In an effort to examine the state of the time series database market, this post will explore the following topics: What is time series data and why is it increasingly relevant? Why would you want to consider using a time series database? What is the community traction around time series databases?
Times Series Data
Time series data is simply data with a timestamp that is collected with the intent of tracking change over time. There are a growing number things creating and using timestamped data, including:
- IoT devices: The sensors on connected devices transmit timestamped readings, measurements, statuses, or other metrics back to a centralized repository.
- IT infrastructure: As infrastructure stacks become more complex and more distributed, timestamped data helps manage the health of the various hardware, software, and networking components of the system.
- Business analytics: As data-driven cultures expand throughout an organization, many teams rely on timestamped operational or financial data to help inform decisions.
- Financial and scientific data: These two sectors are particularly driven by timestamped data.
Timestamped data can include data that is generated at regular intervals (e.g. the data is routinely collected as a sample or snapshot at a given time interval) or unpredictable intervals (e.g. when the occurrence of an event or state change triggers the data collection, and you don’t necessarily know when the data will come in.)
Some general characteristics of time series data are:
- Once created, the data tends to be immutable. Point-in-time measurements are generally not changed, and new data is appended to the data set rather than revising previous data.
- Time series data sets are designed to track changes over time, but not all time periods are of equal importance. More recent data is typically the most useful and actionable, whereas the granular details of older data may be less relevant.
- The data tends to be high volume.
Why TSDB?
Time series databases (TSDBs) are optimized to treat timestamped data as a first-class citizen and account for the above data qualities. While different TSDBs have different functionality, some of the commonalities include:
- Database scale is often a primary concern, with many databases supporting clustering for high availability.
- TSDBs optimize for large scans over many records. Many facilitate better query performance through column-orientation.
- High incoming data volume requires high-performance writes. Those seeking real-time analytics also need high-performance reads.
- TSDBs have a data lifecycle management processes to handle data as it ages. This can include aggregating older data to a higher level of detail in addition to creating data retention policies.
- Many TSDBs attempt to simplify the challenges specific to time-based queries, such as handling time zones or providing filters for things like days of the week.
Other Approaches
While TSDBs specialize in handling this timestamped data type, the discussion around how people currently ingest, store, and use time series data would be incomplete if the scope was exclusively limited to time series databases. Competition lies not only within the TSDB market but also across technologies.
Particularly for infrastructure management use cases, logging, monitoring and observability tools are competitors to TSDBs. Some TSDBs like Prometheus are intrinsically monitoring solutions with a time series database attached. However, TSDBs are not very good at handling high-cardinality data, (i.e. data with values that are very unique), so many companies in need of deep debugging or tracing functionality will require additional tooling beyond a TSDB.
Streaming architectures are often used in situations when data volume is high. Companies that already have a Kafka or Spark Streaming infrastructure in place may be able to extract the functionality they need by porting the more ephemeral data directly to a dashboard. They can also persist the data in a variety of databases options, as a specialized database is not required for handling time series data.
General purpose databases can be implemented for time series uses cases:
- Columnar databases: Column-oriented databases like Cassandra are a common substitute for a TSDB, as they are designed to scale. In fact some TSDBs are written as layers on top of columnar databases – notably Cassandra or HBase.
- Search databases: Search databases like Elasticsearch can be good choices for housing time series data because of their ability to rapidly query metrics at a high volume.
- Relational databases: Relational databases can be optimized for time series data. Scale can be a challenge, but there are plenty of instances of using relational databases like PostgreSQL for time series data.
Makers of TSDBs would argue that a general purpose database requires additional overhead to build and manage functionality their databases can do natively. General purpose databases would argue that an additional specialty database is its own form of overhead. In any case, the debate on optimal infrastructure for time series data is very much open.
Competitors
If we examine competitors within the TSDB category, what kind of trends are emerging with regards to both individual competitors and the segment as a whole?
The below view of competitors in the time series space is a general survey, but importantly it is not an exhaustive list of every project. This exercise is instead an attempt to give a sense of databases that we see most often as competitors within and to TSDBs. In order to narrow the focus across the plethora of possible options available we used the following selection criteria:
- The database is an open source project. While there are notable commercial offerings in the space, the below analysis is based on community visibility and metrics that are not available for closed source products.
- The database is not repurposed from another database category (though we do provide comparisons to other popular general purpose databases that are often used for time series as a point of reference).
- The project has a reasonable level of activity and stability around it.
- The database has come up in our conversations with developers.
We often use GitHub stars as a loose proxy for developer interest. While this metric is not perfect, it provides a gauge by which to view relative traction amongst projects in the developer community. [Note: Other metrics like pull requests, comments, or forks can also be great ways to compare projects. In this instance, different projects have different engagement models (i.e. using GitHub as a project mirror, not engaging in comments/pull requests via GitHub, etc.), and as such we have chosen to limit the analysis to a high level view of GitHub stars.]
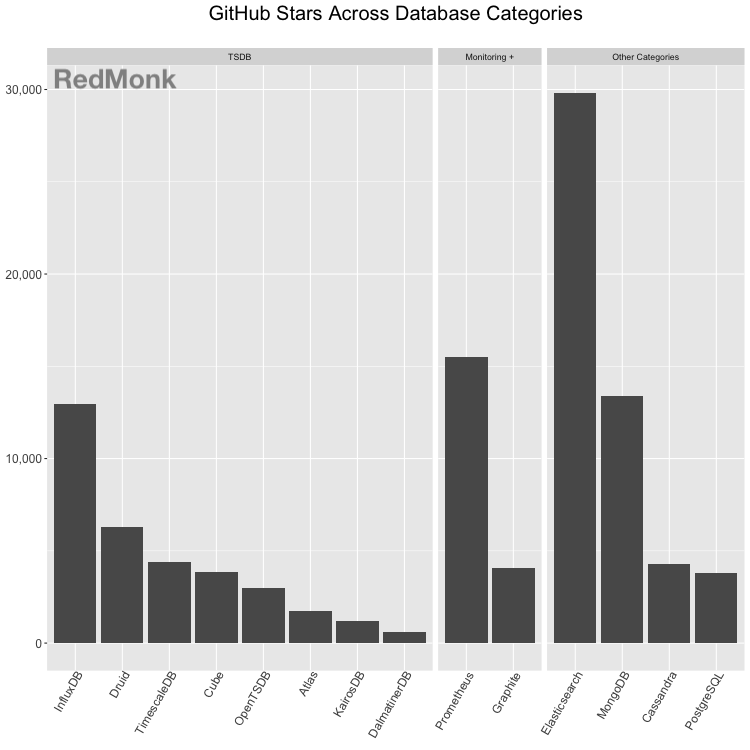
Based on GitHub stars, InfluxDB and Prometheus emerge as the open source tools with the strongest traction amongst open source TSDBs or monitoring solutions with TSDBs. When the view is expanded to databases in adjacent categories, Elasticsearch is clearly dominant. However, special purpose time series tools are holding their own when compared to general purpose databases as measured by GitHub stars.
This trend from GitHub does not hold for Stack Overflow tags. Using Stack Overflow questions to gauge community interest invariably generates the objection that easier to use tools are penalized, or that tools with communities established elsewhere are excluded. We do not claim this to be a holistic view of a database’s community, but instead view it as a form of directional insight.
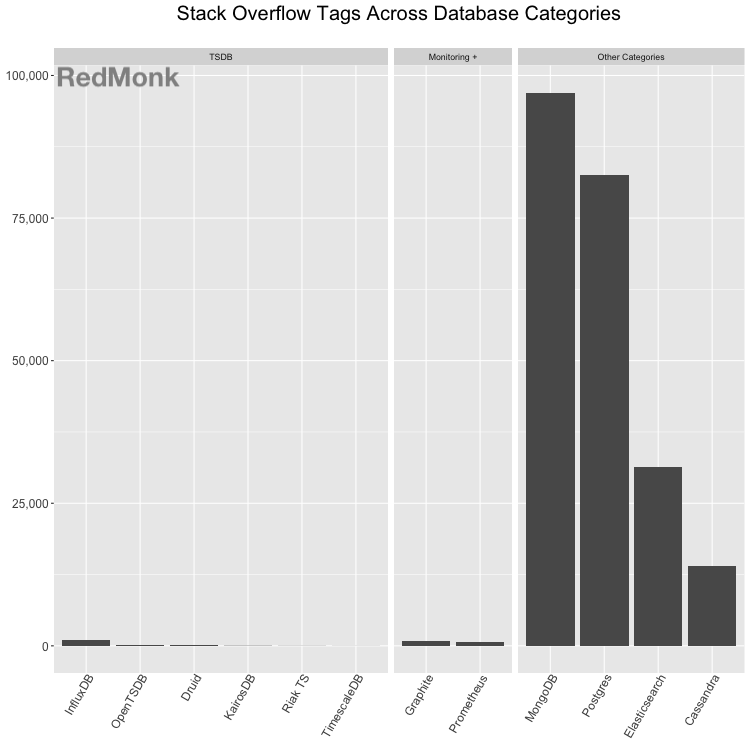
The degree of developer interest in time series tools as measured by discussion on Stack Overflow tells quite a different story. Questions tagged for general purpose databases far outstrips those for TSDB categories across the board. We expect general purpose data stores to have more support because they have more use cases, but the degree to which generalized data stores outpace their TSDB counterparts in Stack Overflow discussion is stark.
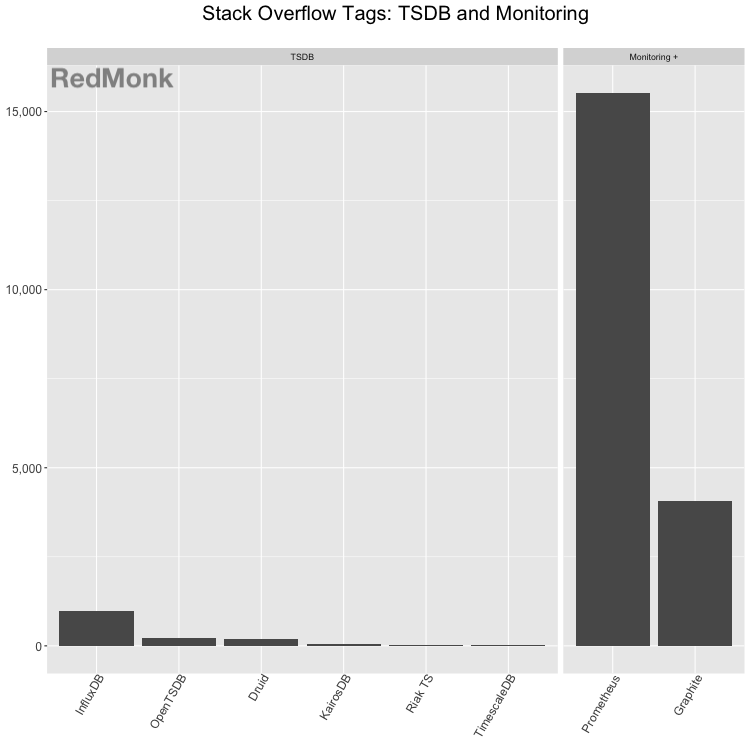
When the view is limited just to TSDB and TSDB monitoring tools, discussion around monitoring dominates the category. Special purpose TSDBs have received relatively little traction as measured by Stack Overflow questions.
Notes about the analysis:
Some databases were represented in only one of the metrics. Riak-TS, for instance, is not included in the GitHub analysis because there is not a distinct repo for their time series product amongst the overall Riak project. Several projects did not have distinct tags in use on Stack Overflow, including Atlas, Cube, and DalmatinerDB.
There are many other competitors within the TSDB space, some of which we could not include in the analysis above. Here are some other projects that caught our attention.
Commercial offerings: the nature of our analysis meant there was an inherent lack of visibility for notable commercial database products, including IRONdb, Kdb+, eXtremeDB, and Informix.
Stability: while this is a more subjective metric, we opted to exclude databases with open disclaimers about the project’s stability, notably Spotify’s Heroic.
Conclusion
While these metrics are limited, they are suggestive of either an emerging or niche market. If you view GitHub stars as a leading indicator, this tells the story of strong developer interest in TSDBs while implementation and its accompanying discussion lags. However, this could also be the story of a smaller addressable market, wherein the need for TSDB functionality is real but the targeted users, at least at present, are limited.
We at RedMonk frequently talk about the trend of increasing fragmentation. From my colleague Steve’s post Divide et Impera:
On a purely technical level, fragmentation is systemic at the moment, the new norm. Pick a technical category, and there are not just multiple technologies to select from, but increasingly multiple technical approaches.
This is particularly true for the time series market. The market is fragmented with often non-related use patterns that range from monitoring to analytics to IoT, among other specialized use cases. Depending on the usage, there are numerous potential approaches to handling the data, some of which may not require a database at all. Within the database market, the pure TSDB market fields many viable options, but other database categories and monitoring tools may also offer competitive time series functionality.
Increasing fragmentation has led to some interesting trends in databases. Steve wrote about the trade-off between generalized and special purpose databases in Where the Database Market Goes From Here wherein we’ve seen the trend of once specialized NoSQL data stores gradually shifting back towards more generalized use cases and functionality as they seek adjacent markets and the growth that these offer.
These trends of fragmentation and a move to general purpose data stores impact the community traction we see around time series databases, but this does not necessarily tell an inevitably problematic story for the category. This highly differentiated market has led to interesting technological developments, and this progress is only expected to continue based on the projected future growth of time series data. We foresee an increasing need to ingest, manage, and act upon time series data. While the market around time series databases is still coalescing, we expect TSDBs to play an important role in the future story of data management and see commensurate commercial opportunities.
Disclaimer: MongoDB, Circonus (IRONdb), and IBM (Informix) are current RedMonk clients.
Note: Charts updated 2018-04-04 to include TimescaleDB.
Aliaksandr says:
October 10, 2019 at 4:28 am
Could you update the charts with VictoriaMetrics? It is promising open source TSDB with good traction. See https://github.com/VictoriaMetrics/VictoriaMetrics .
Roman Khavronenko says:
November 29, 2020 at 8:06 am
Would be great to update the list of TSDBs with VictoriaMetrics since it gets more popularity now.