In this RedMonk What Is – How To video, Kate Holterhoff talks with Mark Gamble and Matthew Groves from Couchbase about why fragmented data stacks break down under agentic workloads and how a unified operational platform changes the equation. They walk through Couchbase’s AI services, model co-location for governance, and the agent catalog for observability and tracing, then demonstrate on-device vector search with Couchbase Lite for edge use cases where sensitive data can never leave the device.
This RedMonk What Is – How To video is sponsored by Couchbase.
Links
Transcript
Kate Holterhoff (00:04)
Hello, my name is Kate Holterhoff and I am delighted to welcome two guests from Couchbase For this Redmonk What Is How To video, where we have experts walk us through a product explaining what it is and how to use it. Mark Gamble is a product and solutions marketing director at Couchbase and Matthew Groves is a DevRel engineer. Mark and Matthew, I’m so excited to have you here.
Mark Gamble (00:27)
Thanks, Kate. Excited to be here. Thanks to you and RedMonk for having us. We’re really excited to talk about today’s topic.
Kate Holterhoff (00:34)
Fantastic. So let’s dive right into the problem you’re trying to solve. We talk a lot about trusting AI, but when we move autonomous agents, the stakes change. How does the definition of a trusted data foundation evolve when the primary consumer of that data is an agent rather than a human?
Mark Gamble (00:54)
Yeah, great question. So topical also, because it’s kind of top of mind. Everybody’s talking agentic.
You know, got back from Google Next, went to the NVIDIA conference. Agents are the big thing, right? But, and for those that don’t know already, agents, agentic applications are apps that can plan and reason and take actions across systems on their own. And trust takes on a really specific meaning here, right? It means the agent will behave nicely and safely and predictably and within the boundaries that, you know, you’ve set within the confines and requirements of your application. So trusted data foundation is what
gives those agents quick, access to the data they need, while also letting you see ideally how they’re using it and how they’re interacting behind the scenes.
So we’ve prepared, of course, I’m in marketing. I’ve got some slides here. But just to illustrate kind of and lead us to the problem of trust and then how Couchbase actually solves it. So this slide sort of captures that fundamental shift that’s happening in the market today. On the left, we’ve got the old world, right? Where we’ve been doing this for the last 20 years. Software as a service. It’s a front end app. It’s tied to a structured database. And the workflows are manual and scripted.
A user clicks a button, the app does a thing, the data layer responds, and it’s very predictable and very deterministic. And then now we, know, fast forward to now or today on the right side, arguably that has shifted from, you know, software as service to service as software.
where the user is still there, but now they’re talking to multi-agent systems. And the agents are pulling from AI models. And critically, the data layer underneath now has to handle both structured and unstructured data faster and more voluminous than ever before, because agents need context. And they need memory. And they need documents and embeddings. And they need it fast to respond as quickly as possible. So the workflows themselves has flipped from scripted and manual to agentic and autonomous.
And that’s the part that breaks the old assumptions, right? Your data architecture was designed for an app that asked one question at a time. And now you’ve got agents that need to reason and retrieve and act and iterate sometimes hundreds of times in a single user interaction, right? And that sort of really changes everything underneath. And when we look at a mental model for where teams are on their AI journey, know, lot of the customers we talk to, right? So if we look at it as a spectrum from simple AI in the
left, more complex AI on the right. Let’s go across that. You know, start with RAG. Most everybody starts their retrieval augmented generation. User asks a question, you retrieve some relevant context from your data, you hand it to the LLM with the question, and it gives you a grounded answer. And that’s where most teams are starting today, and honestly solves a big chunk of real problems.
But then you move into advanced rag where the retrieval gets smarter and you’re doing query rewriting on the fly and re-ranking and maybe combining vector and keyword search and geo search, these kinds of things. And the LLM is being a little more thoughtful about what it pulls. But as we step further right now, you’ve got a single agent and this is where it starts getting interesting, right? The agent can think and take action and observe the result and then decide what to do next. So it’s a loop, not a one shot. And it can call tools.
and call APIs and write to a database. And then on the far right, we’ve increased that exponentially, multi-agentic systems. Now you’ve got several specialized agents that are all collaborating. One might handle research. Another handles writing. Another handles validation. And they’re passing context and data back and forth, sharing memory, coordinating in real time.
And this is what matters for the rest of the conversation, is as you move right on this spectrum, the demands that you start to place on your data layer go way up exponentially, especially to maintain a trustworthy environment and experience. So it’s not linear, it’s exponential.
And this is the picture that a lot of architects look at right now and are probably, you know, panicking. So this is where the architecture that would erode trust. You know, you’ve got your agentic application at the top and on the right, you’ve got your AI ecosystem, your bedrock vertex, external LLMs, et cetera. But then to feed that agent, it’s lifeblood. The data, it’s the stitched together separate system. You know, you’ve got systems for transactional data, separate for
analytics, for vector, for unstructured, for cache. And this was defensible in the old world, but for AI workloads, it’s a mess. You got more complexity. You’re moving data through pipelines that add latency. The architecture is fragmented, and the security surface is way bigger. And maintenance bills will keep going up because you’ve got this polyglot persistence architecture.
And the trust question is really affected here, because you can’t trust what you can’t see end to end. And when the data is so fragmented like this, you really start to erode. And so when people ask why their AI projects feel like they’re moving in molasses, this picture is usually the answer.
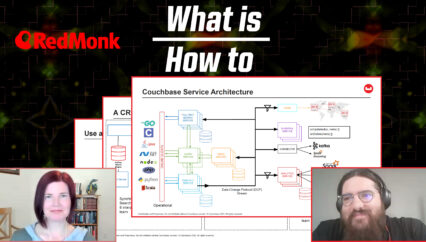
And now we are looking at the alternative. This is what Couchbase proposes, the operational data platform built for AI. And the whole idea here is to bring all of that fragmented functionality together under one unified architecture.
So in the middle here is really the most important parts. We have four unified service areas that work together that do kind of everything we saw that Stitch Together morass does, but all in one platform. Transactional services powered by in-memory key value caching, distributed JSON document storage for persistence, mobile and edge services for data sync at the edge, analytic services, and then AI services are also part of that platform.
where we start getting into answering all of these other questions. The AI services are specifically for agentic development. And this is where the architecture pays off because trust requires models that are secure and governed and agents whose actions are observable, auditable, and steerable. So when your data lives in one unified platform instead of many, this becomes 100 % achievable.
Kate Holterhoff (07:21)
So you mentioned that need to data and tools to be effective, but that exposure is exactly what makes many security teams nervous. How do you grant an agent enough depth to be useful without compromising these data protections and privacy?
Mark Gamble (07:40)
So let’s that great question. Let’s dive in specifically to the AI services box in this depiction here. And this is now we’ve sort of gone inside that box. looking at the individual.
services laid out in a typical process flow for creating and deploying agentic apps. And the most common tasks of building and managing an agentic app, you know, are essentially laid out here. So it’s designed specifically for developing and monitoring these apps. So there are services for pre-processing and vectorizing and preparing data for AI. We see here in the data processing service box. We also have services for co-hosting AI models right alongside the data
database here in the model service box. And then we also have services to call LLMs using SQL, the ability to engage with an LLM with the entirety of your database if you want, and then an agent catalog that records and traces agentic apps. So what I’m going to do is let’s focus on that model service for just a moment through that lens of governance.
And for many of our customers, general purpose public cloud LLMs are risky because they’re not in complete control. There’s latency, privacy, and governance concerns that they have to consider, all which translate to trust. So the couch-based model service solves this by co-locating models with the hosted database. So let’s now take a look at a.
an actual demonstration, right? And we’re in now looking at Couchbase, and this is the model service. And I’m going to now configure my own hosted model. So we offer a ton of model options, both LLM and text embedding. All the ones you would expect is your DeepSeek, Meta, Mistral, Snowflake, and of course, NVIDIA models, including the NVIDIA Nemotron, the big one. And this all runs on NIM containers in Couchbase.
So for this demonstration, I’ll select a DeepSeek Llama LLM to deploy. And it’s really simple now to bring this into a governed and secure environment. First, I’ll give it a simple name. And we’ll go ahead and select our infrastructure.
But advanced configuration is where the real control comes in, because I can configure value-added services on my hosted LLM, like quantization and optimization to shrink and optimize models without sacrificing accuracy.
And then we have guardrails, of course. You can establish your own moderated topics that the LLM will and must not engage in. This is you can really start to govern general behavior for those agentic interactions. And semantic caching allows you to store and reuse LLM responses to prompts based on semantic meaning. And you can even also store conversation threads, which can be picked back up at any time without repeating details. It’s all in an effort to save those valuable tokens. Filtering allows you to exclude words from user
prompts such as competitor brands. And now with all the value added features, all those governors configured, I can deploy the model and now we have a hosted LLM on Couchbase to use with our applications, which is going to make them faster, more private, more trustworthy. And the models are all securely accessed using the model service AI Gateway. It’s an open AI compatible API that’s callable via this endpoint URL. So here in Postman, we decided to test our guardrails
and issue a prompt to the hosted model via the endpoint asking about a guardrail topic and sure enough the guardrails act accordingly they won’t engage on the topic right they’re conforming to my rules so the model service accomplishes a big part of the trust equation you know by providing an integrated fast secure environment for models and data to work together and through this means you know our customers can ensure data privacy is maintained and they can govern model behavior to their requirements.
Kate Holterhoff (11:37)
So one of the biggest hurdles to trust is the unpredictable nature of agentic behavior. I’m interested, how do tools like Agent Catalog or Agent Tracer help organizations to move from crossing their fingers to actually governing and querying agent interactions in real time?
Mark Gamble (11:54)
Totally great question. And I’m going to bring in my colleague, Matt, who develops agentic applications. And as we transition over to Matt sharing, when you store agentic threads and interactions in the database and provide an interface to track them,
can gain observability into the agentic exchange. So let’s turn it over to Matt to actually take a look at what this looks like.
Matthew Groves (12:16)
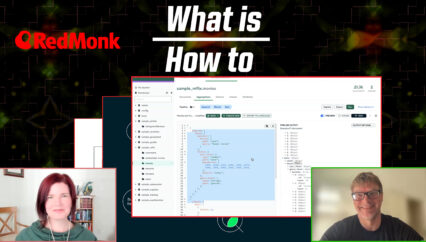
Sure. Thanks, Mark. So what I’ve got here is a demo of an agentic application made for an HR department. Now, agentic apps are going to have to include things like debugging and logging and tracing to help understand what those agents are actually doing. You know, I always think of the metaphor of this call may be monitored for quality control and agents are doing the same sort of stuff. We need to monitor those calls for quality control. So just an example here.
This is a application that is going to collect resumes from applicants and vectorize them for semantic search. So I’m going to just put in a generated resume here. It’s going to get uploaded to Couchbase through the model services and the things that Mark showed. It’s going to be automatically vectorized for that data. So then we can go and put a job description here as a hiring director and see who matches that job description the best from the resumes that we received so far.
This is just using a semantic search or perhaps a deeper agent, you multi-agent type of process. We can browse these candidates here and, here’s Matthew Groves. He looks like a great candidate. Let’s go ahead and send him an email and we can maybe get the scheduling process going for an introductory meeting or interview, things like that. So here’s an example email. I respond and say, I want to share my favorite pizza recipe with you, which is a little strange, right? A little out of the ordinary.
So, you know, what happens in this situation? So with the agent catalog, all these kinds of interactions are stored in couch base and we can then go and review them and say, well, this one looks good, but just some off topic weirdness, some anomalies here, what’s going on? So we can actually get a person into the mix that can see this has been flagged in the system for instance, and get the attention of that person to see what’s going on. Is it an agent hallucinating? Is there something wrong with the guard rails or filters like Mark just showed?
Is the candidate messing with me or misunderstanding the email? So we can pay attention to that. This is the actual agent tracer in CouchPay’s Capella. We can go through and view all the different interactions that the agents are taking place through a data collection, through a date range, the individual agent applications here. And we can view all these to see the detail of what’s going on. for example, here is Natalia Price uploading her resume, getting parsed
agentic application. This is all just data in couch base. Actually, it’s still just data we can query with SQL or AI functions or whatever we need to do to kind of analyze those deeper, interact with them and, do what we need to do as a person. So we’re letting the agents do a lot of the hard work, repetitive work for us and inject humans when, real thought and, manual workflow is necessary. So
The agent catalog and all these AI services here, they’re kind of like the old metaphor of the gold rush. The picks and shovels are what really are used the most in a gold rush. So we’re developing the picks and shovels for AI agentic applications here.
Kate Holterhoff (15:15)
All right. And so when an agent produces an anomalous response, like in your HR app the first always is what went wrong? And how does having the data layer co-located with the model service improve the ability to trace whether that failure was in the tool itself or the prompt or maybe the
Matthew Groves (15:35)
Yeah, so like Mark showed, hosting that model service in Capella, you don’t have to use a model service in Capella, you can use an external one, but hosting it in Capella allows you to add those value added features like the filtering and the guardrails, and those can be changed and improved for your organization as necessary. And it’s going to go into effect, by the way, for all the applications that use that model in your enterprise, as opposed to having that model hosted elsewhere or…
or the guardrails or filters implemented at the individual application level. So, you know, this is kind of an opinion, I guess, but agentic apps, especially the complex multi-agent ones, like we showed earlier, they need to have humans involved in at least some sampling of those responses to provide some sanity checking. And the agent catalog, I think, makes it easier to do that. It makes it easier to govern what’s going on, to monitor the…
what the agents actually generating doing and keep those records in a single place with a known structure and framework
Kate Holterhoff (16:36)
Okay. So, if I were to summarize some of what I’ve been hearing today in this conversation, it’s that trust is often tied to where the data lives. And so, maybe to extend from that, for use cases in healthcare or government where organizations can’t risk sending, you know, private data over the internet, how does performing, vector search and inference directly on device, change that trust equation? for mobile and edge-based agentic applications then.
Mark Gamble (17:05)
Yeah, great question, Kate. And it really comes down to alternatives.
Using a cloud-based LLM introduces all the security and privacy challenges that we’ve been talking about, especially for apps at the edge, where internet can sometimes be problematic. And co-locating models with the data solves a lot of the problem, as we saw. But heavily regulated industries and organizations that manage sensitive data sometimes need to go even further. So the ability to achieve the same thing, but on device, co-located database and model, i.e. store and process
data on device and use it with SLMs that also run on device. This gives you the ability to run agentic apps that work entirely on device. No sensitive data has to leave the edge or the device. The experience then stays secure and private. So how do we actually facilitate that?
We’re now looking at a depiction of Couchbase Lite. This is the on-device edge database in the equation, and it provides native support for iOS, Android, Windows, JavaScript, Java, .NET, all of these things. You can embed the database directly into the code base. And we also have the ability to call local models using the predictive query API. And then we also have vector search on-device, and this makes semantic similarity.
searches in rag applications and agentic apps super fast even without internet. So this ability to power vector search on device and in the cloud and synchronize between is really a unique differentiator for couch-based mobile because other database vendors typically only offer vector search in the cloud where it’s dependent on the internet.
So as our kind of big finish, if you will, we have a little demonstration where we built kind of what does offline inference, secure offline inference at the edge look like on device. So we just have a simple one here depicting vector search for image lookup. And Couchbase Lite on device uses vector search for image recognition. It uses the Apple Core ML AI library on device for vector encoding.
take a look at that. I’ve got it live running right here on screen. And essentially it’s very simple in concept, but what I’ll do is hold up an item and the database actually can see and identify that item. So as I hold up additional items, the database identifies them and displays the associated information. And this applies not only to vegetables and groceries, but to really anything. And what’s happening behind the scenes as we’re doing this is the Couchbase app is a
acquiring the image, vector encoding it using the on-device model, and then running a vector search to find the matching information. And the real key here is that the whole thing happens so fast because we’re not on the internet. It’s all local.
And so, you know, while these are just simple examples, practical applicability here would be for, you know, highly secure type of applications such as, surveillance applications or patient diagnosis apps where privacy is paramount. You know, they can now use visual identification securely on device and sensitive data never has to leave the edge with this particular use case. So kind of a fun little demo to round things out.
So just, it’s a real quick closing as we finish. You know, here’s some customer name dropping to give your listeners a sense of our speed and scale. If you use LinkedIn, you’re using Couchbase.
When you’re enjoying a bag of Flamin’ Hot Cheetos, Frito Lay’s field sales app powered by Couchbase got it to the merchant’s shelf. When you fly Emirates Airlines, the flight crew’s tablet-based apps are all powered by Couchbase. So we power the biggest apps for the biggest companies, and that’s because we’re so flexible and versatile.
Kate Holterhoff (21:02)
Okay, and to wrap up with a call to action, if folks want to learn more, where do you direct them?
Mark Gamble (21:08)
Yeah, go to couchbase.com We’ll have some resources available as part of this broadcast in the comments linked.
Kate Holterhoff (21:16)
Well, I want to thank my guests, Mark Gamble and Matthew Groves from Couchbase, for sharing how they’re thinking about the intersection of trust and data in our agentic era. My name is Kate Holterhoff. If you enjoyed this Redmonk What Is How-To video, please like, subscribe and review.
Mark Gamble (21:32)
Thanks everyone.