I recently had the chance to chat with Couchbase’s Laurent Doguin on “What is Data Sprawl? How to Leverage a Platform to Wrangle it.” Discussions about data sprawl often focus on the sheer amounts of data that organizations create as well as the plethora of locations where that data is stored or used. However, as increasing numbers of types of data come into play along with specialized tools to go with it (looking at you, vector databases), data sprawl also proves challenging for developers navigating this landscape as they build and maintain applications.
In other words, as one of Laurent’s slides sums up, when we talk about data sprawl, we should also consider challenges such as platform and tool navigation and maintenance, integration issues, skills and training gaps, and increasing complexity of making all these moving pieces work together.
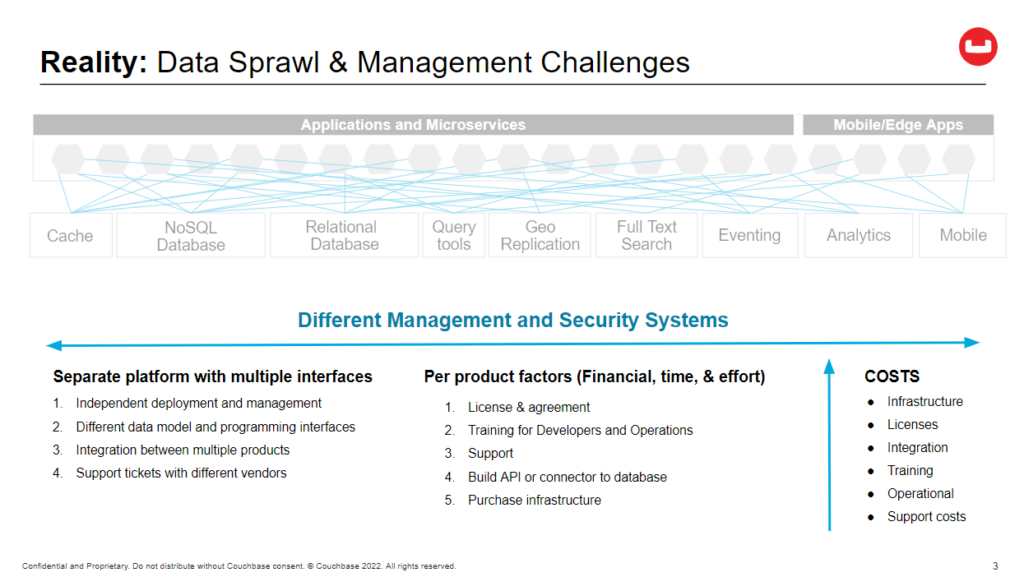
It is worth noting that you can tell that Laurent has a developer-friendly perspective, as he begins by framing this all in terms of query efficiency. He notes:
Well, something to start with when we talk about data sprawl, is that your query efficiency, the way you get the data out, the efficiency of that is completely tied to how it’s written. And so to get something efficiently, you need to write it the right way. So if you have a graph query, you need to have graph indexes. And if you have SQL data, SQL queries, you need to have SQL indexes, etc., etc., which gives us this whole world of specialized solutions. So here [in the slide] you can see there’s some document database and caching, some SQL, some geo search, full text search, lots of different things. Most of them are data, most of them are data stores that work on prem. This is a very simple slide because there’s a whole world of complexity between the first data layer and your infrastructure and the stuff at the very top, which is your business code and all the middleware in the middle can complexify this even more. So it’s a mess.
As Laurent points out, it is often developers who are tasked with managing this mess, which becomes even more complex with microservice architectures thrown into the mix:
And you talked about microservices. I’m not sure if it’s a good or a bad idea, but it’s a reality. And this is where we are. And so from the very bottom to the top, it’s all about choosing the right tool for the right job. And so lots of complexity showing up. And so as you can see, a lot of interactions, a lot of arrows going to every service. And actually there’s some arrows missing in there, which is the arrows between all those data stores, which you don’t see here.
Notably, what Laurent describes is not just an issue of data sprawl, but also one of tool sprawl. In this database-specific manifestation of the developer experience gap, developers must learn not only how to incorporate numerous specialized data stores into their applications, but also how to keep these separate pieces working together throughout the lifecycle of the application.
It is perhaps no surprise, then, that one trend RedMonk has seen is the emergence of more general purpose data platforms that integrate specialized functionality into a somewhat more coherent developer experience. It does not hurt that this also helps cut down on the number of separate technologies that an organization must support.
Watch the full video below for more on our conversation on data sprawl or see the full transcript and related links. Also included: Laurent’s demo in which he updates a Spring Boot app to leverage Couchbase in lieu of separate document DB, search, and cache solutions. Or, as Laurent puts it:
Warning: it contains a very opinionated Couchbase demo
Disclaimer: The video discussed here was sponsored by Couchbase (but this post was not).

No Comments