Is it possible to rank programming languages by their efficiency, or expressiveness? In other words, can you compare how simply you can express a concept in them? One proxy for this is how many lines of code change in each commit. This would provide a view into how expressive each language enables you to be in the same amount of space. Because the number of bugs in code is proportional to the number of source lines, not the number of ideas expressed, a more expressive language is always worth considering for that reason alone (e.g., see Halstead’s complexity measures).
I recently got a hold of a great set of data from Ohloh, which tracks open-source code repositories, on the use of programming languages over time across all of the codebases they track. After validating the data against Ohloh’s own graphs, one of the first things I did was try out my idea on expressiveness of programming languages. Sure enough, it gave me results that made sense and were surprisingly reasonable.
Some caveats to this approach :
- This assumes that commits are generally used to add a single conceptual piece regardless of which language it’s programmed in.
- It won’t tell you how readable the resulting code is (Hello, lambda functions) or how long it takes to write it (APL anyone?), so it’s not a measure of maintainability or productivity.
- Ohloh relies on opt-in subscription from open-source projects rather than crawling forges itself. That said, it’s a vast data set covering some 7.5 million project-months.
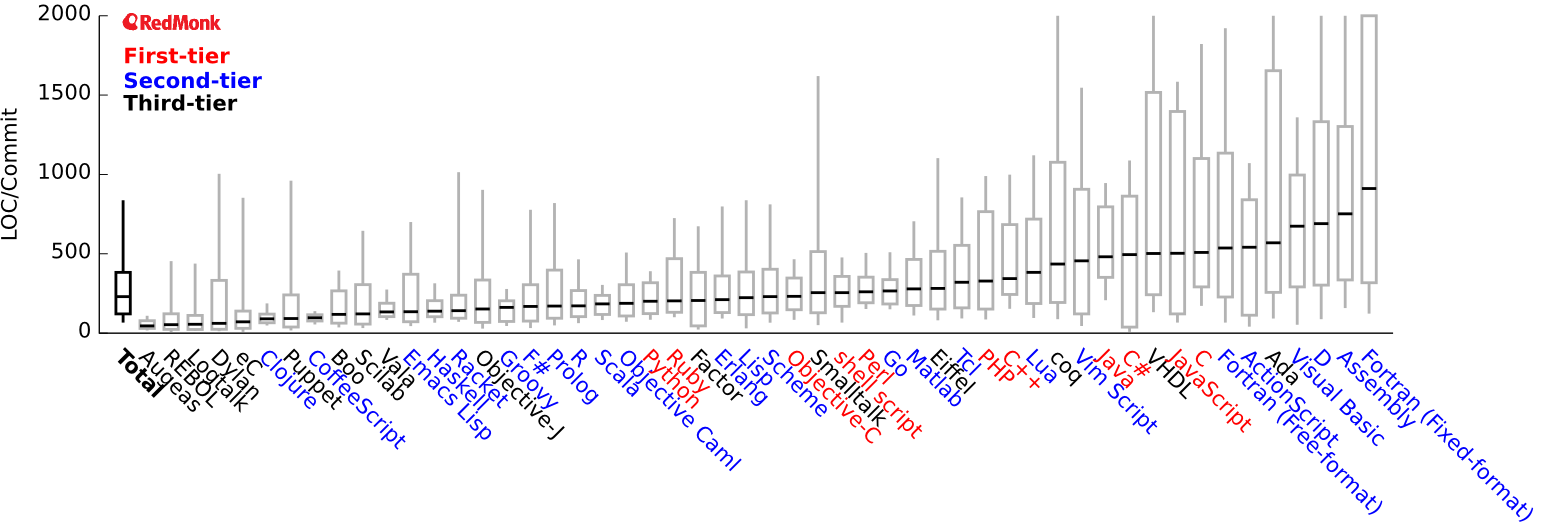
Time to let the results speak for themselves. Enough words, here’s the data (enlarge by clicking):

It’s visualized in the form of box-and-whisker plots, which are effective for showing a distribution of numbers relatively simply. What numbers are we showing? It’s a distribution of lines of code per commit every month for around 20 years, weighted by the number of commits in any given month. The black line in the middle of each box is the median (the 50th percentile) for that language, and languages are ranked by median. The bottom and top of the box are the 25th and 75th percentiles, while the “whiskers” extend to the 10th and 90th percentiles. The “Total” box indicates the median of each value across all languages (median of all 25th percentiles, median of all 75th percentiles, etc.) to show a “typical” language.
I’ve also colored them according to our most recent RedMonk programming language rankings (red is the most popular cluster, and blue is the second-tier cluster, while black is everything else), and restricted languages here to the ones popular enough to be included in that set of rankings.
What conclusions can we draw from this?
Global effects
The trends generally make sense. If we focus purely on the tier-one languages shown in red, high-level languages (Python [#27], Ruby [#34]) lean toward better expressiveness while lower-level languages (C [#50], C++ [#45], Java [#44]) tend toward wordiness. Similarly in tier two, Fortran [#39/#52] and assembly [#49] are wordy, and “middle-aged” functional languages are intermediate while newer functional languages are best.
Expressiveness ranges broadly across languages. The medians go from lows of 48 for Augeas (#1) and 52 for Puppet (#2) to a high of 1629 for fixed-format Fortran (#52), which is a surprisingly large 31x variation.
Less expressive languages tend to show a much wider variability. There’s a clear, but not strong, correlation between the medians (black lines) and the IQRs (box heights). Languages with the largest IQRs also tend to have greater medians, and consistently expressive languages tend to also be more expressive.
First-tier languages are a mix of poor and moderate expressiveness. Of the 11 tier-one languages, 5 are moderately expressive and the remaining 6 are poor. The tier-one languages range from LOC/Commit ratios of 309–1485, which equates to 6x–30x lower expressiveness than the top languages. Perl (#26), the best tier-one language, is 5x more expressive than the worst, JavaScript (#51), and 3.5x more expressive than the classic C. That’s certainly respectable but falls well short of the 20x or greater improvement one could gain with one of the top languages.
Second-tier languages are well-distributed and reach into highly expressive languages. With 52 total languages on this list, the top ~17 constitute the highly expressive languages. Although none of those are first-tier languages, 9 of those 17 are second-tier — mostly functional with the exceptions of Groovy (#16), Prolog (#13), Puppet (#2), and CoffeeScript (#6).
Third-tier languages are heavily biased toward high expressiveness. Of the 15 third-tier languages on this list, 8 are in the top 1/3 of languages, leaving only 7 are in the remaining 2/3. Although these data do not directly show any correlation between age and expressiveness, it seems reasonable that newer, more expressive languages would begin less popular and may grow later.
Effects of language class/type
Functional languages tend to be highly expressive. On this list are Haskell (#10), Erlang (#22), F# (#21), Lisp variants (including Clojure [#7], Emacs Lisp [#14], Dylan [#12], Common Lisp [#23], Scheme [#31], and Racket [#11]), OCaml (#20), R (#17), and Scala (#18). Of those, only two fall below #30 out of the 52 languages included here.
Domain-specific languages are biased toward high expressiveness. Augeas (#1), Puppet (#2), R (#17), and Scilab (#19) are good examples of this, while VHDL (#38) serves as an outlier on the low end.
Compilation does not imply lower expressiveness. I was halfway expecting highly expressive languages to exclude all compiled languages but was proven wrong. Compiled languages in the top 17 include CoffeeScript (#6), Vala (#9), Haskell (#10), and Dylan (#12).
Interactive modes correlate with intermediate expressiveness. Languages with an interactive shell tend to be mid-range in expressiveness, with a few outliers on either side. For example: Lisp (#23), Erlang (#22), F# (#21), OCaml (#20), Perl (#26), Python (#27), R (#17), Ruby (#34), Scala (#18), Scheme (#31).
Specific language effects
CoffeeScript (#6) appears dramatically more expressive than JavaScript (#51), in fact among the best of all languages. Although the general trend is not particularly surprising because that’s the whole point of CoffeeScript, the magnitude of the difference seems unusual. I suspect JavaScript’s low placement could be at least partially due to wholesale copying of template JavaScript files rather than reflecting development in JavaScript itself.
Clojure (#7) is the most expressive of Lisp variants. There are a large number of Lisp variants that generally ranked quite well, described in more detail above in the functional-language section. In this context, it’s worth noting that the top one was the fairly popular Clojure, with a median LOC/commit value of 101, followed by Racket (#11) at 136 and Dylan (#12) at 143.
Among data-analysis languages, R (#17) and Scilab (#19) are most expressive. With a median of 193 LOC/commit for R, it’s a clear top performer. R is followed by Scilab and Matlab (#35) with medians of 225 and 445, respectively.
Although Go (#24) is getting increasingly hot, it’s not outstandingly expressive. We keep hearing about new use of Go across a variety of startups, but it’s little better than Perl (#26) or Python (#27) by this measure. Despite that, it does trump all the tier-one languages, so someone who only had experience with them could certainly see an improvement when trying Go.
What if we sort by consistency of expressiveness, instead of the median?
Ideally a language should be:
- Easy enough to learn that the vast majority of developers using it can be highly productive; and
- Equally expressive across nearly its entire domain of usefulness.
To measure that, let’s take a look at the interquartile range (IQR; the distance between the 25th and 75th percentiles) as a proxy for these two criteria, and rank languages by that instead (enlarge by clicking):

What you’re looking for here is the height of the boxes. It starts small on the left side, with CoffeeScript doing best at 23 lines and increases to the right side, ending with fixed-format Fortran at 1854 lines.
A few new insights specific to this plot before we move on to considering them both together:
- As alluded to earlier but illustrated differently here, inconsistency and wordiness are correlated, as are consistency and expressiveness.
- Tier-one languages put in a much stronger showing here, with four in the top 1/3 of languages (Python at #11, Objective-C at #13, Perl at #15, and C# at #17). Shell nearly makes the cut at #19. Those IQRs vary from 90–167 LOC/commit, a fairly large difference even among the best performers.
- Consequently, tier-three languages make a poorer showing here, although they performed unusually well at levels of expressiveness. They are nearly proportionate with their population with 5 of 15 showing up in the top third, and the remainder are evenly distributed across the moderate and low consistency groups as well.
- Java turns in the strongest performance of “enterprisey” languages (C, C++, Java) when considering both metrics. Java comes in with nearly identical expressiveness as C++ (both at 823 LOC/commit) but a vastly greater consistency (IQR of 277 vs 476).
- CoffeeScript is #1 for consistency, with an IQR spread of only 23 LOC/commit compared to even #4 Clojure at 51 LOC/commit. By the time we’ve gotten to #8 Groovy, we’ve dropped to an IQR of 68 LOC/commit. In other words, CoffeeScript is incredibly consistent across domains and developers in its expressiveness.
- The outliers are particularly interesting — the ones with unusually high or low medians compared to nearby languages. If the median is higher than neighbors, than it’s an unusually consistent yet less expressive language. Conversely if the median is lower than neighbors, then the language is unusually inconsistent (a.k.a. shifted to the right on this graph from the rough correlation between consistency and median expressiveness).
 Tier-one languages tend to be remarkably consistent, regardless of their expressiveness. In nearly all cases, their medians are higher than their neighbors, showing a general shift to the left from the expected placement. This suggests that a primary characteristic of a tier-one language is its predictability, even more so than its productivity.
Tier-one languages tend to be remarkably consistent, regardless of their expressiveness. In nearly all cases, their medians are higher than their neighbors, showing a general shift to the left from the expected placement. This suggests that a primary characteristic of a tier-one language is its predictability, even more so than its productivity.- Conversely, in most cases where languages appear shifted to the right, they’re third-tier languages. The lack of predictability has often held them back from even reaching the second tier.
So, what are the best languages by these metrics?
If you pick the top 10 based on ranking by median and by IQR, then take the intersection of them, here’s what’s left. The median and IQR are listed immediately after the names:
- Augeas (48, 28): A domain-specific languages for configuration files
- Puppet (52, 65): Another DSL for configuration
- REBOL (57, 47): A language designed for distributed computing
- eC (75, 75): Ecere C, a C derivative with object orientation
- CoffeeScript (100, 23): A higher-level language that transcompiles to JavaScript
- Clojure (101, 51): A Lisp dialect for functional, concurrent programming
- Vala (123, 61): An object-oriented language used by GNOME
- Haskell (127, 71): A purely functional, compiled language with strong static typing
Looking at the box plots again, I would tend to rule out eC based on the poor performance of the upward-reaching whiskers at the 90th percentiles, indicating a real lack of consistency as often as a quarter of the time (since the 75th percentile is quite good). I would also rule out Puppet and Augeas because they are DSLs.
Combining those with our RedMonk programming language rankings on popularity, the only highly expressive, general-purpose languages within the top two popularity tiers are:
- Clojure
- CoffeeScript
- Haskell
If you’re considering learning a new language, it would make a lot of sense to put Clojure, CoffeeScript, and Haskell on your list, based on expressiveness and current use in communities we’ve found to be predictive.
No tier-one languages fall in the top 25 on both metrics, although 5 make the cut on consistency alone. Of the tier-one languages, lower-level ones tend to be both inconsistent and overly wordy, while higher-level ones have intermediate wordiness and very strong consistency. The most consistent languages are Python, Objective-C, Perl, C#, and shell, with the presence of Perl and shell supporting the initial assertion that expressiveness has little to do with readability or maintainability. Ruby is an interesting language, in that it violates the “rules” of expressiveness and consistency seen in the other higher-level languages. This could be an instance of a framework (Rails) truly popularizing a language that otherwise would’ve never taken off.
For projects that require an expressive language where it’s relatively easy to hire developers, Python is worth serious consideration. Of tier-one languages, Python, Perl, Shell, and Objective-C are the best overall performers, and I consider Python the strongest of those for general-purpose applications. In my opinion, it makes a lot of sense to take a polyglot approach to projects, writing as high-level as performance requirements allow. Fortunately many high-level languages like Python allow for modules based in more performant languages such as C. That means it’s easily possible to write the vast majority of a project in a more productive, more expressive language while falling back to high-performance languages where needed.
Update (3/26/13): I somehow missed Haskell on the final recommendations for second-tier languages, although it was on the initial list. Thanks to Chad Scherrer for pointing it out in the comments.
Update (3/26/13): I just wrote a post on the last day’s discussion and commentary about what this kind of metric means and what you can get out of it.
Update (3/26/13): I wrote a new post showing correlation of my data with external survey data on what languages developers think are expressive.
Disclosure: Black Duck Software (which runs Ohloh) is a client.


Kevin Marks says:
March 25, 2013 at 4:26 pm
The trend over time would be interesting. “check-ins used to add a single conceptual piece” is a cultural practice programmers learn over time, and was made far easier by changes in source code control techniques. I suspect fortran and javascript being so far to the right reflects a pattern of more novice programmers, who will check in at the end of a project, having copied a lot of code and fiddled around with it locally until it works.
Donnie Berkholz says:
March 25, 2013 at 4:47 pm
Absolutely agree on trends over time. I took forever writing this up, so I wanted to get something out the door even though there’s always more to do. Definitely want to break this data down in a few different ways, and time as a variable is near the top of the list.
Unfortunately there’s a lot of potentially confounding variables, or variables that get averaged out and nuances lost, but I’ve gotta work with the data at hand instead of waiting for something perfect to fall out of the sky into my lap. =)
gstamp says:
March 25, 2013 at 5:35 pm
I like to see hard data but I guess the problem with any exercise like this are the confounding variables. I have a hard time accepting that Javascript is less expressive than Java for example. There are probably reasons why this occurred however those reasons have to be guessed at.
James Iry says:
March 25, 2013 at 5:40 pm
A (probably good) guess: JavaScript is often used by people who are not experienced programmers and who feel more comfortable with copy/paste than with abstraction.
Ruben Verborgh says:
March 26, 2013 at 7:04 am
Above all, this graph says how expressive the programmers working in those languages have been. Only few people writing JavaScript code are able to deal with its expressiveness. This is why Crockford rightly calls JavaScript “the world’s most misunderstood programming language”.
Donnie Berkholz says:
March 26, 2013 at 1:58 pm
I think if you look at the bottom whisker (the 10th percentile), you might be able to get a decent feel for what the top users of a given language are doing. JavaScript could be a weird case where you’d need to go further down, like the top 1 percent.
John Appleby says:
March 25, 2013 at 5:02 pm
I’m struggling here Donnie and I feel this is a set of analytics, looking for a sequitur.
For instance, how do you define the semantics of expressiveness? I’ve programmed in probably 40 different programming languages in my career, of which I’m an expert in none. Those range through many of the different types of language in your list, from procedural (C++) to functional (ML) and high-level (ABAP) to low-level (assembly).
For my money, expressive would mean easy to code something which is easy to understand, reusable and fast. I’m not sure how any of your metrics help here, because they represent only a subsection of code, and aren’t measuring something I think is meaningful.
For instance, if I want to code something fast, which is easy to express, then I will often use perl or python. Curiously those languages have a downside, which is they are difficult to read after the fact, if you want them to be efficient, despite being easy to express a concept.
If you want to really control, then there’s no replacement for C/C++, though I can’t imagine anyone that programs in them describing them as expressive. Every highly-efficient program I have written has been in C.
Whilst describing any functional programming language like ML or Haskell as expressive? If you have a huge brain and can describe things in that way, sure. But then no one else can understand it.
As for C being more expressive than C++, that fails a sanity check. OO brings expressiveness and control.
And as for FORTRAN, yikes.
But in short – I think there is probably some interesting information in the data points you have access too, but I’m not sure it’s in expressiveness of languages. Perhaps instead you should look into why developers commit in this way and in this volume, and what projects they relate to?
Donnie Berkholz says:
March 25, 2013 at 5:43 pm
John, thanks a lot for reading and commenting! I definitely agree with you that there are some huge caveats to what you can get out of this, and you nailed, in very concrete terms, two of the key ones I mentioned: “It won’t tell you how readable the resulting code is (Hello, lambda functions) or how long it takes to write it (APL anyone?), so it’s not a measure of maintainability or productivity.”
I struggled to come up with a good term to describe this — expressiveness was the best of a bad set. So what exactly does this metric tell you? It doesn’t tell you much if anything about the writing or the reading, as you so well described, but rather something about the state of the code in the repository, the development practices in use, potentially the level of bugs you’re likely to get (given the correlation between bugs and LOC). I could imagine it being pretty interesting to look at this kind of statistic across developers or organizations to see what you could learn about how they develop. Do they use small, granular commits or large ones? Does it change when the process for pushing code is painful? Does a high LOC/commit suggest issues with too much autogenerated code being committed?
Expressiveness of languages ranked | Smash Company says:
March 25, 2013 at 7:07 pm
[…] Clojure ranks #7 […]
newz2000 says:
March 25, 2013 at 10:34 pm
I know and use several of the languages there and I think that Javascript might be a bit of an outlier. I wonder if this is because many projects include pre-packaged libraries like jQuery in their source code. Whenever they update a library it makes a huge impact on their delta. Also, many web-focused projects minify their Javascript which can wreck havoc on an automated analysis tool.
While I do think this is an interesting metric, I wonder how valuable expressiveness is in recommending a language. I think that it impacts the learnability, but I’d probably suggest to people to shop their local job market or talk to a recruiter long before using this. Neither Clojure nor Coffeescript will get your foot in the door in my area.
Donnie Berkholz says:
March 26, 2013 at 10:08 am
Exactly. That’s the point I made in the post, although it was kind of buried in the middle.
Expressiveness is just one measure, as you say. I’d love to see if I can find ways to get at data for the barrier to entry, the maintainability, the coding speed to complete similar problems, etc.
Matt Watson says:
March 25, 2013 at 10:50 pm
Also have to think about how much code is auto generated. In C# ORM and web service references generate lots of code that would inflate these numbers.
Ben Racine says:
March 26, 2013 at 1:39 am
Perhaps rosettacode would be a better place to look given that these are problems where the same exact problem is being solved by each language? Having casually studied that site though, it seems like your results would match well to me.
Roland Bouman says:
March 26, 2013 at 4:46 am
Interesting excercise, with – for me – rather unexpected results.
It makes me wonder to what extent the chosen metric is indicative of expressivity.
One thing that wasn’t clear to me is how “the interquartile range (IQR; the distance between the 25th and 75th percentiles)” can be seen as a metric for consistency.
Another thing that stood out is that the “most expressive” languages by this metric are relatively obscure or at least not widely adopted. It made me wonder whether it’s possible that those languages are programmed by a relatively small number of programmers that know exactly what they are doing. In that case, this would be more of a measurement of expressiveness of programmers than of programming languages.
Donnie Berkholz says:
March 26, 2013 at 10:06 am
The IQR is a way to look at the width of the core distribution without being overly affected by outliers. The difference between the 10th and 90th percentiles would be another slightly less robust way to do the same thing. This width is essentially a single number to describe how variable the LOC/commit values are for a given language, which should be a view into use of the language across many problem domains and many developers. If the width is small, it should be both a generally applicable language (general to its entire “domain” in the case that it’s a DSL) and a language that’s used fairly well by at least half of its developers.
I also noticed the higher ranking of relatively unpopular languages. Let’s take a second-tier languages like CoffeeScript, for example, which was used by 391 developers across 200 projects in February. That’s relatively small but not exactly a tiny group of super-leet coders. Third-tier languages, on the other hand, are absolutely subject to your point. Vala was used by 87 developers, but there are some that are an order of magnitude lower: REBOL was used by 5 developers, Augeas by 8, eC by 9, etc.
Roland Bouman says:
March 26, 2013 at 11:09 am
Thanks! This clears it up 🙂
Marc Greiner says:
March 26, 2013 at 5:23 am
You seem to have found a funny way to randomly sort programming languages.
Old Skool is still cool says:
March 26, 2013 at 12:04 pm
Agreed! I wonder, hasn’t the author ever heard of Function Points? People are under the mistaken impression that they’re for ancient mainframe-style apps, but they’re commonly used in industry to reliably estimate project size. The thing is, Capers Jones and the SPR has for years comparitively ranked languages by the number of SLOCs required per average unit of functionality, as an indicator of productivity. This all used to be common knowledge.
It became very clear that at a given skill level, VB.Net and Java were twice as productive as VB, which was about 20% more productive than C++, which was about 100% more productive than C, which was 3x as productive as MASM.
Then again, back in the day, real programmers also knew how to write and evaluate their own sorting algorithms and understood the value of metrics like Cyclomatic Complexity.
thejambi says:
March 26, 2013 at 7:20 am
Vala is pretty cool 🙂
Justin says:
March 26, 2013 at 7:48 am
I commented this elsewhere, but I think pairwise comparisons reveal the limitations of this method. If you take very similar languages, they should have similar scores if this method works. But I doubt it–are Scheme and Racket highly different in expressiveness? They shouldn’t be, since Racket is PLT Scheme.
Another raised eyebrow is the rather significant difference between Python and Ruby. Lots of people have strong feelings towards one of the pair (I’m a Python guy), but it’s generally admitted that they’re very similar. Why do they appear so different in your presentation? Another pair that I know less about is D/C++, but I have the same concerns.
Another artifact: Emacs Lisp almost certainly has a low LOC per commit ratio because it is heavily used for hacking Emacs, which leads to lots of little helper functions.
My general thought is: this list jives with my preconceptions in most cases, but seems very very noisy.
Donnie Berkholz says:
March 26, 2013 at 9:54 am
There’s definitely a fair amount of noise in the metric, but very few major outliers (i.e. ones that are *way* out of place, rather than just a few spots).
The expressiveness of a language, in practical use, is a convolution of many variables including the language characteristics themselves, the standard library and ecosystem, the “culture” built around the language (is it one that encourages copying of external libraries, for example), etc. And you obviously nailed the fact that DSLs are special cases. I would be very curious what kinds of differences not at the syntax level, but otherwise, might be present in the Racket/Scheme instance. Any thoughts?
Justin says:
March 28, 2013 at 7:42 am
I’m not familiar enough to appraise Scheme/Racket. I know they’re close, but I’ve never really touched Racket enough to know if there might be a big difference in APIs/libraries that drives different coding patterns.
Rob Grainger says:
March 26, 2013 at 8:53 am
“One proxy for this is how many lines of code change in each commit”
Can you provide any evidence that your assumption is correct? Sounds like a Straw Man hypotheses to me.
Surely if a language is sufficiently expressive, code would not need to change so much.
Donnie Berkholz says:
March 26, 2013 at 10:11 am
That was basically the hypothesis going in: can we measure things this way? The results seem to bear out that it broadly works. That said, it’s clearly an imperfect, somewhat noisy metric that’s actually measuring a number of factors that combine to form the expressiveness in practice rather than in theory.
In the News: 2013-03-26 | Klaus' Korner says:
March 26, 2013 at 8:58 am
[…] Programming News: Programming languages ranked by expressiveness Is it possible to rank programming languages by their efficiency, or expressiveness? In other words, can you compare how simply you can express a concept in them? One proxy for this is how many lines of code change in each commit. This would provide a view into how expressive each language enables you to be in the same amount of space. Because the number of bugs in code is proportional to the number of source lines, not the number of ideas expressed, a more expressive language is always worth considering for that reason alone (e.g., see Halstead’s complexity measures). Read full story => RedMonk […]
Danny Price says:
March 26, 2013 at 9:00 am
This reminds me of those quarterly poles that declare C as the most popular programming language based on the number of C-related web searches.
These poles don’t consider the fact that programming anything non-trivial in C is a lot of work so it’s only natural that people will hit the web in search of answers, inflating it’s ‘popularity’.
Programming languages are tools and you use the right one for the job. You wouldn’t use CoffeScript for a high-performance rendering engine no matter how expressive it is.
Donnie Berkholz says:
March 26, 2013 at 9:50 am
You might be interested in checking out my colleague Steve’s correlation of actual use on GitHub with conversation on Stack Overflow: http://redmonk.com/sogrady/2013/02/28/language-rankings-1-13/
Tomalak Geret'kal says:
March 26, 2013 at 11:06 am
What do either Polish people or long metal sticks have to do with anything here?
Donnie Berkholz says:
March 26, 2013 at 11:39 am
Very little, although geographic poles might be a better fit.
Thomas Marshall (Tom) Olsen says:
March 26, 2013 at 9:07 am
Pity you didn’t include APL, invented by Ken Iverson at Harvard, championed by IBM. I used it for 25 years until I retired
Donnie Berkholz says:
March 26, 2013 at 2:25 pm
Apparently it isn’t too popular in open source. =)
Thomas Marshall (Tom) Olsen says:
March 26, 2013 at 6:00 pm
Perhaps the most successful vendor today is Dyalog, Ltd., but they require a monthly fee, not practical for casual users. A friend recommended NARS2000, freeware but I haven’t tried it yet. IBM still offers an APL2 for $2,120 to run under Windows or Linux
Bob C. says:
March 27, 2013 at 2:45 am
APL is one of the great languages IBM never marketed! Used it for years on VM/CMS (another great OS that IBM never marketed)!
M. Edward (Ed) Borasky says:
March 27, 2013 at 11:55 am
Actually, it was heavily used on Wall Street as APL360; IBM sold quite a few timesharing systems with the magic APL Selectric terminals. Gradually it died out – most of the finance folks use Mathematica, R or Matlab now. There’s still a dialect of APL in use called ‘K’, which I believe is open source.
Bob C. says:
July 18, 2013 at 1:24 am
There is also a slightly earlier variant called J (then came K!). J was developed by Iverson and Hui back in the early 90s and is a synthesis of APL, FL and FP. It is suited more for mathematical and statistical programming. It is also FOSS and under the GPLv3 license. Check out the wiki.
Bob C. says:
July 18, 2013 at 1:10 am
I downloaded and tried NARS2000. It is sort of neat. It helps to have a good size screen (I have a 20″ monitor). It starts off with a clear WS and above it, there is a string of the APL character set plus some that are new to me. Point the cursor at one and click on it. When you hover over it, it also displays a “tool tip” which briefly describes the function and a keyboard (combo) key that can be used. You do get an introductory Copyright message with instructions on how to suppress it.
Ben Evans says:
May 4, 2013 at 7:28 pm
http://www.aplusdev.org/ – a GPL language related to APL created by Morgan Stanley
Steven Kelly says:
March 26, 2013 at 9:33 am
Correction: Programming Languages Ranked by Size of Commit
rodrigo says:
March 26, 2013 at 11:17 am
NO DELPHI? NO PASCAL?
Chad Scherrer says:
March 26, 2013 at 11:17 am
Haskell is in the top ten by both metrics, but you don’t include it in your list of “best languages by these metrics”.
Donnie Berkholz says:
March 26, 2013 at 12:49 pm
Thanks! Fixing now. Must’ve had a typo when I entered the sets.
Chris Parnin says:
March 26, 2013 at 1:36 pm
At least normalize the commits by the size of the project. You may be observing that certain languages are used for different size projects.
Donnie Berkholz says:
March 26, 2013 at 2:24 pm
Unfortunately I’m rather limited by available data (and time) on improving some of this. If only I were still in academia and had more time to devote!
What I’ve got is total # of projects, committers, commits, and loc_changed by language on a monthly resolution for about 20 years.
What does “expressiveness” via LOC per commit measure in practice? – Donnie Berkholz's Story of Data says:
March 26, 2013 at 1:47 pm
[…] post ranking the “expressiveness” of programming languages was quite popular. It got more than 30,000 readers in the first 24 hours; it’s at 31,302 as I […]
Adrian Kuhn says:
March 26, 2013 at 2:01 pm
“One proxy for [expressiveness of a language] is how many lines of code change in each commit”
Hmm …
I see many social and behavioral signals affecting commit size, but not expressiveness of the language.
There’s a plethora of social signals affecting commit size, in particular across languages. Language communities have different cultures. So might value small commits, while other language communities might have a habbit of only commiting ever so often. Or, of committing small commits to a local feature branch and them merging the feature in one huge commit into the public repository!
Another example are behavioral signals causes by different best practices across language communities. For example, some language communities are much more invested in ad-hoc code reuse, so large pieces of code are copied from one code base to another, or from the internet.
Also language communities differ by how they package libraries. In some communities it can be quite common to copy paste libraries into a project. Hence leading to huge commits.
Also the edit behavior is largely dependent on tools. In languages with refactoring support we can expect engineers to touch much more code at once because tools enable them to do so without fear. Which again leads to larger commits.
None the factors above are dependent on technical aspects of the language, their are all contextual, depending on factors such as culture and tooling.
Donnie Berkholz says:
March 26, 2013 at 2:13 pm
Yeah, some of that is related to what I coincidentally published in a follow-up post about 20 minutes ago: http://redmonk.com/dberkholz/2013/03/26/what-does-expressiveness-via-loc-per-commit-measure-in-practice/
Do you think the behavioral differences should reasonably be expected to apply to entire classes of languages, like functional programming? I would expect larger-scale trends across multiple languages to be more resistant to some of the points you mention.
The tooling/IDE point is a great one, and I heard that from another expert in the field although their point pertained more to productivity while you’re making a great argument for committing differences as well.
Adrian Kuhn says:
March 26, 2013 at 2:34 pm
Hmm, even languages that are technically very similar can have quite opposing cultures. Take for example Python and Ruby, which both boast the same meta-programming feature, but while it is not considers pythonic to use them, if you leverage Ruby’s meta-programming you’re a rockstar.
Ben Racine says:
March 26, 2013 at 3:23 pm
Thank you for this Donnie… there’s an awful lot of negativity on this page considering you spent your free time to run this study.
Ben Racine says:
March 26, 2013 at 4:07 pm
A relevant public opinion poll http://hammerprinciple.com/therighttool/statements/this-language-is-expressive
Some external validation on expressive languages – Donnie Berkholz's Story of Data says:
March 26, 2013 at 4:55 pm
[…] and relevant data source by Ben Racine and wanted to post a short update to note the correlation of my post with a new piece of external […]
ChadF says:
March 26, 2013 at 6:07 pm
The interesting thing I noticed was Javascript and ActionScript didn’t have closely matching results. After all, aren’t these both essentially EMCAScript with different runtime environments (i.e. classes/functions available) and goals? So syntax wise they should be about the same and only really differ on how they are used.
Donnie Berkholz says:
March 26, 2013 at 8:02 pm
Yep, definitely. Probably worth checking out http://redmonk.com/dberkholz/2013/03/26/what-does-expressiveness-via-loc-per-commit-measure-in-practice/ if you haven’t already.
M. Edward (Ed) Borasky says:
March 26, 2013 at 8:58 pm
I don’t understand why CoffeeScript scores so high on expressiveness. I think that’s an artifact of there being so little code written in CoffeeScript; it’s an *extremely* young language. Nor do I understand why there’s such a huge gap between Matlab and Scilab; they’re very similar, as is Octave. Both Octave and SciLab were deliberately designed to be low-cost alternatives to Matlab.
Donnie Berkholz says:
March 26, 2013 at 9:30 pm
It could be due to some of the things I discuss in more detail here: http://redmonk.com/dberkholz/2013/03/26/what-does-expressiveness-via-loc-per-commit-measure-in-practice/
Chris Fotopoulos says:
March 27, 2013 at 10:17 am
Where is COBOL ?
Donnie Berkholz says:
March 27, 2013 at 10:53 am
Like APL, COBOL isn’t popular enough in open-source software to make the cut for this list (based on http://redmonk.com/sogrady/2013/02/28/language-rankings-1-13/). In fact it’s not in Ohloh either.
Aaron Bohannon says:
March 27, 2013 at 12:53 pm
This was absolutely fascinating. FWIW, I would have chosen to describe the metric as “conciseness” rather than expressiveness. Its literal meaning is about the same, but it seems like a less loaded term.
There are some factors that might be nice to eliminate from the metric. For instance, did you exclude blank lines and comments? Also, if you’re counting lines of code, then line length is a factor. I would even advocate factoring out the length of variable names, and simply counting the number of syntactic tokens in each commit. I don’t want to call that a more “accurate” metric because some people might genuinely care about the space the code takes up on the screen. However, a token-based metric is certain to be less influenced by the conventions of a language culture. It is also a metric that would take a lot more work to measure. 🙂
When counting lines of code, it is no surprise that Lisp-like languages made a strong showing, given their minimal syntax. They also have no static type system, which is another very interesting factor to me. Any static type system will require some amount of type annotation, and that will have an impact on conciseness. If it were possible to identify which tokens were purely for the sake of type annotation, then comparing the metrics with and without those tokens included would be very interesting.
One last thought/critique: I’m not convinced that you measured “consistency” in the right way. I would probably have measured the width of the distributions in a manner that was proportional to the median. That would place JavaScript as one of the most consistent and Prolog as one of the most inconsistent.
Jeremy List says:
May 10, 2014 at 4:42 am
Static type systems don’t necessarily have an annotation burden: sometimes type inference is sufficient. While Haskell has type annotations: it’s possible to write reasonably large programs without using them.
BillStewart2012 says:
March 27, 2013 at 4:22 pm
Any attempt at measuring expressiveness is going to be stuck with fuzziness and subjectivity, so thanks for finding some way to at least partially nail the jello to the wall.
One of the difficulties is that many of these languages are going to select for different kinds of programmers. The people I know who are doing Coffeescript and Haskell tend to be scary-brilliant academic types, so I’d expect their code to be terser than the average Joe Web Designer’s.
Fortran programmers, on the other hand, are typically not interested in the programming aspects; it’s much more of a domain-specific language for physicists and chemists, who are writing code to model physical or mathematical processes. They don’t get their expressiveness from the language – they get it from collecting a bunch of data and marshalling it to hand to subroutines other people have written decades ago, or by rewriting those subroutines to adapt them for different but similar physical processes. (Though yeah, marshalling input for subroutines is a lot more annoying in Fortran than it is in C or really anything but assembler or maybe Cobol.)
Ada programmers, when I last dealt with them, tended to work in huge top-down waterfall development processes in unmanageably large teams for the military aircraft market. (That’s probably less true three decades later, especially in open source.) The language is designed to nail down interfaces between modules and force you to do most of the design upfront, so you can then let different teams write their own modules and review them to make sure they conform to the interfaces and maybe even work, and there was a mixture of new code from thick paper requirements documents and translation of existing messes of poorly documented Jovial, assembler, and Fortran. It’s an ugly environment.
Dave Neary says:
March 27, 2013 at 4:54 pm
Is it possible that the SLOC/commit measure is smaller for domain specific languages like Augeas & Puppet because you can do so little with them?
Charles Ferentchak says:
March 28, 2013 at 8:34 am
Did you take the time to remove comments out of the files when you were counting commits. Did you include things like YAML or XML config files that were added?
Even lines of code is a tricky thing to count.
That being said I am not sure LOC /commit is a good metric for expressiveness since different languages may have systematic differences in commit style. For example when a language is new tons of people want to check it out and thus create a ton of small “hello world” and my three line webserver programs.
There will be far less programs of that simplicity in a language like C. For a more complex project “one unit of value” would be much more code.
Gorgi Kosev says:
March 28, 2013 at 5:42 pm
You forget that an expressive language can be used in an un-expressive manner. Good developers tend to produce succinct and elegant code using the full range of features of the language. Code of average developers is significantly more verbose. Bad developers sometimes produce mountains of copy-pasta.
This explains the abnormally huge disparity between CoffeeScript and JavaScript, which excluding some small amount of sugar are essentially the same language. (Another possibility adding to this is code-generation – there is a lot of generated JavaScript these days).
Still, the experiment is an interesting start. The next step would be to take the number of developers into account and to model the probability of a developer using a particular language being above/below average
Coastal Africa: an up-and-coming force in software – Donnie Berkholz's Story of Data says:
March 29, 2013 at 9:57 am
[…] I was digging through Google Trends to check on some geographic trends related to my post ranking expressive languages, I came across intriguing data about Africa. It turns out that the eastern and western African […]
Sebastian Dietrich says:
March 30, 2013 at 9:11 am
What such comparisons usualy forget is that some programming languages come with frameworks and some can rely on thousands of open source frameworks. Neither the LOCs nor function points nor “expressiveness” of the language matter when most of the functionality I need in my application does not need to be coded, but can be found in already available software.
Links & reads for 2013 Week 13 | Martin's Weekly Curations says:
March 31, 2013 at 5:13 pm
[…] Programming languages ranked by expressiveness […]
Quantifying the shift toward permissive licensing – Donnie Berkholz's Story of Data says:
April 2, 2013 at 12:51 pm
[…] in Ohloh that had any commits in the past year. After working with Ohloh data for my recent post on language expressiveness, I wanted to explore it in some different ways to see what else might emerge, and licensing seemed […]
Roundup for many things says:
April 5, 2013 at 11:55 am
[…] CoffeScript appears to be much more expressive language then JavaScript, at least in this programming languages expressiveness ranking. Well, on the other hand JavaScript has its overapi own page and there are no signs of Coffee […]
Magiel Bruntink says:
April 16, 2013 at 2:55 am
Hi Donny,
Thanks for your article! I have a question about the data collection process: How did you obtain the monthly LOC per commit numbers? Did you divide the total monthly LOC added for a project by the total monthly number of commits? Or are you able to get data on the individual commits and get the LOC added from those?
I’m asking because, like you, I’m excited by the sheer amount of data offered by Ohloh, and am working on an analytics project as well. I can’t seem to get fine-grained access to commits using the API, however.
Best regards,
Magiel Bruntink
University of Amsterdam
Donnie Berkholz says:
April 16, 2013 at 1:35 pm
The data I used is aggregated across all projects in each language on a monthly level — it’s just the data behind the graphs at https://www.ohloh.net/languages/compare/ and I got it directly from them.
But yeah, even via the API you’re stuck at a monthly level (at least for activity_facts and size_facts).
Magiel Bruntink says:
April 17, 2013 at 12:33 am
Hi Donny, sorry but I still don’t really understand how you got at the metrics. Did you, given a language, divide the total LOC added monthly by the total number of commits monthly? Or did you have data on individual commits and aggregated those? I’m asking mainly because of worries that the LOC / commit metric within a language is not normally distributed, and hence an arithmetic mean would not represent the central tendency very well.
Magiel
tjholowaychuk says:
April 25, 2013 at 10:20 am
These results are horribly incorrect IMO
schiffbruechige says:
April 26, 2013 at 4:57 am
I liked your post.. but was a little sad about the ending.. first “the presence of Perl and shell supporting the initial assertion that expressiveness has little to do with readability or maintainability. ” – what’s this based on? Where is the evidence that Perl/Shell are less readable/maintainable.. Then you concluded Python, also based on.. what you prefer.
It’s a shame that a post all about data ends with “and I prefer X”.
My First Tangle With the Tower of Babel | Codecraft says:
April 26, 2013 at 9:48 am
[…] Programming languages ranked by expressiveness or popularity (redmonk.com) […]
Tela says:
May 10, 2013 at 12:37 pm
Thanks for the article. I liked it 🙂
“One proxy for [expressiveness of a language] is how many lines of code change in each commit”
Can you tell how the number of changed LOC is calculated? Is it just the number of new lines or is it calculated in some more complex way?
Are we getting better at designing programming languages? – Donnie Berkholz's Story of Data says:
July 23, 2013 at 9:35 am
[…] the aftermath of my earlier work on the expressiveness of programming languages, I started whether our ability to design and choose optimal languages might have improved since the […]
Guest says:
July 24, 2013 at 8:52 am
Productivity (immediate and maintenance) is the ultimate metric. Pick a function point or Agile story and see which one gets done faster…assuming you can ever design a controlled experiment in terms of talent and experience.
What were developers reading on my blog and tweetstream in 2013? – Donnie Berkholz's Story of Data says:
January 6, 2014 at 9:19 am
[…] 63681: Programming languages ranked by expressiveness […]
A Bright Future for Tornado and Motor | JoshAust.in says:
February 1, 2014 at 11:29 am
[…] or as I prefer to call them, developer cycles. One of the main reasons we use Python is for the expressiveness of the language. In my experience we can ship more features that our customers want, more quickly […]
notchent says:
March 30, 2014 at 7:24 am
I’ve been using Rebol for more than a decade, and couldn’t agree more. I have never found any other general language or development tool which is more expressive or productive.
Expressive languages and whiteboard coding | Eat, work, sleep says:
April 20, 2014 at 8:43 pm
[…] Berkholz crunched the data and tried to come up with a metric for the expressiveness of programming languages. Without […]
TeaPartyCitizen says:
July 7, 2014 at 10:10 pm
This study needs to be weighed by the age of the programming language because there is a huge amount of fortran code being maintained by professeurs who are not modern day computer scientist. Who do not know how to organize their code so that changes do not have to be sweeping. These guys had no idea of object oriented programming. Fortran and OOP is an oxymoron aamof.
Donnie Berkholz says:
July 7, 2014 at 10:36 pm
It would be very interesting to try to map equivalent development timeframes. You run into challenges of what “equivalent” means though. In the life of the language and its module ecosystem? In chronological time (external development methodologies)? In individual apps?
And yes I agree with you that people have greatly differing levels of training in software engineering, particularly in scientific programming but also other areas such as Visual Basic.
jonquimbly says:
November 26, 2014 at 1:30 am
This “analysis” is pure voodoo. Disraeli-Twain applies.
“[Can] you compare how simply you can express a concept in [a language by observing how] many lines of code change in each commit?”
Without some form of static code analysis, you have no earthly idea what’s going on inside those source files, do you? Your analysis here is like reading pig entrails to forecast the weather, mate.
You aren’t using any objective or well-regarded metrics for determining language expressiveness. Instead, you’re erroneously linked unrelated data to expressiveness. You could’ve done the right thing, scientifically, by trying to disprove your hypothesis, but instead you double down and march forth assuming not only is all correct, but that any statement you make is true.
The scary part is, this article has been cited! It’s been quoted as a “study!” You’re spreading pseudoscientific, objectively wrong conclusions about programming languages.
That your byline contains “PhD” means it’s being delivered, most unfortunately, to readers who might not have the knowledge or experience to understand what they’re reading, thereby potentially reaching a disadvantageous conclusion about development costs.
You aren’t a C.S., but now you’ve poked your head into the arena. If you’re going to leave this nonsense live on the web, you should at least have the bollocks to submit it to a peer-reviewed PL journal, to give it the proper arse-kicking it deserves.
“results that made sense and were surprisingly reasonable”
Your confirmation bias runs like a leaky fountain pen.
“The trends generally make sense. If we focus purely on the tier-one languages shown in red, high-level languages (Python [#27], Ruby [#34]) lean toward better expressiveness while lower-level languages (C [#50], C++ [#45], Java [#44]) tend toward wordiness.”
You extensively cite another dataset (language popularity tiers) to confirm your hypothesis and biases. But it’s just as absurd to use popularity as correlative of language expressiveness as it is LOC/commits.
As for your implicit bias, pro a subset of languages: Python, for example, was designed with avoidance of overly-dense/complex expressions and statements in mind. C’s expression-statement duality allows much denser code than Python, yet you have ranked C as the third worst offender! Ridiculous.
“CoffeeScript (#6) appears dramatically more expressive than JavaScript (#51), in fact among the best of all languages. Although the general trend is not particularly surprising because that’s the whole point of CoffeeScript”
Now you’ve dispensed with confirmation bias and gone straight to promotion. CoffeeScript enthusiasts hawk the language as “more expressive than JavaScript” but clearly haven’t any idea what that means. The term ‘expressive’ has abused into meaninglessness in the CoffeeScript context.
CoffeeScript’s design was driven by language esthetics that reduced its expressive possibilities relative to JavaScript — similar to how Python was driven by its designers’ objections to Perl, Java and other language designs, and ended up with a partly esthetic design.
CoffeeScript is not the union of the two languages, instead it’s its own language that renders to JavaScript. It is a replacement, not an evolution, and intentionally much more limited.
I could go on, but why bother? I urge you to remove this post, it will misguide people looking for objective, unbiased info on programming languages.
Maciej Ligenza says:
March 2, 2015 at 9:55 am
Donnie, any chance you can perform the same analysis on the data as of today? There are shifts in language usage but its quite reasonable to expect the results remain the same (my gut feeling is that language “expressiveness” does not change in time). That would give us some insight into real value/nature of the data gathered.
[quotes to denote problems with choosing a proper word]
sinta maharani says:
May 7, 2015 at 2:45 am
I prefer more support javascript due to crystal x herbal
SmackMacDougal says:
June 14, 2015 at 10:51 pm
Learn REBOL because Red will be ready for action soon enough.
It’s weird how the writer of the foregoing work ignored his own results. What is left after tossing out that DSLs, Puppet and Augeas, but REBOL, which supports DSLs along with the Internet.
Good luck!
davsms says:
September 21, 2015 at 8:29 pm
Hello, is there a way we can get the graphics in a vertical style? I’d really like to use them in a project but they would look better in a vertical way.
Thank you!
Donnie Berkholz says:
November 18, 2015 at 6:40 pm
I’d recommend rotating in your image editor of choice and re-typing.
pay for essay says:
November 18, 2015 at 8:26 am
This is actually correct and many people may also found some wonderful information on how you were able to explain those things and create a good page that explains about it.
Steve Shogren says:
January 23, 2016 at 5:11 pm
I really like your post, you might like mine! http://deliberate-software.com/safety-rank-part-2/