
Subhrajyoti07, CC BY-SA 4.0, via Wikimedia Commons
Artificial General Intelligence (AGI) may yet be a ways off, but that hasn’t limited the current crop of AI technologies’ ability to impact industries. Much as software once ate the world, AI is ingesting everything from event agendas to internal development focus to available speculative capital. As might be predicted given that backdrop, a growing proportion of technology industry discussions focus on not if but when AI will impact a given market, product or project. The following are a few common themes that have emerged from these conversations.
Interface
Decades ago, before the emergence of trends like cloud and open source, technology vendors typically designed for buyers and treated users as afterthoughts. Products were adopted top down, after all, so what did it matter that the resulting products were hard to use, aesthetically deficient or both?
Thanks to trends like cloud and open source, however, the industry has developed an appreciation for users and consequently thought more about things like developer experience. Gaps persist, but products are generally more thoughtful about their interfaces today than they were a decade or more ago.
Which is why it’s surprising that comparatively little attention is paid to AI’s interface question. Enterprises and in particular the vendors that serve them love to talk about models – and models are important, as we’ll get to momentarily. While those conversations about models are happening, however, legions of developers and other users are actively and aggressively imprinting on their particular tool of choice. And more problematically for the businesses that might want their users to leverage a different tool, not only are users imprinting on their tool’s specific UI, they’re accumulating significant query histories within it that are difficult if not impossible to export.
Anecdotally, there are many stories of developers declining to use objectively superior models because of their Baby Duck syndrome with their tool of choice. And while it’s too early to say, it may well be true that enterprises will find the challenge of getting developers to switch tools comparable in difficulty to getting them to switch IDEs. Good luck with that, in other words.
Worse, unlike IDEs which have a limited organizational footprint, AI tools and LLMs in particular can be used by every employee from marketing to sales to public relations – not just developers and other technical staff.
Model Size
One thing the industry has at present is plenty of models. Hugging Face alone as of this moment lists 683,310 available. It seems safe, therefore, to conclude that the industry is in the midst of a model boom, though how viable or relevant the overwhelming majority are or will be is a separate question. While the list of models is nearly endless, however, the ways that adopters are thinking about them are not.
At least at present, large models like OpenAI’s GPT and Google’s Gemini get the most attention, because their size, sophistication and training scope give them a very wide range of capabilities and, consequently, they tend to demo well. But large models have their limitations, and they can be expensive at scale. For these reasons, many users are turning to medium or small sized models, whether it’s to cut costs, to run them locally on less capable hardware or varying other reasons.
What’s interesting, however, is seeing how vendors are self-sorting themselves on this basis. Google, Microsoft and OpenAI all have models in varying sizes, but the overwhelming majority of their messaging concerns their largest, state of the art models. The same is generally true for the likes of AI21, Anthropic, Cohere and Mistral. AWS, for its part, used its reInvent conference to heavily sell the idea of model choice. And most recently, first at the Red Hat Summit and subsequently at IBM Think, the subsidiary and parent companies laid out a vision of choice, but put a particular emphasis on small models fine tuned with their recently launched InstructLab project. Red Hat’s CEO Matt Hicks was blunt, saying simply “I’m a small model guy.”
Given the varying tradeoffs and myriad of customer needs, models are obviously going to come in many sizes. But it will be interesting to see whether or not small and medium sized models, which have to date taken a back seat to their larger, more capable brethren, get more airtime moving forward.
On or Off Prem
Some months before the Oxide Computer company was launched in 2019, co-founder Bryan Cantrill was privately discussing the prospect of starting a hardware company. The response here was laughter, and calling the idea “crazy.” The response was apparently not an uncommon one.
On the one hand, the pitch had obvious things going for it. First, it was inarguably true that large, at scale internet companies had learned an enormous amount about building hardware and that many of these lessons had been captured and shared publicly in forums like the Open Compute Project. It was also true that the ability of enterprises to purchase hardware built on these hard earned lessons was limited to non-existent.
But on the other, industry consensus was clear that all roads lead to cloud. There were existing on premises workloads that would be impractical or impossible to migrate to the cloud, and thus datacenters would be around indefinitely. But the projections were that most net new workloads would be cloud workloads. Further, cloud provider growth reflected this consensus. Starting a hardware company, therefore, seemed like a sisyphean task.
While neither Oxide nor the rest of the industry knew it, however, AI was about to intervene. Three years after Oxide’s founding ChatGPT was released and quickly became the fastest growing technology product in history.
It was not an on premises product, of course, nor were most of the large models like Gemini that followed it. But just as quickly as enterprises realized that the technology had immense potential benefits, they quickly had to consider the risks of granting these models access to their private, internal data – as illustrated by cases like Samsung.
What has followed has been an observable resurgence in interest in on premises hardware. See, for example, this graph of Google searches for datacenter; note the timing in particular. Correlation is not causation, of course, but the sudden upward tick in these searches seems a little coincidental.
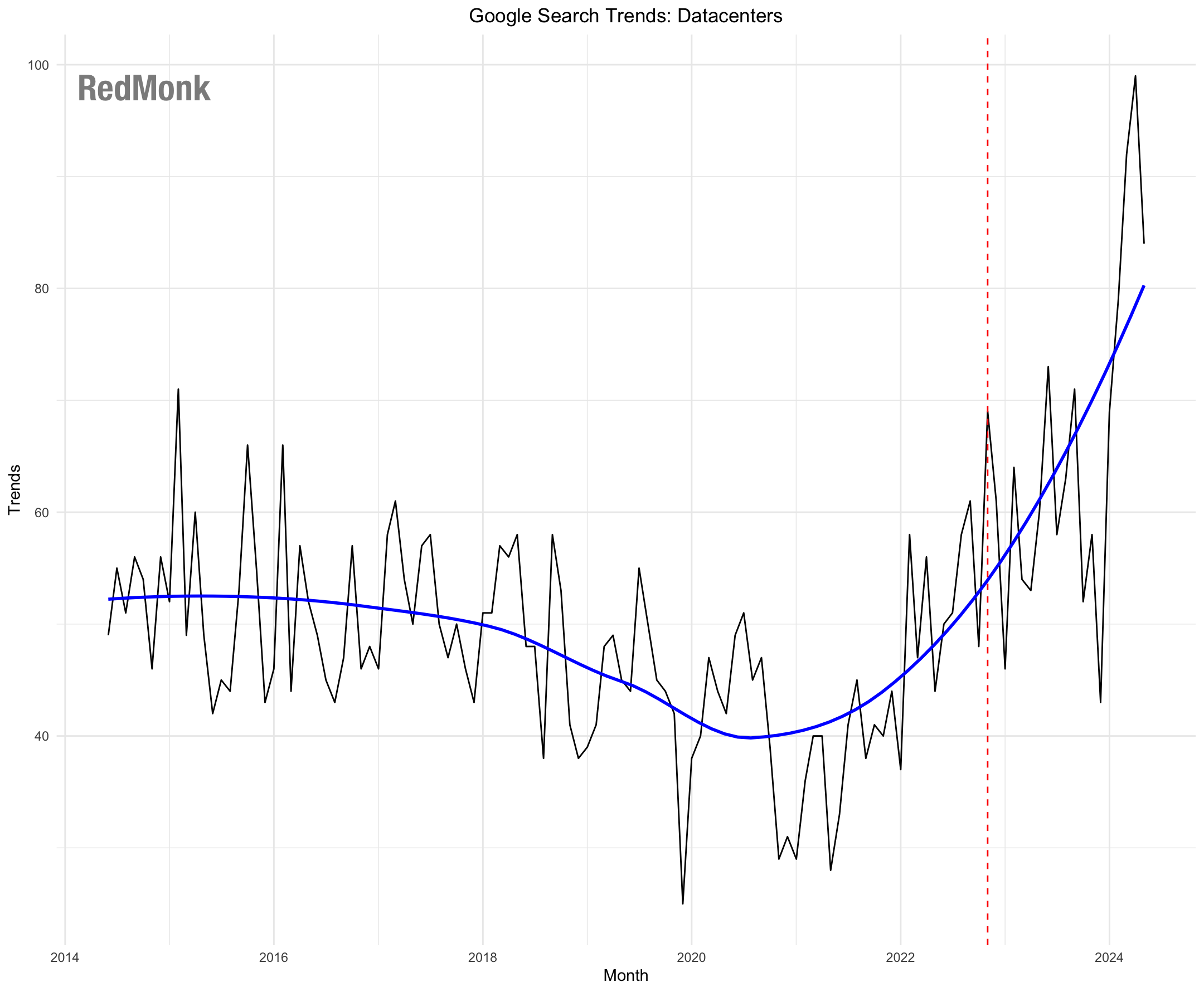
The rise of AI technologies is not going to usher in the great repatriation, to be clear. Cloud providers will remain the simplest and lowest friction approach for standing up AI workloads in most cases, because operating datacenters is both hard and expensive.
But even for vendors like Oxide that do not specialize in GPU-based hardware, the accelerating demand from enterprises to run local infrastructure to leverage data they do not trust to external large providers is likely to significantly expand on prem compute footprints.
Gravity and Trust
Another contributing factor to the expansion of on prem AI implementations is the so-called gravity to the large datasets that are the fuel on which AI depends. Large data is difficult to move quickly and safely, and as with physical objects subject to Newtonian physics, data at rest is likely to stay at rest. The idea of data gravity, of course, is not new. Dave McCrory was articulating the idea as far back as 2010, and it’s a well understood aspect to data management.
What is perhaps less well understood is the idea that gravity and trust are inherently intertwined. A large accumulation of data in a given location, of course, is an implicit assertion of trust. If an enterprise didn’t trust the platform, it would not choose to aggregate data there but a platform it trusted more. This in turn implies that where a large dataset currently resides is likely to be more trusted than a new platform, whatever assurances the new platform provider might share.
Practically speaking, then, large scale data management providers have a trust advantage over new market entrants. Even if Salesforce’s Einstein AI suite can’t match OpenAI’s feature for feature or capability for capability, then, it might well be worth leveraging because of the trust gap between the two vendors. And indeed, we’ve had a customer admit exactly that.
Trust won’t always trump features, of course, and some data is less sensitive and requires commensurately lower levels of protection. But trust is undeniably a factor in AI adoption, and is likely to favor incumbent providers at least in the short term.
The Net
AI adoption involves a multitude of considerations, clearly, and cannot in most cases be reduced to a single axis upon which to make a decision. As much as providers want to tout features and new capabilities, incredible as those may be, adoption will in most cases be a complicated conversation involving multiple parties, differing fears and risk estimates and decisions on how to weight capability versus size, speed and cost.
Disclosure: AWS, Google, IBM, Microsoft, Oxide, Red Hat and Salesforce are RedMonk customers. AI21, Anthropic, Cohere, Mistral and OpenAI are not currently customers.

{kind=link}