One of the fundamental questions raised by the rise of open source is what software is worth, in the commercial sense. Industry opinions on the subject vary; the data less so.
The market holds no great opinion of the technology industry broadly. The Fortune 500 includes zero technology vendors in its Top 10. For all of the attention that Apple’s passing of Microsoft’s market capitalization a year ago Thursday accrued, it is #35 on the Fortune 500 with a market cap $97B south of Exxon’s. Even within the context of the software industry, there are indications that the market is pessimistic about the potential returns realizable through software.
A software analog to the Fortune 500, the PwC global 100, ranks software vendors worldwide by revenue. The salient detail to be extracted from their list isn’t their relative underperformance within the Fortune 500, but rather their age. None of the vendors in the Top 20 of the PwC ranking* were founded after 1989. The mean age of the list, in fact, is 47 years. 31 if outliers such as IBM (1911) and NEC (1899) are omitted.
On some level, this could be predicted. Using acquisition as a means to outsource risk is a business practice with a long history; see Paul Graham for the best explanation of its role within the technology industry. Big companies pay a premium for small companies in order to acquire new resources, processes, business models or all of the above.
This model inadequately explains current market conditions, however. It fails to account for the fact that two of the top three technology vendors by market cap – Apple and Microsoft – are on the younger side of the mean. But more problematically, it fails to account for Google.
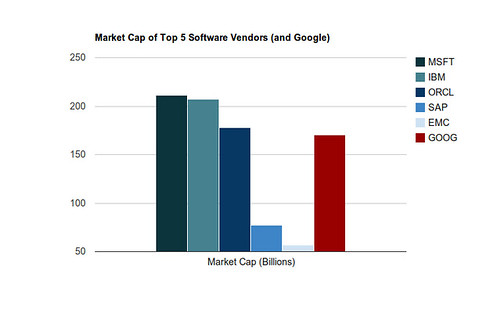
Google is not included on PwC’s Top 20 software vendors by revenue, presumably because they are not primarily in the business of selling software. If we were to compare their market cap, however, to the top five vendors on the PwC list, they would place fourth, just behind Oracle.
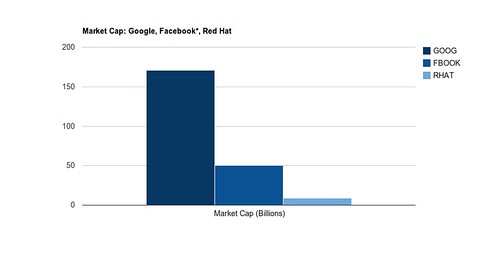
This is important both because Google is not, fundamentally, a software company and because they are comparatively young. Here is the largest and best performing open source software vendor, Red Hat, compared to Facebook and Google (Facebook’s valuation is based on the aborted Goldman private offering).
It is possible that valuations of the internet firms are artificially inflated because we’re in a bubble. But it is a fact that it has been twenty-two years since a Top 20 software vendor has been founded.
The data is clear: while there is substantial money in software, the difficulty of employing it as a primary revenue mechanism is increasing. This supports our observations of generational shifts in attitudes towards the importance of software [coverage]. In short, we recognize four basic generations of software producers.
- First Generation (IBM) “The money is in the hardware, not the software”:
For the early hardware producers, software was less interesting than than hardware because the latter was harder to produce than the former and therefore was more highly valued, commercially. - Second Generation (MSFT) “Actually, the money is in the software”:
Microsoft’s core innovation was recognizing where IBM and others failed to the commercial value of the operating system. For this single realization, the company realized and continues to realize hundreds of billions of dollars in revenue. - Third Generation (GOOG) “The money is not in the software, but it is differentiating”:
Google’s origins date back to a competition with the early search engines of the web. By leveraging free, open source software and low cost commodity hardware, Google was able to scale more effectively than its competitors. This has led to Google’s complicated relationship with open source; while core to its success, Google also sees its software as competitively differentiating and thus worth protecting. - Fourth Generation (Facebook/Twitter) “Software is not even differentiating, the value is the data”:
With Facebook and Twitter, we have come full circle to a world in which software is no longer differentiating. Consider that Facebook transitioned away from Cassandra – a piece of infrastructure it wrote and released as open source software – for its messaging application to HBase, a Hadoop-based open source database originally written by Powerset. For Facebook, Twitter, et al the value of software does not generally justify buying it or maintaining it strictly internally.
The question, as I asked the audience last week at the Open Source Business Conference, is what this means for those in the commercial software business. The answer, from my vantage point, is simple: they need to begin leveraging data alongside their software. As we’ve been saying since 2007 [coverage].
In a very real sense, software is becoming a vehicle for generating data; a means rather than an end. Open source software vendors are universally poor at customer conversion. The best of them converts one out of a thousand users into a paying customer. What they give up in conversion, however, they gain back in distribution. Open source software enjoys intrinsic advantages over commercially licensed alternatives with respect to its ubiquity. Until they begin harnessing this distribution in the form of data aggregation, however, this advantage will remain underleveraged. Which is unfortunate because it is a model that inherently better aligns customer requirements with vendor needs.
Because the majority of open source commercial revenue at present is derived from support and service contracts, customers are effectively paying vendors for services they hope not to need. By collecting, aggregating and analyzing anonymized customer telemetry (i.e. non-transactional data), vendors could supply customers with insight they would be unable to obtain from any other party. A potentially compelling proposition.
Contrary to assertions otherwise, then, the argument is not that software companies are dead. The evidence does not support, and in fact contradicts, such a claim. The evidence does suggest, however, that those startups that wish to get big, in the Apple sense if not the Exxon, should begin leveraging collected data as a complementary revenue stream. Software support and services alone hasn’t produced a Top 20 revenue earner in over two decades, and doesn’t appear poised to anytime soon.
The Age of Software was fun. Welcome to the Age of Data.
Disclosure: IBM, Microsoft, and Red Hat are RedMonk clients. Apple, Exxon, Facebook, Google, and Twitter are not.
* My OSBC talk articulated the fact that it was the PwC Top 20 that were all founded pre-1989, the post was less clear. This has been corrected.
