In the continuing Big Data evolution of reinventing everything that happened in HPC a couple of decades ago (with slight modifications), one newer ecosystem that comes up more and more is the Berkeley Data Analytics Stack. Some of the better-known components of this stack are Spark, Mesos, GraphX, and MLlib.
Spark in particular has gained interest due in part to very fast computation in-memory or on-disk, generally pulling from Hadoop or Cassandra (courtesy of a connector). And its programming model uses Python, Scala, or Java, which — especially in the case of Python — is very friendly to data scientists. Coincidentally, Spark 1.3 was released today, and it supports the DataFrame abstraction used both in the popular Python pandas library as well as in R (for which it has an upcoming API).
This investigation began while I was sitting at O’Reilly’s Strata conference in a packed Spark talk and began wondering about overall traction and interest in Spark. On a qualitative level, nearly every talk about Spark at the conference was reportedly packed. This came despite the lack of commercial interest highlighted below, which I wrote more about earlier.

As you can see, the level of commercial interest was quite low. In concert with the much busier talk schedule and talk attendance, this became quite suggestive of a broader effect. It maps well to the adoption curve followed by many new open-source technologies, where early adopters and contributors dominate the ecosystem initially with talks about the state of the technology and about DIY implementations. This is later followed by vendors coming up to speed in terms of commercial offerings and integrations, which are quite low at present.
To investigate whether this was a wider pattern, I took the approach of pulling in a number of data sources across the development community to compare relative interest in Spark and some other technologies in the Hadoop ecosystem for extracting and operating on data.
The first and most surprising data was from Stack Overflow:

In the past year and a half or less, interest in Spark has skyrocketed from minimal to far above every other technology on the chart. This roughly coincides with, and slightly lags, two major events:
- The project’s move to the Apache foundation; and
- The founding of Databricks, the vendor behind a significant chunk of Spark development.
Although it’s difficult to deconvolute the effects of these two things, it seems likely that they combined to catalyze the growth of the Spark community.
As another data source, let’s examine Hacker News. In general this tends to be a more bleeding-edge crowd, but this data may slightly temper your enthusiasm:

Unlike Stack Overflow, there’s no enormous spike in the last year. Also given the limitations of HN search (words vs tags), some noise like discussion about Spark Devices slips into these queries. While less dramatic than the SO data, there is an equally clear emergence over time from middle of the pack to the dominant technology shown.
It could be that the bleeding-edge crowd here picked up Spark over a longer period of time since mid-2010, while Stack Overflow’s somewhat more conservative audience compressed that same adoption into the past year and a half.
In an attempt to resolve it, I looked at a third data source, Google Trends. This is generally indicative of a broad population that, out of all these, best reflects mass adoption. Queries were coupled with “big data” to limit results to a more accurate subset.

It’s intriguing to see Spark’s emergence echoed again here, with a dramatic-appearing spike just in the past few months. We’ll have to follow it over a longer period of time to determine whether that looks like the Stack Overflow data, but it very clearly stands out beyond the peaks of any of these other technologies.
The next question is how Spark is being used. While difficult to infer, the kind folks at Databricks shared some data with us about the users of the Databricks Cloud: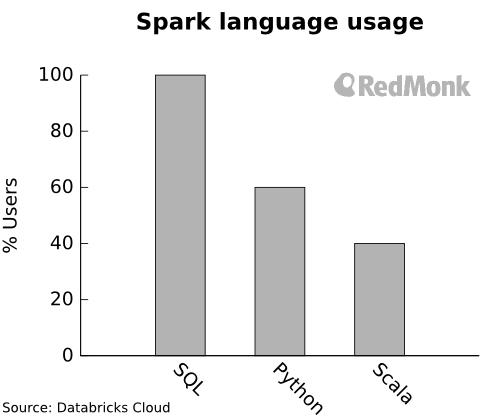
No surprise to see the dominance of SQL. 100% of their customer base uses SQL, often coupled with another language like Python or Scala. Much as my colleague Steve wrote back in 2011, one of the first things added to most NoSQL databases was something that looked a whole lot like SQL. The large usage of Python also supports Spark’s accessibility to data scientists.
Unfortunately the ‘spark’ tag on Stack Overflow is a mess containing both Apache Spark and Flex Spark (part of the old Adobe Flex), so I was unable to take a deeper look at that as another comparison point.
Regardless, it’s clear that Spark is a technology you can’t afford to ignore if you’re looking into modern processing of big datasets.
Disclosure: Databricks, Datastax, and Mesosphere are not clients. A number of Hadoop vendors are clients.


Michael Hausenblas says:
March 14, 2015 at 12:36 am
Thank you for this fine write-up, Donnie and totally agreed! Just to add: Apache Spark is a great (the only?) choice for implementing the λ architecture, that is, combining batch and stream processing in a unified way. See also https://speakerdeck.com/mhausenblas/lambda-architecture-with-apache-spark
Cheers,
Michael
Distilled News | Data Analytics & R says:
March 14, 2015 at 5:06 am
[…] The emergence of Spark In the continuing Big Data evolution of reinventing everything that happened in HPC a couple of decades ago (with slight modifications), one newer ecosystem that comes up more and more is the Berkeley Data Analytics Stack. Some of the better-known components of this stack are Spark, Mesos, GraphX, and MLlib. Spark in particular has gained interest due in part to very fast computation in-memory or on-disk, generally pulling from Hadoop or Cassandra (courtesy of a connector). And its programming model uses Python, Scala, or Java, which — especially in the case of Python — is very friendly to data scientists. Coincidentally, Spark 1.3 was released today, and it supports the DataFrame abstraction used both in the popular Python pandas library as well as in R (for which it has an upcoming API). […]
Big Analytics Roundup (March 16, 2015) | The Big Analytics Blog says:
March 16, 2015 at 8:01 am
[…] RedMonk, Donnie Berkholz summarizes growing awareness and interest in […]
Apache Spark Infrastructure Made Easy | BlueData says:
March 25, 2015 at 9:50 am
[…] hottest open-source project in big data analytics. Red Monk analyst Donnie Berkholz wrote a recent blog post that highlights this skyrocketing growth (see the graph below); he closed by stating “Spark is a […]