general purpose compute platform, so you can write whatever you can write in code. You can run on Fastly. We also provide a whole suite of platform services, like our KV store that was part of our AI demo. And those support the code that you can write at the edge. And we’d love to know what you built. So Dora and I are regularly hanging out on community.fastly.com so sign up for a free developer account. Give it a go. If you have any questions or problems, community.fastly.com we are ready and willing to help you.
Kate Holterhoff
All right, I want to thank Andrew and Dora for joining me for this Redmonk What Is How To video. Again, I am Kate Holterhoff, Senior Analyst at Redmonk. If you have enjoyed this conversation, please like, subscribe, and engage with us in the comments.