“After six months of development, Grit had become complete enough to power GitHub during our public launch of the site and we were faced with an interesting question:
Should we open source Grit or keep it proprietary?
…After a small amount of debate we decided to open source Grit. I don’t recall the specifics of the conversation but that decision nearly four years ago has led to what I think is one of our most important core values: open source (almost) everything.”
– Tom Preston-Werner, “Open Source (Almost) Everything
It should be clear at this point that commercial valuations of software assets by both practitioners and public markets is in decline. This model of ours, once controversial, is now self-evident. We examined the public markets aspect in detail in May; little has changed since.
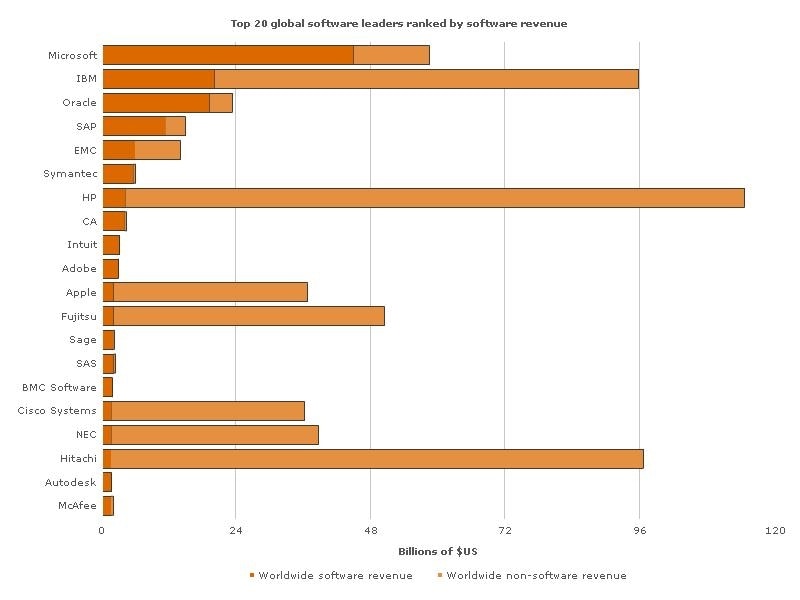
Of PwC’s Global Software Top 20 – the top twenty firms globally as measured by software based revenue – the youngest is 22 years old, and the median age of the top ten is 35 years. It has been over twenty years, in other words, since the software industry produced a business to rank in the Top 20.
Here is a chart of the market capitalizations of PwC’s top five vendors.
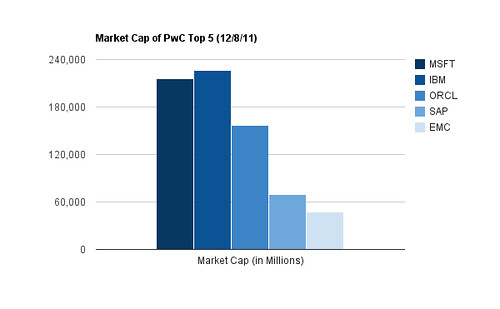
If we remove the artificially narrow lens of revenue from software sales, however, the picture looks very different.
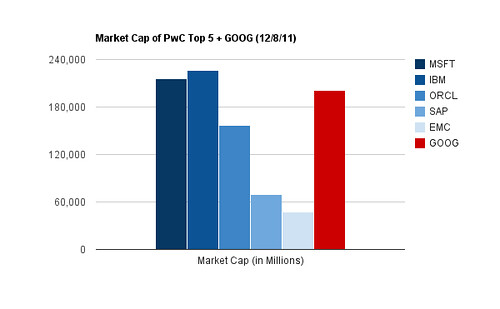
The technology industry has produced entities that would place within the top five; they just aren’t in the business of selling software.
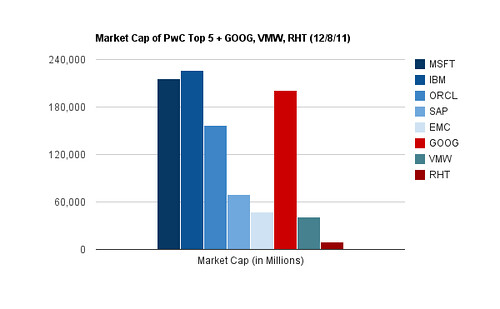
Firms that make money with software rather than from software are outperforming their counterparts in recent years; compare the respective valuations of Google, Red Hat and VMware.
Generationally, attitudes towards software are shifting, as evidenced by Werner’s comment above, and the release as open source of assets like Cassandra, FlockDB, Hadoop, Hip Hop, Hive, Jekyll, Nginx, Pig, Resque, Storm, Thrift and so on. Entrepreneurs and public markets alike are turning their attention away from software sales and towards data oriented revenue models in search of outsized returns. There is and will continue to be an enormous market for software, but real growth is increasingly coming from areas other than software sales and service. This is true even for those currently in the business of selling code; for Sonatype and many other startups, data is increasingly the product.
As obvious as this is to most industry participants, however, the Age of Data remains hobbled by its lack of a free market.
In the early days of commercial open source consumption, the exploding number of so-called vanity licenses – those that were non-standard and vendor specific – and a general lack of understanding of their legal implications inhibited the market for open source, relegating it in many settings to unacknowledged, behind the scenes usage. Gradually, however, license proliferation was curbed and licenses generally began to coalesce around permissive (Apache, BSD, MIT, etc) or file (EPL, MPL, etc) / project (AGPL, GPL, etc) style reciprocal licenses. The net impact of which was increased adoption, because the previous uncertainty necessarily implied risk which in turn throttled adoption.
Which is essentially where the data market is today. Everybody understands that data has value; there is little consensus on how, where and via what mechanisms it should be distributed, licensed and sold. Startups like Buzzdata, Datamarket, Factual and Infochimps cannot by themselves make a market, and with rare exceptions like Microsoft with the data section of its Windows Azure Marketplace, large providers tend to be heavily risk averse with respect to the liabilities posed by data.
Absent a market with well understood licensing and distribution mechanisms, each data negotiation – whether the subject is attribution, exclusivity, license, price or all of the above – is a one off. Without substantial financial incentives, such as the potential returns IBM might see from its vertical Watson applications, few have the patience or resources to pursue datasets individually. We’ve experienced this firsthand, in fact; as we’ve looked for data sources to incorporate into RedMonk Analytics, conversations around licensing have been very uneven. After gaining verbal approval from one content provider for our proposed usage of their API, this was the message we received in response to our request for an actual license:
The short answer is… we are not exactly sure what you are planning to do and whether or not it would violate our terms of service, so the best answer I can give you is that if you are not sure, you’re best off consulting with your own attorney.
As a rule, we don’t have the staffing resources internally (or the legal resources, given the high cost of lawyers!) to make one-off contracts or licenses or exceptions to the generic terms of service.
Hope this helps!
Given the current state of data licensing, it’s impossible to blame them for taking this position, even as it prematurely terminated what could have been a mutually beneficial relationship. Why dedicate legal resources to license review when the projected return on the asset is uncertain? Nor would a commercial negotiation be any more straightforward.
Market efficiency is a function of volume; the more participants, the better an understanding we have of an asset’s worth. With limited mainstream market participation in the business of data, opinions of the value of a given asset tend to be asymmetrical. Put more simply, when we ask what a given dataset is worth, the only correct answer at present is: we just don’t know.
All of which helps explain why Infochimps and others startups targeting the data marketplace opportunity are not as visible as their significance suggests they should be.
For all of the current inefficiency in data procurement, however, it is a temporary condition. Apart from the fact that history tells us risk assessment and licensing are solvable problems, the financial incentives are sufficient to guarantee progress if not complete solutions. Consider the case of Watson. IBM has historically avoided data collection due to legal concerns, but imagine the liabilities of the first diagnostic miscalculation. What will happen, in other words, when Watson commits the healthcare equivalent of “What is Toronto?” while assisting in the diagnosis of a patient? For IBM, the answer is clearly that the potential rewards more than offset the theoretical risk. Enough so, at least, to justify massive investments in development and marketing.
Life may be marginally easier for those that capture their own data, but this will by no means diminish the appetite for more. Google generates sufficient data to be able to predict the flu better than the CDC, but still felt obligated to license Twitter’s data. A relationship that ended, notably, because of a license termination. No matter how valuable an internal dataset might be, it will be more valuable still when recombined, remixed and correlated against complementary external data; see, for example, FlightCaster.
With respect to opening the throttle for data marketplaces, escalating demand virtually guarantees the supply. The real questions are who will play a meaningful role in reducing the friction, and when. Because the attendant opportunities are large indeed.
Disclosure: IBM, Microsoft, Red Hat and VMware are customers. Datamarkets, Facebook, Factual, Infochimps, Google and Twitter are not.

{kind=link}