Since the last time I touched working code in a production environment, it’s no exaggeration to say that no part of the development process remains untouched. Over the last decade plus, effectively every aspect of the application development process has been scrutinized, rethought and in many cases reinvented. From version control to build systems to configuration and deployment to monitoring, modern development’s toolchain is multi-part and sophisticated.
As it must be. Processes that work for code released in cycles measured in months cannot be expected to handle workflows measured in days or minutes.
For all that the process of developing software has evolved, however, the database remains curiously overlooked. Consider the example of Cloud Native. Describing a modern, typically legacy-free approach to building applications appropriate for cloud environments, the term Cloud Native has gone from informal descriptor to accepted industry shorthand in short order – to the extent that it has its own technical foundation.
If we look at the membership of that foundation, the CNCF, it would appear that the roster includes no database vendors at the Platinum or Gold membership levels, at least if you assume Google’s involvement is around Kubernetes and not tools such as BigQuery. Of the 41 silver members, meanwhile, two can be considered database vendors: Crunchy and Treasure Data.
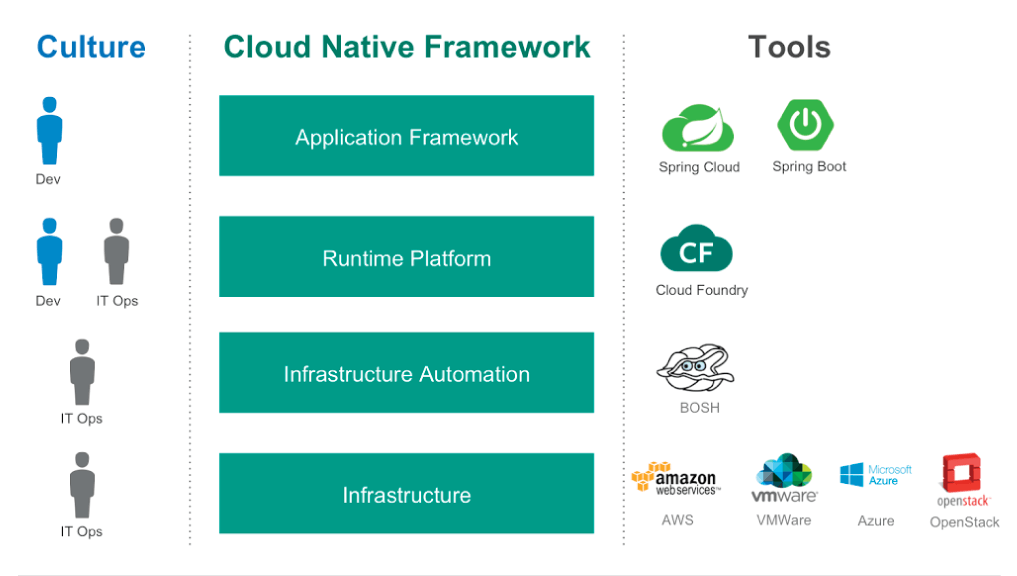
For its part the Cloud Native architecture diagram from Pivotal, the company that first got behind the term, does not explicitly call out databases or database administrators.
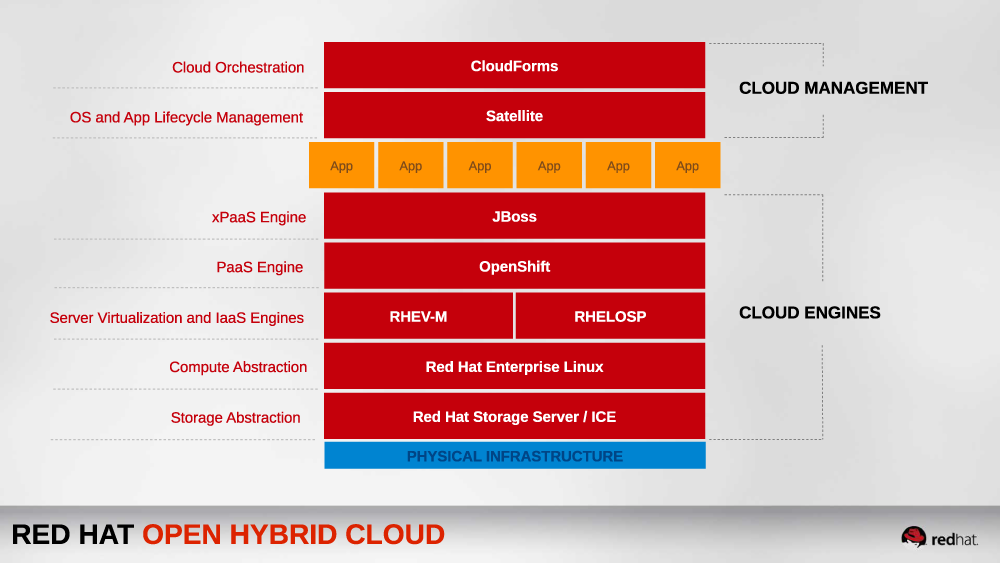
Nor does Red Hat’s Open Hybrid Cloud architecture diagram.

If you query the 12factor.net website for the term “database,” meanwhile, you get about 20 results back, none of which are database-centric and many of which are translations.
From a market standpoint, it’s clear that databases are anything but an afterthought. The market valuations are substantial, and customers choices are expanding as are commercial investments in the space. But if you were judging simply by visibility of databases within the developmental toolchain and associated discussion, it is clear that databases do not occupy a position of prominence.
The question is why.
Some of the vendors in the space make an implicit argument that it’s a technology problem. But while it certainly cannot be argued that database tooling has undergone as rapid or thorough of an evolution as their application development counterparts, there are many operationally focused database vendors with technology that could certainly be useful in a DevOps context. Some market to this – see, for example, DBmaestro’s tagline of “DevOps for Database.” Others with applicable functional coverage such as Datos, Delphix or Redgate do not, with their messaging clearly aimed at traditional database administration buyers. Even developer-accessible offerings such as Citus Data or Heroku Postgres don’t explicitly try and make the connection from the operational data layer back to DevOps, or on a detailed level the task of application lifecycle management.
To some degree, this is to be expected as an artifact of a divide that continues to persist within most enterprises. While barriers between developers and operators have been actively targeted for elimination, the boundaries between developers and database administrators have remained well off the radar. Operators were once a distant, disconnected constituency, but are increasingly being integrated into development teams and vice versa. A similar thawing between the developer and DBA has yet to occur.
Which is why we still have application development models that don’t mention the database, and development-oriented database tooling that doesn’t mention DevOps. Neither of which, it should be noted, makes business sense.
Or is likely sustainable. Sooner or later, someone is going to realize that the continuing divide between the people developing the applications and the people that manage the data behind those applications is an obvious inefficiency, and like all market inefficiencies it will be targeted.
The question is not if, but when and who.
Disclosure: Citus, Pivotal, Red Hat, Salesforce (Heroku) and Treasure Data are RedMonk customers. Crunchy, Datos, DBmaestro, Delphix and Redgate are not currently customers.
