While it’s been almost eighteen months since the OSI released its open source AI definition, the debate around where, whether and how open source licenses might be applied to AI models continues. The view here remains unchanged, which is that open source should not be applied to AI, but the industry more broadly has not yet reached a consensus.
Unless and until that occurs, then, it is useful to understand how open source licenses are being applied to models and in what proportions. To do this, inspired by a conversation on this subject yesterday, the approximately ~2.9M existing Hugging Face models were scanned for license information. There are some interesting takeaways from the data, but first it is worth noting that there are inherent issues with it.
- First, this analysis cannot account for licensing issues like an illegally licensed project. There are models, for example, that apply an Apache license but trained using Llama. That is not permissible, as you may not convey rights you yourself do not have – particularly if you’re performing actions a given license specifically and explicitly prohibits. This analysis would consider the project Apache-licensed, when in reality that license cannot not be applied.
-
Second, this analysis can’t meaningfully discuss every one of the new licenses here, some of which were written by professionals and some of which were self-evidently not. Given the scale, it cannot guarantee that there are no falsely categorized licenses. The some Kimi and Mistral projects, for example, use a “Modified MIT License,” but the modifications make the project neither open source nor MIT. The good news is that projects using this license are typically categorized as “Other,” and are therefore properly not counted as open source here. The bad news is that we can’t guarantee that there might not be exceptions.
-
Lastly, as will be discussed in more detail shortly, there is a rather large hole in the data.
With those warnings out of the way, we’ll start with the Top 20 licenses on Hugging Face.
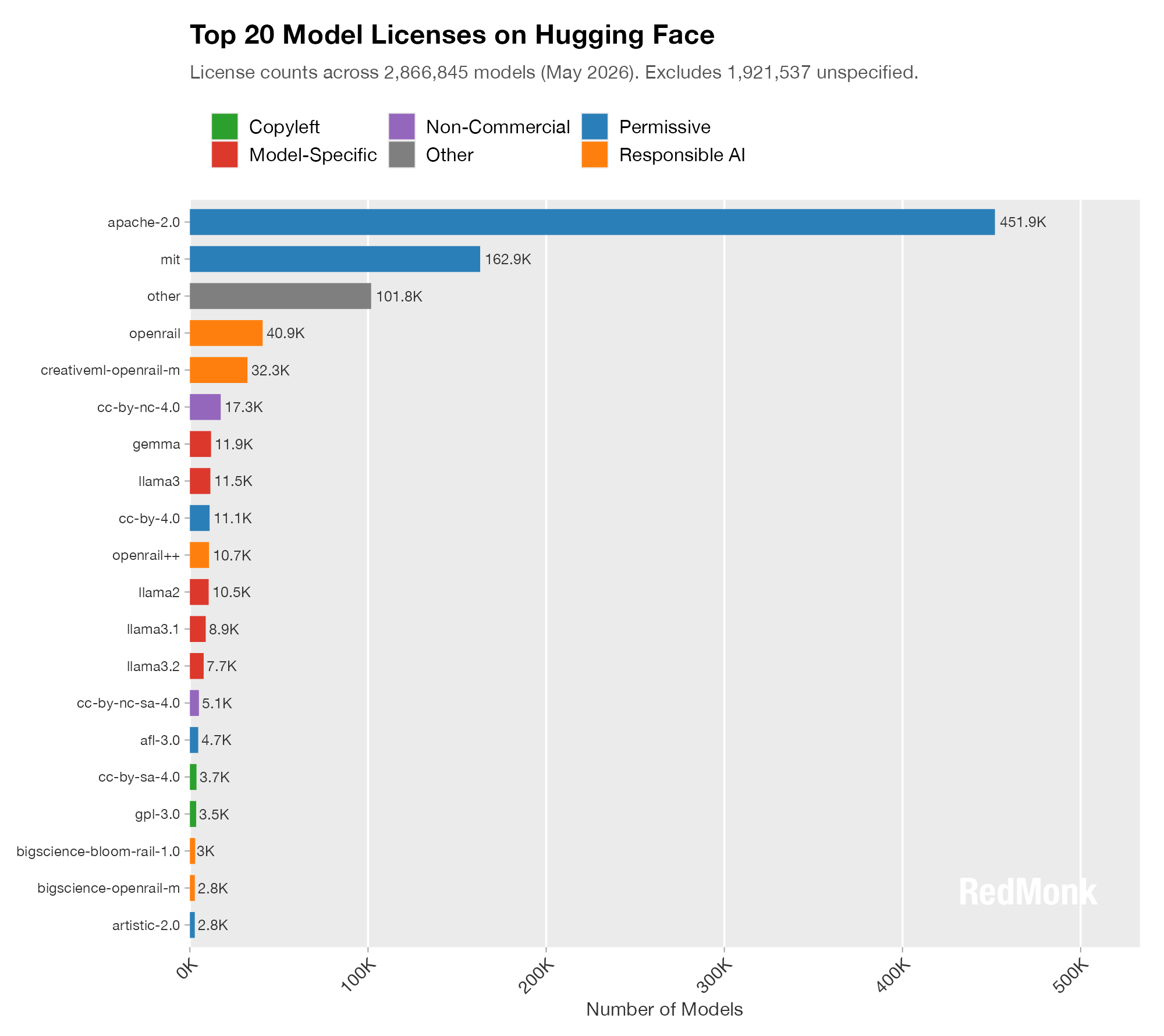
This is a classic long tail distribution, but it is notable just how popular the Apache license is with ~2.5X more licensed projects than its nearest competitor, the MIT license. The next most popular licensing family, perhaps not surprisingly given its Hugging Face pedigree, is Open & Responsible AI Licenses (OpenRAIL). It is the largest single non-OSI, non-model-specific license category in this dataset.
Next, let’s look at the distribution of projects by category.
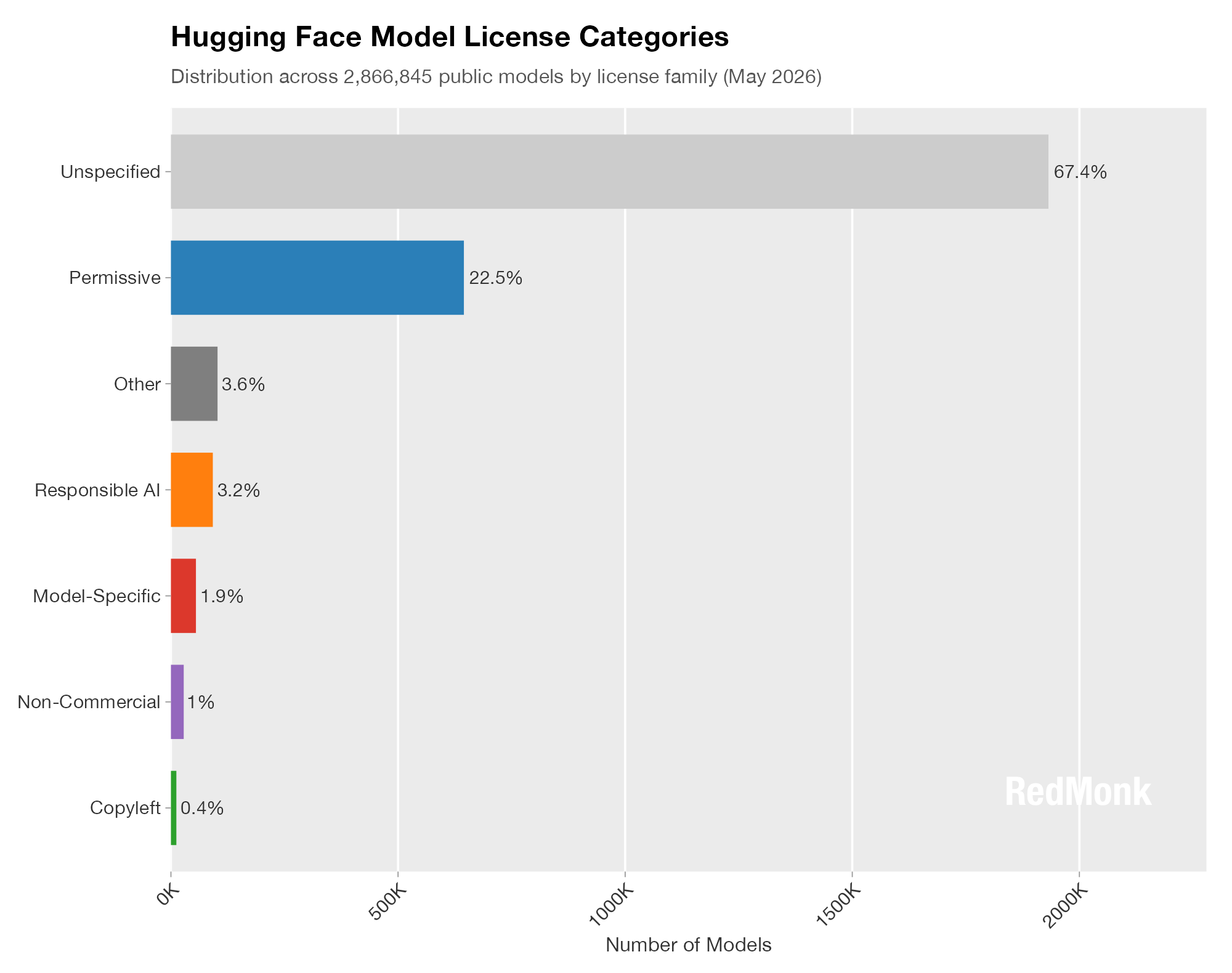
This is the hole in the dataset mentioned above. Just as GitHub historically reported that the overwhelming majority of repositories are unlicensed, almost seventy percent of Hugging Face models carry no license at all. This means that the data represented here about licensing distribution covers only a third of the models, though at almost a million the sample size is still large enough to be meaningful.
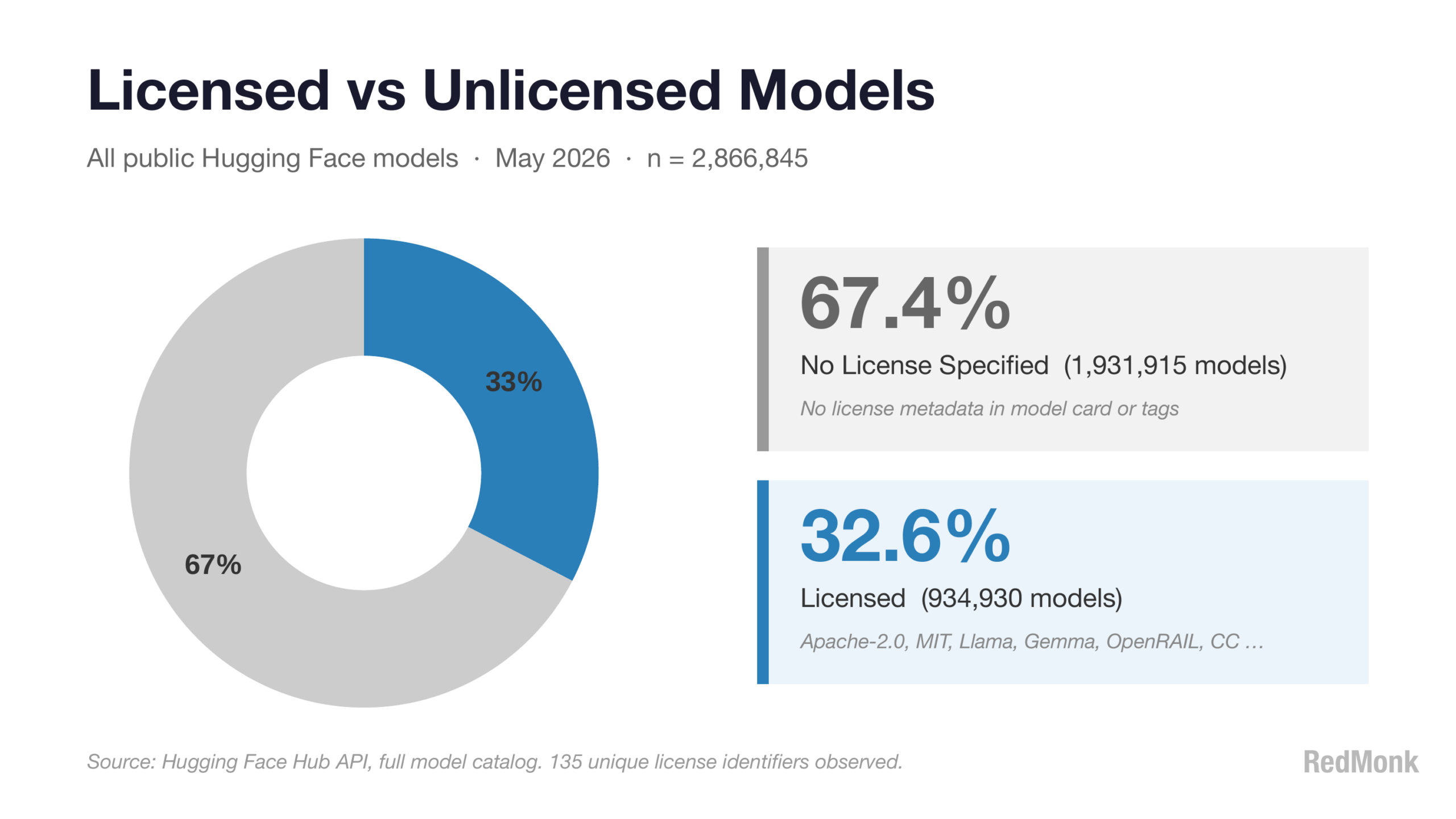
To better understand the distribution, let’s strip out the unlicensed projects and look at only those with one.
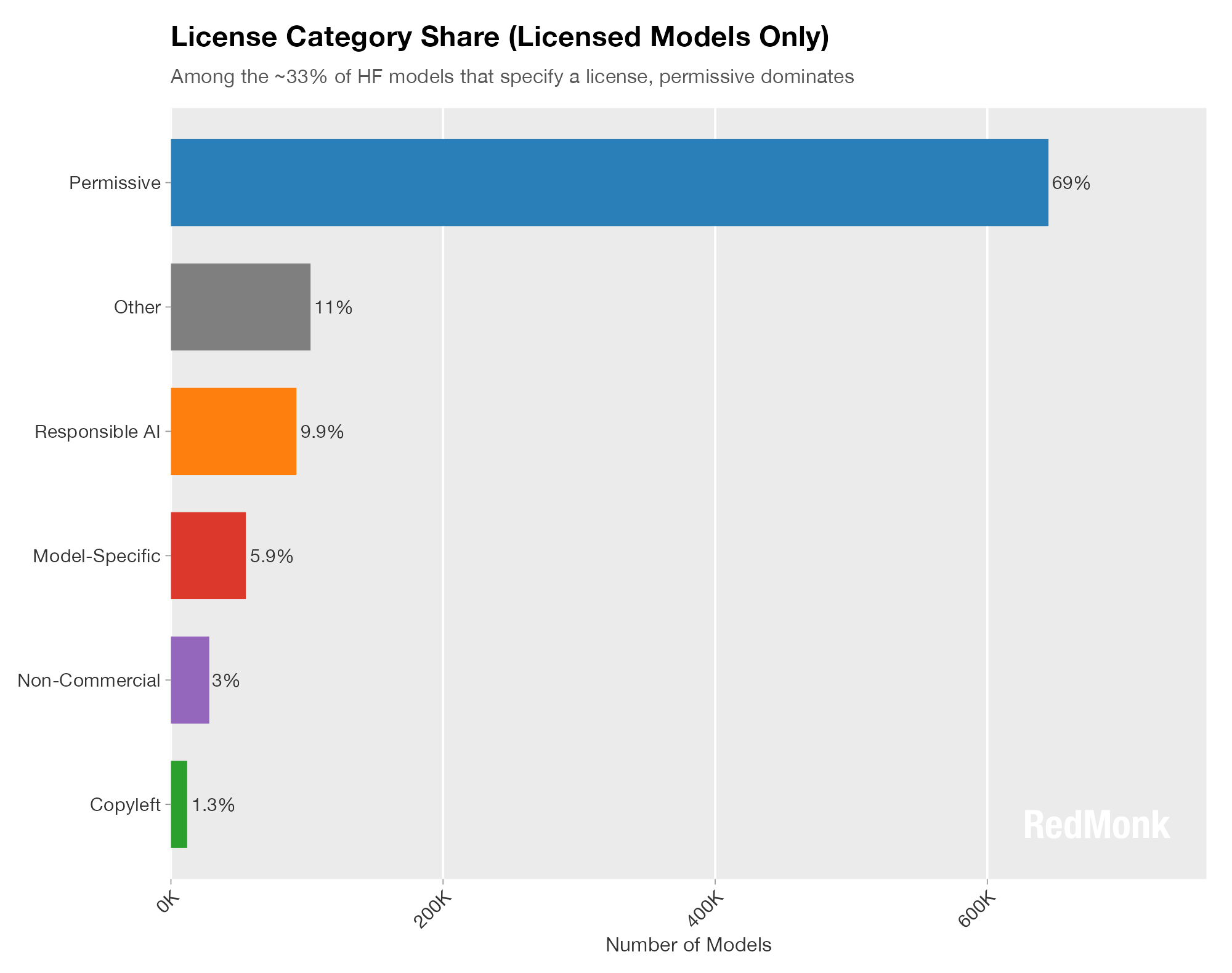
Notably, as was seen in our recent look at the state of open source software licensing, Hugging Face is displaying a systemic preference for permissive licensing models. If anything this data is under-representing the preference for permissive-style licenses, because while OpenRAIL licenses cannot be considered Permissive in the OSI-approved sense, in spirit they embody many of the same values.
Lastly, given the OSI context above, was to look at the specific breakdown of licensed projects carrying an OSI license vs an unapproved alternative.
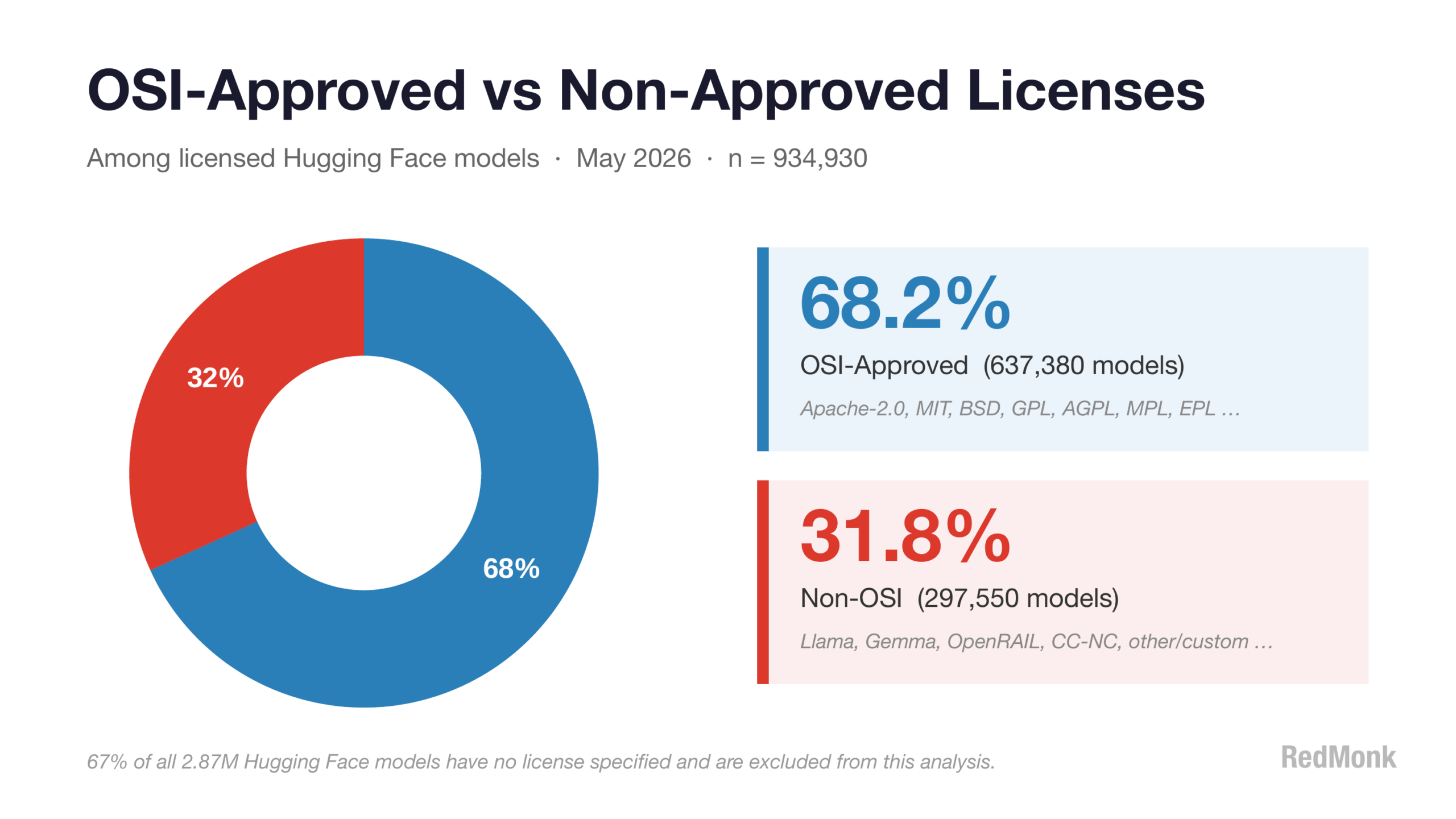
Happily, among licensed projects, better than two thirds carried an OSI-approved license. We may not yet understand the exact role that open source will play within AI, but until there’s clarification a license style with a clear and unambiguous definition is proving to be the most popular choice – in spite or perhaps because of the contrasting styles of licenses that category contains.
