The team at Ohloh worked with me to organize a data hackfest at OSCON 2012, and we pulled together a great dataset that included licensing data for all open-source projects in Ohloh that had any commits in the past year. After working with Ohloh data for my recent post on language expressiveness, I wanted to explore it in some different ways to see what else might emerge, and licensing seemed like one worth examining more deeply.
My colleague Steve has posted about permissive vs copyleft licensing a number of times, but we’ve never done quantitative research into licensing choice to prove the extent to which any shifts are happening, the time frames involved, and the potential variations within different programming-language communities.
Approach: Classification, history, and languages
Using the Ohloh data for 57,930 active projects as of July 2012, I classified the top 30 open-source licenses into one of three categories: permissive (e.g. BSD, Apache), limited (e.g. LGPL, MPL, EPL), or copyleft (e.g. GPL, AGPL). This three-category classification accounts for 90+% of all projects with specified licenses, which means it should be representative. The total number of classified projects was 17,549, because a vast number of projects either have no license or Ohloh was unable to detect it. Limited licensing is quite rare, hovering around 2%–3% of projects with licenses, so for the purposes of this post, we will focus on permissive and copyleft licensing.
To attempt to identify historical shifts, I separated projects into buckets based on the date of their first commit. Since license changes between permissive and copyleft are quite rare, this should be a reasonable approach to examining trends over time.
Since I hypothesized that programming language might also play a role, I further split each year’s bucket by language. Here, I’m going to focus on the 11 most popular languages according to our rankings, as well as the total across all languages regardless of popularity. Any data points with 5 or fewer projects between permissive and copyleft are not shown, to remove noise.
Results: A clear trend toward permissiveness
I’m showing the data as a ratio between permissive and copyleft licensing to account for changes in absolute numbers of projects over time. Any number above 1 indicates a bias toward permissive licensing, while any number below one indicates a bias toward copyleft.
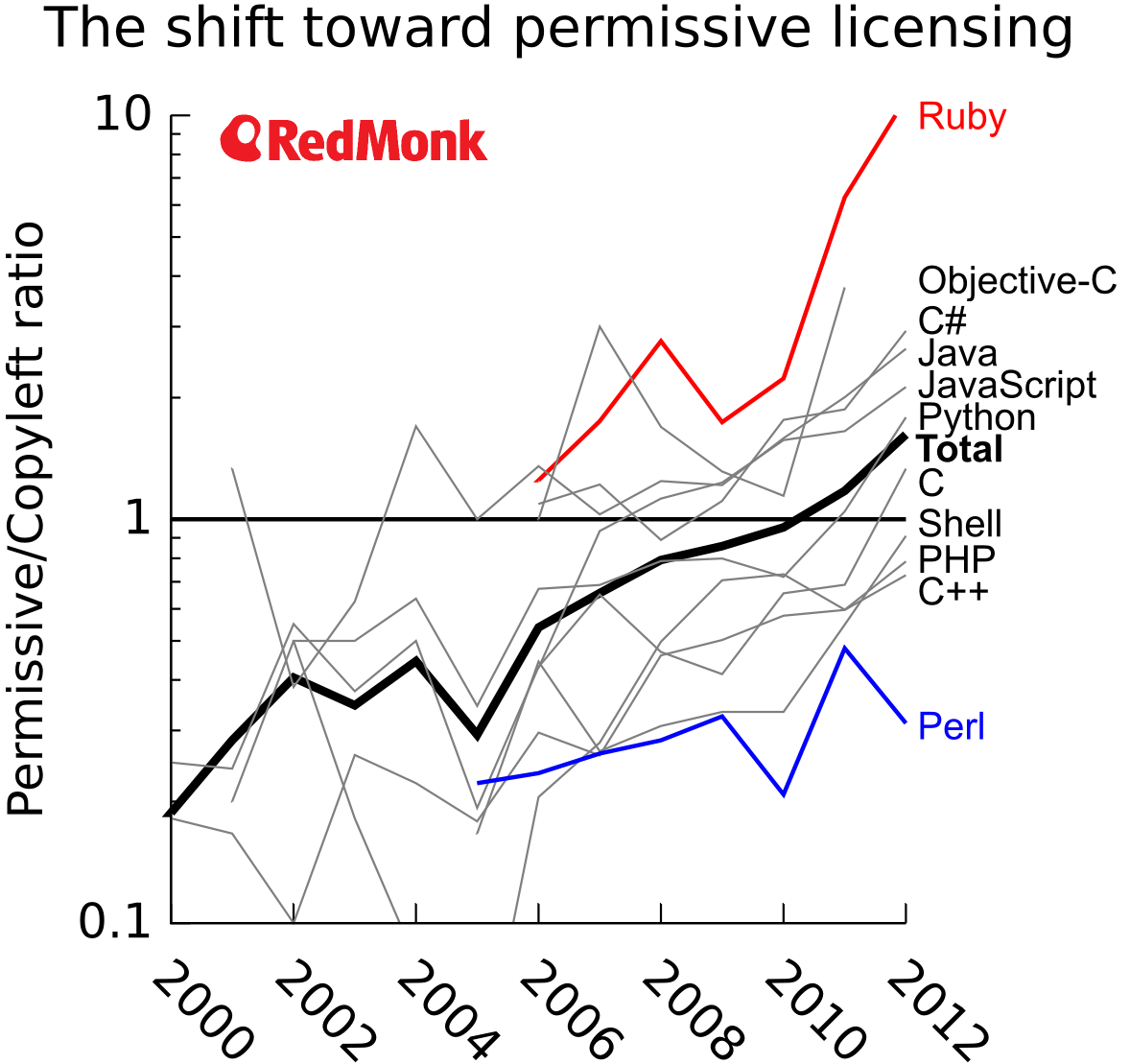
Remarkably, every single language shows an upward trend, starting either in favor of copyleft or near equilibrium and shifting upward in a more permissive direction. The overall total, shown as a thick black line, further supports and clarifies this trend since the individual languages can be rather noisy.
Two languages of particular note are the two extremes: Ruby on the permissive side and Perl on the copyleft side. While most languages cluster relatively tightly, Ruby rises far above them with a very clear and strengthening shift toward permissive licensing — 2x in favor of permissive in 2010, 6x in 2011, and 11x in 2012. At the other extreme, Perl shows a roughly 2x–3x bias in favor of copyleft, which is distinctly below the nearest neighbor, C++, but not nearly as large of a divergence from the primary cluster as Ruby shows.
Other than that, at the level of individual languages, it’s difficult to draw any strong conclusions based on their relative positions because they are much less distinct. More recent web-development languages (Ruby, JavaScript, Python) may bias toward permissiveness, as do languages that tend to be used on closed platforms (Obj-C, C#). The difference between Java, C, and C++ is likely cultural as well, with C and C++ being common in the copyleft community while Java is less so due to inertia from its OSS-unfriendly past.
Conclusions
The shift toward permissive open-source licensing is dramatic over the past decade. Since 2010, this trend has reached a point where permissive is more likely than copyleft for a new open-source project. Although there are language-specific effects, especially in the case of Ruby, the overall movement is clear. Outside the extremes, new projects in even the most copyleft-biased language (C++) in 2012 were given copyleft licenses less than 60% of the time.
Disclosure: Black Duck Software (which owns Ohloh) is a client.


Gordon Haff says:
April 2, 2013 at 1:30 pm
I suspect there’s a lot of culture factoring in here broadly. What’s the norm for the community? There are other factors driving the overall trend, but I suspect the differences in specific languages are cultural to no small degree.
John W Noerenberg II says:
April 3, 2013 at 5:57 pm
What do cultures are you referring to? The norms of particular open source communities?
Andrew Fresh says:
April 3, 2013 at 10:17 pm
What license are all these copyleft perl licenses? The general understanding I have is that “Perl’s license is Artistic 2.0 which is roughly as broad (if not even a tiny bit broader) than BSD’s own?” Which I would imagine should count as a permissive license – http://marc.info/?l=openbsd-misc&m=121172881504598&w=2
Donnie Berkholz says:
April 5, 2013 at 9:51 am
For the relatively small number of multi-licensed projects (765 total out of close to 60,000), I preferred the more copyleft variant — Perl stuff is generally Artistic/GPL dual licensed.
Victor Efimov says:
June 16, 2013 at 4:06 pm
So you treat Perl license (Artistic/GPL) as copyleft?? But this simply does not make any sense. Anyone can use Perl license code as Artistic (less strict)
Alex Libman says:
April 4, 2014 at 8:52 pm
False. http://copyfree.org/rejected/
John Sullivan says:
August 6, 2014 at 5:40 pm
Ohloh is just not a good enough data set. The first two projects I spot-checked a while back had the licenses wrong. Those projects were GNU Bash and GNU Emacs. GNU Bash was on the front page of Ohloh as a “featured proect” — and yet was assigned a license it had never had before in its history. Nobody should be drawing conclusions right now about license use patterns until we have real data sets (and with published methods, no secret Black Duck stuff). We’re working toward that with directory.fsf.org but it’s not there yet either.
For a very different view, see my presentation from FOSDEM in 2011 showing how much different assumptions can change the conclusions: http://faif.us/cast-media/FaiF_0x23_Is-Copyleft-Framed_slides.pdf and http://faif.us/cast/2012/feb/28/0x23/.
RedMonk’s analytical foundations, part 4: 2011–present – Donnie Berkholz's Story of Data says:
April 2, 2015 at 9:51 pm
[…] “Quantifying the shift toward permissive licensing” on the move toward commercialized open source. […]