I recently had the chance to sit down with Justin Johnson, Director of Developer Experience (and sometimes Product Manager) at Macrometa, to film the above What is/How to video on “What is stateful serverless? How to build real-time distributed applications.”
My sense is that some folks reading this–most likely those who follow serverless trends–will have very intense reactions to the term “stateful serverless,” as indicated by the strong replies to my colleague James’s somewhat recent tweet of the phrase:
stateful serverless
— Grumble Bundle (@monkchips) November 11, 2020
https://twitter.com/RobotTaylor/status/1326570169792040961
Still others may be approaching the term from a “what even is serverless?” perspective. Regardless of where you are starting from, I suggest that you read on (or hit “play” on the video), as there are plenty of definitions and demos to go around.
The Conversation
Because the term “serverless” has been used to describe everything from Functions-as-a-Service to managed services that scale to zero, I made a point to ask Justin how he defined serverless. His reply:
In general, what I mean when I say “serverless” is that someone else is managing the servers and providing a service that you can access without having to worry about any of the stuff going on behind the scenes. Typically, it also means that they’ve prepared for scale. So as you build applications with any sort of serverless technology, you can build it without having to worry about having to scale it as you get more users.
So (of course) servers are involved in serverless, but the point of serverless in this framing is that one does not have to deal with said servers when building an application on serverless technologies. It also certainly does not limit serverless to just functions.
We then moved on to the question of “What is stateful serverless?”, which is in itself a pretty big question considering that earlier incarnations of serverless (especially those limiting the definition to just functions) were stateless. And while serverless architectures, offerings, and definitions are evolving in different ways to address state, Justin prefaces his definition of stateful serverless by stressing the importance of latency:
So for builders, having access to services that are low latency, consistent, and reliable is essential to building good applications. The reason is that low latency provides good experiences for users because your applications are going to be super snappy. And in a lot of cases, like ecommerce, any amount of time or lag you introduce into the checkout process will decrease the amount of money you can make…. Traditional cloud architectures are designed to be hyperscale, meaning they’re going to centralize everything to get economies of scale, bring down the prices, and they’ll often have their data centers out in the middle of nowhere to get cheap land and cheap power. This is great for building applications, but when you have services where you have a user far away from the data center, you end up introducing a ton of latency and creating really slow experiences for those users.
From a business perspective, low latency is essential to preventing poor user experiences and lost revenue. This becomes especially tricky for distributed apps where geography can determine how close users are to both compute and data, and where data changes in one location need to be accessible across the globe as quickly as possible. As Justin notes, Macrometa’s version of stateful serverless is designed to address these issues:
So stateful serverless has three main properties. The main one, the big one, is that everything is globally distributed. So a big part of that is database. So you can query your data as close to users as possible. But another piece of it is that it’s global event processing so that you can track changes in state across the entire network and also do real-time things with that data as it’s happening. When you tie that in with traditional serverless, which is usually compute, these services are so tightly coupled that the latencies that you can get are extremely low. So in the Macrometa platform, you have a globally distributed database of key value documents, store graphs, you have search, there are streams, and then real time data processing.
To make this happen, Macrometa’s platform relies on its Global Data Network (GDN), which is what enables global distribution of both compute and data:
The really important thing to explain here is that global distribution is extremely important. You need all of your data as well as your compute to be as close to users as possible. In the case where you’re using, say, Functions-as-a-Service, you lose all of the benefits of having your compute closer to users when you have to start making round trips back to your data center to access dynamic data. This is the data network for Macrometa.
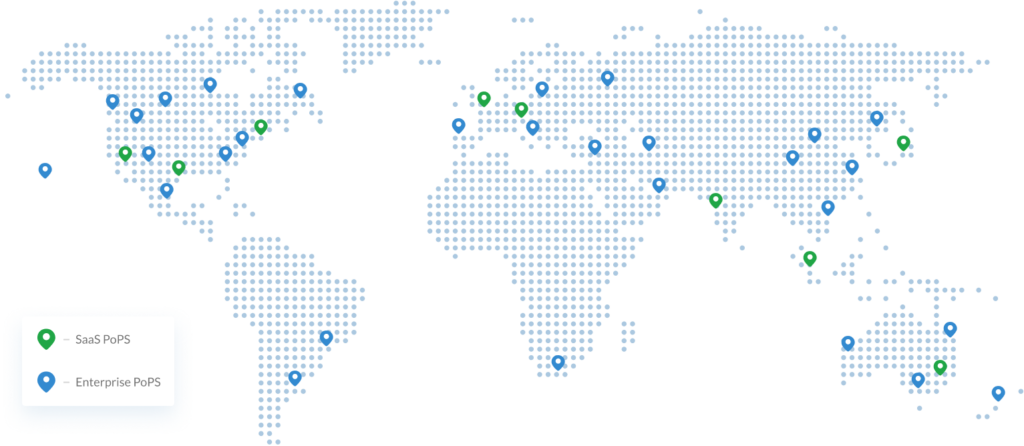
Graphic of Macrometa’s Global Data Network (GDN) detailing various Points of Presence (PoPs)
The Demo
We then switched into demo mode, or the “How to build real-time distributed applications” part of the video. While we had already covered the “distributed” part, I inquired into the “real-time” aspect of the address book application that would get built in the demo. Justin’s reply:
So when we create a collection here, it’s going to get created in this data center and then it’ll automatically get replicated across all of these other locations. I’ll show you that as proof in a bit here. But then at the same time, when I or anyone else adds a new record to the address book, no matter where you are in the world, it’s going to replicate across the entire network really, really quickly. Our P90 for round trip time globally is around 50 milliseconds.
The rest of the video details the build-out of CRUD functionality for the address book app; we then take a quick look at a cryptocurrency exchange app (one of the sample apps you can check out).
It is worth noting that while we started building an app from scratch, you can use Macrometa with other serverless technologies like Amazon Lambda@Edge and CloudFlare Workers, and that Macrometa can also be used as a “side cache” for an existing database.
Related Resources
- Catch up on RedMonk’s new client profile of Macrometa
- Sign up for a free Macrometa dev account and try out Macrometa’s platform (note that Macrometa touts this type of account as “always free”)
- Read the getting started guide (featuring the address book app from the demo)
- Check out the crypto-trading tutorial (one of the sample apps from the demo; includes link to source code on GitHub)
Disclosure: Macrometa is a RedMonk client. The video discussed in this post was sponsored by Macrometa (but this post was not). Amazon Web Services and Cloudflare are also RedMonk clients.

No Comments