This week I’m headed to O’Reilly’s Strata conference in San Jose, which is all about Big Data and more broadly data in general. To get a feel for what’s going to happen there and what the big news is, I repeated my analysis from two years ago and dug through all my pre-announcements to look at the overall themes.
As you might expect, this tends to focus on launches and funded startups vs all companies present or the talks. But it does give a reasonable level of clue as to what the take-homes will be for this year’s attendees, and where they might want to dig into the new hotness in more depth.
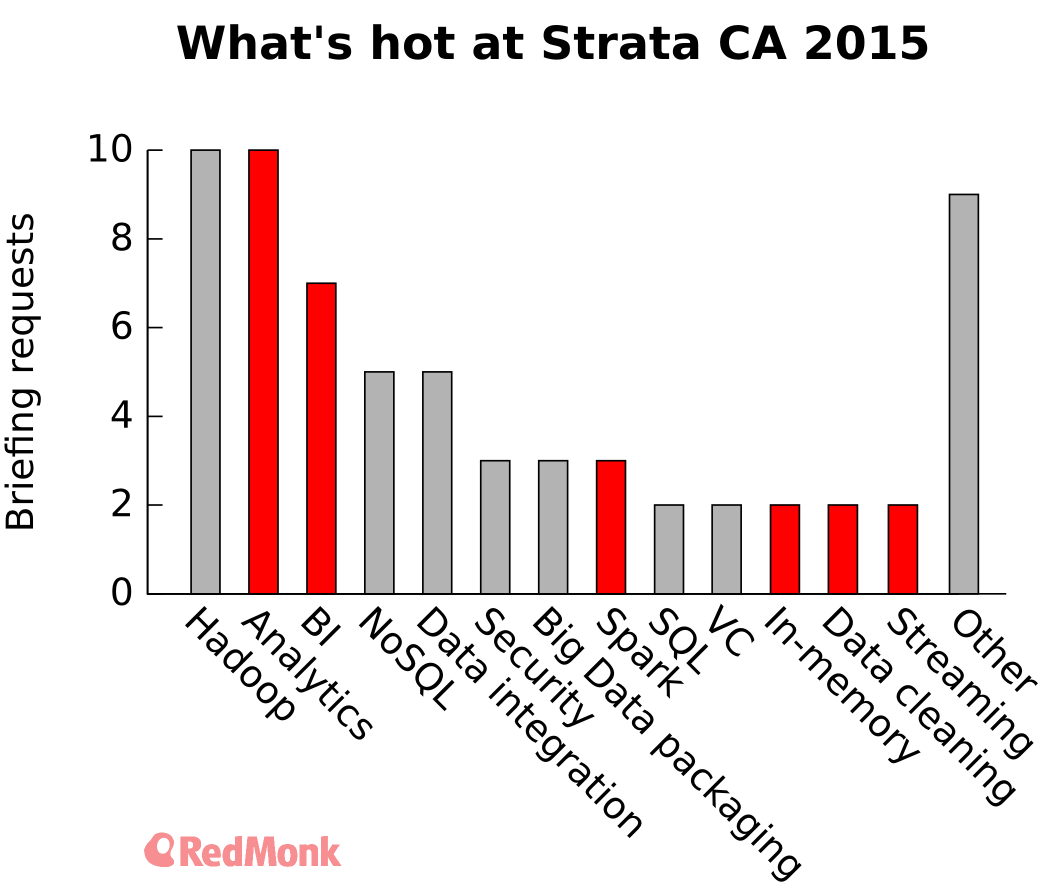
Without further ado, here’s the themes underlying what 48 companies are announcing this year. Note that the numbers add up to more than 48 because I tagged some announcements that fit into multiple areas.

The top 5 areas of interest are:
- Hadoop itself
- Analytics and BI
- NoSQL databases outside the Hadoop ecosystem
- Data integration
- Big Data packaging
I highlighted six areas worth noting in red because of a few reasons:
- The contrast with two years ago;
- They’re a major problem for data users; or
- They’re new, emerging technologies, like Spark.
Two years ago, I received 41 notices rather than 48 so there’s been a slight increase in launches at the show. The primary focuses back then were analytics, databases, and packaging. What’s changed?
The rise of BI (business intelligence)
This year I split analytics into two sections (analytics and the new one, BI), aimed at advanced technical users and business users, respectively. Products and companies that appealed to both were tagged with both rather than artificially segmenting them into one or the other. Together, Analytics/BI was easily the dominant sector with 31% of the overall volume targeting it.
This says a lot about the maturity of the Big Data ecosystem. As it matures, you expect increasingly higher-level applications rather than delivery of raw, low-level building blocks. Analytics tools are about as low-level as shipped apps get, with BI being one level higher because it tends to require more intelligence in the app than in the end user. Farther down the road, look for applications that merely incorporate Big Data rather than being all about analyzing a dataset. Most of them today are heavily customized, but this will change.
To draw an analogy to houses, Hadoop is a bag of ready-mix concrete and some trees. Analytics is cinder blocks, boards, and hand tools; BI is power tools. Horizontal business apps and libraries that are composed into business apps are the contractors building your house. Vertical-specific apps are what the general contractor builds for you, and at scale are built on a common template. As you move up the stack, you lose a little flexibility but you’re able to build upon more and more existing work and expertise.
Packaging is no longer the key blocker
In 2013, the major unappreciated theme was packaging Big Data so it was consumable by end users. That no longer seems to be the case, with packaging dropping down from 2nd to 6th place in the list. This implies that Hadoop has become much easier to get up and running than it was in 2013, which is a key blocker to adoption.
Data cleaning remains underappreciated
Only two companies are pushing products that are primarily about data cleaning, which is generally understood to consume 80%–90% of a data scientist’s time. This to me suggests that either it’s a solved problem (unlikely, given the time expenditure), a problem that’s incredibly difficult to solve, or a problem for which the solution is inexplicably difficult to sell.
What happened to NewSQL?
Companies with new, much faster approaches to traditional RDBMS were all the rage a couple of years ago, but this time around they’ve nearly vanished from the public eye. I’ll be looking to see what their presence is like at the conference, but it seems they don’t have much new to announce at this point.
Emerging tech still emerging (Spark, streaming, in-memory)
Much to my surprise, Spark only showed up 3 times. I would’ve expected at least double the presence of Spark in the announcements as I got. Along with streaming as a whole and in-memory databases, this group formed what I’d call the “emerging tech” category. Although that’s said with a grain of salt, as the technologies themselves have been around for years if not decades, and even a newer streaming option like Storm is now 3.5 years old.
I expect every piece of this area to take off over the next couple of years commercially, as interest within the RedMonk community in these technologies has grown dramatically over the past couple of years. Particularly with the advent of the Internet of Things, streaming technology becomes vital to coping with the data in a timely manner.
Interestingly, in-memory tech has held nearly static, with the exception of Spark. Perhaps that’ll be where the revolution comes from.
(Tangentially, we’re running an IoT developer conf in a few weeks called ThingMonk, in Denver — our first time in the US. Check it out if you want to dig into this!)
Conclusions
To sum up, I expect the growing appeal to the business user via BI and analytics to be among the key takeaways of this Strata conference. Over the next year, especially in the more technologically progressive CA edition, I’ll be looking for increasing uptake of the Berkeley data analytics stack (Spark & friends), streaming tech, and in-memory data processing.
Update [2015/02/17]: Added house analogy.


Joshua Wold says:
February 17, 2015 at 12:59 pm
Thanks for the summary. Also surprised at the low mentions of Spark, streaming, etc.
Donnie Berkholz says:
February 17, 2015 at 2:28 pm
I’d love to run some text analytics against the talk schedule and compare at some point. Problem is that the tagging/categorization is often pretty manual work, and a lot more grueling with the sheer number talks than <50 emails.
Donnie Berkholz says:
February 18, 2015 at 3:24 pm
Someone else did a little bit of that: blog.treasuredata.com/2015/02/17/strataconf-by-the-numbers-as-hadoop-stoops-machines-learn-and-spark/
The emergence of Spark – Donnie Berkholz's Story of Data says:
March 13, 2015 at 4:11 pm
[…] This investigation began while I was sitting at O’Reilly’s Strata conference in a packed Spark talk and began wondering about overall traction and interest in Spark. On a qualitative level, nearly ever talk about Spark at the conference was reportedly packed. This came despite the lack of commercial interest highlighted below, which I wrote more about earlier. […]
hanvi jobs says:
February 26, 2019 at 6:24 am
Thanks for the information. The one thing I have noticed in this website is that you were continuously updating the changes that you have been made. It is a good sign to attract more people and I appreciate it. Hope more update and news from you.
Govt Jobs in Punjab