(Credit: Miguel Chavez, CC BY-SA 4.0)
In evolutionary biology, there’s a hypothesis called punctuated equilibrium. In simple terms, the theory posits that evolution follows a path that is not a process of gradual, incremental change over millennia, but typically a static process irregularly punctuated by periods of rapid change. Things are the same, and then they’re not – quickly. For all that the technology market claims to be a dynamic industry, and with justification, punctuated equilibrium is a useful frame for considering how market shifts occur – slowly, and then fast – even as the specific causative factors themselves are difficult to predict in advance.
In the last decade of the last century, for example, the groundwork for an upending of the technology industry was laid by a series of seemingly random, unrelated events and players.
- A one time minor contractor for a third party operating system rose from obscurity to utterly dominate the technology industry.
- A highly problematic hacker frustrated by his inability to rewrite laser printer software hijacked copyright for use as a lever for software licenses.
- A Finnish graduate student asked for help on a hobby project promising that it wouldn’t be big and professional.
- The company that originally contracted for the third party operating system saw an opportunity to leverage the combined efforts of the hacker, the graduate student and many others to disrupt the modern descendent of that operating system.
All of which is a dramatic oversimplification, of course. The number of factors that contributed to the industry state change from the early 1990’s to the mid 2000’s is literally uncountable. But if nothing else, the examples cited above are useful symbols of a how a small number of seemingly indirectly related changes can lead to a tectonic shift in the fortunes and direction of an industry.
Fast forward to 2023. For at least a decade now, the technical direction of the industry has seemed roughly linear, almost inevitable. According to our hypothesis, this would imply the future, and likely at some point soon, is about to become decidedly non-linear. The following are three questions to consider when attempting to determine how our path might shift, and in what direction.
- Where is the cloud growth going to come from?
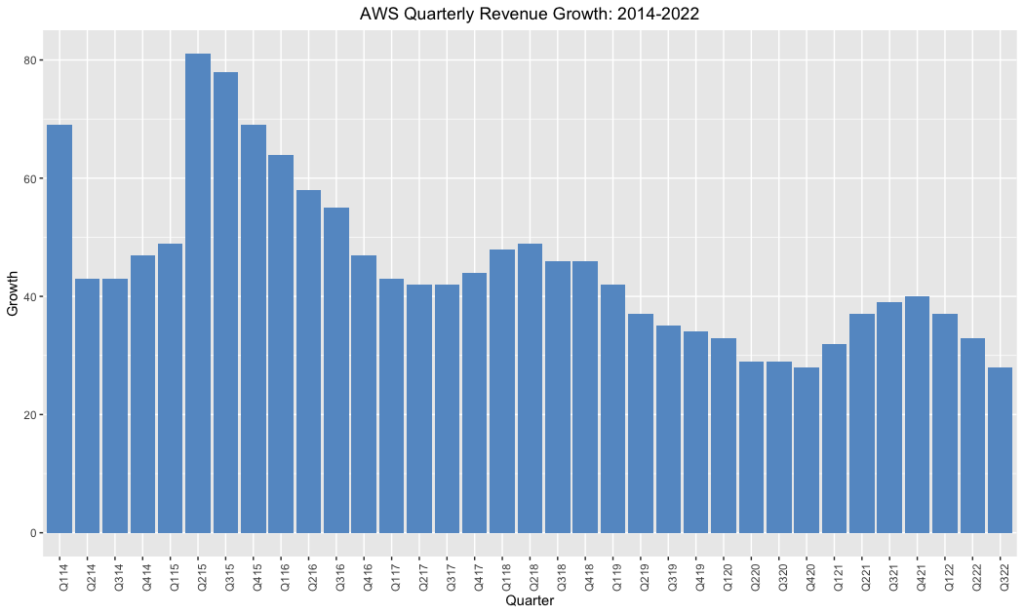
Evaluating cloud growth in 2023 is akin to asking whether the glass is half full, or half empty. The empty crowd points to charts like the above, suggesting that the trendline of AWS’ revenue growth is so obvious none is needed. The half full crowd, meanwhile, observes that it’s considerably easier to grow revenues that haven’t yet exceeded the $5B threshold than it is the $100B mark that could be hit in the next year.
The full crowd might add, meanwhile, that a distinct minority of enterprise workloads have reached the cloud. With figures ranging from 20-40%, the argument goes, there’s a massive opportunity still on the table. The empty crowd, for its part, notes that the cloud market has been in existence for almost seventeen years, and if those workloads haven’t come over yet they’re not likely to.
In reality, both sides of this argument miss the point, which is that both sides can be true. The traditional cloud market – which is to say the market for cloud primitives – can and does have a lot of runway left in front of it and will be with us indefinitely.
Yet it is reasonable to ask questions about growth rates. Where is the next hockey stick growth curve likely to come from moving forward – more compute instance types? Yet another type of managed database? Dozens more managed services?
Which brings us neatly to the second question.
-
How is the market supposed to absorb the never-ending flow of new primitives?
When the largest providers of cloud primitives acknowledge – privately, at least – that there are too many primitives and that sifting through them is a growing problem, there may be issues with a “primitives are the answer now what’s the question?” approach. Among the more pressing issues are the inevitable gaps between the various services which by default become the problem of developers, DevOps and platform teams or some combination of the two. All of which is a less than ideal scenario for both developer and their employer. Time spent wiring primitives together is time spent not writing code, which means less joy for the developer and less differentiating value for the employer.
This problem is in part what has led to a resurgence in interest in platforms that might once have been called – and might be once again, before all is said and done – PaaS offerings.
The history of PaaS, and abstractions more broadly, is a long and winding path. The salient details here, however, are simple: PaaS was introduced shortly after IaaS as a simpler alternative for developers. Platform-as-a-Service offerings were designed to minimize complexity for developers and operators in an era when the industry had only the faintest idea of what complexity actually meant.
But for all its promise, PaaS was thoroughly outcompeted by IaaS – to the point that the former term was largely given up and left for dead, even by those vendors that helped make it a household name. More interestingly, with the exception of Azure which though many forget began its life as a PaaS before transitioning to a more traditional IaaS model, the hyperscale cloud providers have generally ignored the PaaS market. To be sure, GCP has relevant offerings like Cloud Run, and AWS appeared briefly to perceive the market opportunity in the space before subsequently taking a firm step back, but to date none of the largest cloud vendors has done much of anything to articulate to the market a vision that isn’t centered around primitives – complementary to that infrastructure model though such a vision might be.
As developers have begun to sag and then buckle under the weight of the flood of new services, however, that alternative vision appears more and more attractive. What developers are seeking now isn’t more or faster primitives, but offerings that have thought carefully about what the ideal experience of using these primitives might look like: how should they be used together? What tasks can be taken off a developer’s plate and put on the platform’s? How can a platform be delightful – rather than tedious – to use?
In typical fashion, the risks of this unproven market for a better developer experience are not being born by the large incumbents, who are as mentioned largely sitting this one out. Instead we’re seeing a flowering of next generation platforms which range widely in their specific approach and focus. As the likes of Cosmonic, Fermyon, Fly, Glitch, Netlify, Railway, Render or Vercel go to market, they are in their own various ways targeting the same problem: the flood of primitives, and the questionable developer experience that inevitably results from that.
In differing ways, however, they are each up against history. The promise of PaaS has always been about abstracting away complexity, which in turn requires making some decisions about what specifically a given platform is composed of. And if the vendor is making those choices on behalf of the customer, inevitably the customer will have workloads for which said choices are a poor fit. This has meant that putting together an abstraction that is appropriate even for a simple majority of enterprise workloads rather than a specific subset of same has proven to be, to date, not possible.
Which is not to say that constrained platforms are destined to fail; quite the contrary. All signs suggest that a credible alternative to the IaaS market that has learned the lessons of past generations of PaaS software has a bright future ahead of it.
But what if there was a way to abstract the complexity without the constraints? A question which brings us to our third and final question.
-
What are the implications of the recent advancements in AI?
As an area of research and focus within the industry, AI has had its ups and downs. When a period of that evolution is commonly referred to as “winter,” it’s clear that progress has been uneven. For years AI was regarded in some corners as little more than clever marketing for “linear regression,” and indeed with notable exceptions, most of the enterprise use cases were abstruse and hyperspecific – the literal opposite of versatile.
That skepticism notwithstanding, it’s worth noting that the application of AI to narrowly circumscribed domains such infrastructure is not new, and has been objectively beneficial. Seven years ago, as one example, Google lowered its datacenter cooling bills by 40% by rubbing some AI on it. That same year, our industry colleagues at Gartner coined the term AIOps to describe the trend of injecting AI into standard operational tasks.
Within the last twelve to eighteen months, however, we’ve begun to see what might be best characterized as technical developments that might lead to one of the aforementioned periods of punctuation. As a colleague recently noted, it’s difficult to overstate the impact that AI is poised to have on developer experience in the months ahead. With large language models and other related techniques now able to generate art, music and handle regular conversational inputs – with the expected associated legal and ethical questions as well as some notable limitations that we’ll come back to – the door has been opened for entirely new interfaces for backend technologies.
Which matters because while there’s little question that machine learning tuned algorithms can improve operational ability and efficiency behind the scenes, the potential gains have largely been throttled by the inaccessibility of the underlying AI technologies as well as the skills necessary to leverage them even if you had access. What if, however, the AI technologies became more common while the skills necessary to leverage them were lowered to “can you hold a conversation?”
That, it would seem, would open up a broad new vista of possibilities. As but one example, it would become possible to envision an AI conversational interface sitting in between a user and the aforementioned sea of primitives. Rather than a user having to comprehend, select, instantiate and operate those primitives, what if a user simply issued simple conversational commands to deploy a given type of application to an underlying cloud infrastructure and let the AI – presumably have been trained specifically for this purpose – handle the specifics?
In that case, it might be time to ask: when is a PaaS not a PaaS?
To be clear, we’re not overly close to this potential future at present. The “limitations” of today’s AI conversational elements were mentioned above, and chief among them is that they are frequently as wrong as they are confident. Which is not a model that will work at scale.
But if a large language model is more narrowly defined than “general conversation,” if it were scope limited to technical infrastructure it seems likely that these are solvable problems. When you talk to industry participants today, in fact, related innovation is privately – or in some cases publicly – bubbling up everywhere. And if we consider the factors described above: a need for new outsized growth paths, a slowing ability for end users to consume the army of arriving innovations and a step function increase in the versatility of LLM-backed AI agents, Jevon’s Paradox suggests that change may be in the wind. It’s less of an absolute paradox in this particular case, but the economic principle, summarized below, seems clearly applicable.
Jevon’s Paradox occurs when technological progress or government policy increases the efficiency with which a resource is used (reducing the amount necessary for any one use), but the falling cost of use increases its demand, increasing, rather than reducing, resource use.
From their inception, the goal of PaaS platforms has been to increase the efficiency for the consumption of cloud resources. To date, that mission has been limited by the inability of most PaaS platforms to handle the wide spectrum of workloads enterprises expected. But if a technology existed that could both lower the barriers to usage via a conversational interface without major compromises on the workloads handled, it’s easy to imagine this “platform” increasing resource use.
When we throw in the fact that some of the parties with the deepest resources, expertise and capabilities in AI are the very same providers of the primitives – providers intent on growth and whose customers are struggling with the size of their respective product catalogs – it’s worth asking whether said providers may be coming around on the idea of a PaaS, but models based on AI rather than prescriptive curation and constraints.
One thing, at least, is clear: if any of the above speculation proves true, the industry equilibrium is about to be punctuated.
Disclosure: AWS, Azure (Microsoft), GCP, Glitch (Fastly), Red Hat, Render and Vercel are RedMonk customers. Cosmonic, Fermyon, Fly, Netlify and Railway are not current customers.

{kind=link}