“Recall that DNA transmission among single-celled bacteria and viruses is far more promiscuous than the controlled vertical descent of all multicellular life. A virus can swap genes with other viruses willingly. Imagine a brunette waking up one morning with a shock of red hair, after working side by side with a redheaded colleague for a year. One day the genes for red hair just happened to jump across the cubicle and express themselves in a new body. It sounds preposterous because we’re so used to the way DNA works among the eukaryotes, but it would be an ordinary event in the microcosmos of bacterial and viral life.”
– The Ghost Map, Steven Johnson
Bacteria – viruses too – evolve more quickly than do humans. If you’re reading this, that should not be a surprise. The precise mechanisms may be less than clear, but the implications should be obvious. Part of their advantage, from an evolutionary standpoint, is scale. There are a lot more of them than us, and each act of bacterial reproduction represents an opportunity for change, for improvement. Just as important, however, is the direct interchange of genetic material. As Johnson says, it sounds preposterous – absurd, even – because we are used to linear inheritance, not peer to peer.
We see a similar philosophical divide in between those who abhor the forking of code, and those who advocate it.
Examples of the former abound. The fear of forking remains rampant in spite of the rise of Git, Mercurial and the other decentralized standard bearers. Perhaps because instantiations of Git and its decentralized brothers, for all of their popularity amongst the developer elite, remain heavily outnumbered by the legacy version control alternatives. Looking at Ohloh, for example, which indexed better than 238 thousand projects, we see the following traction for individual DVCS systems (note that I’ve conflated the Svn and Svnsync numbers in the original graph).
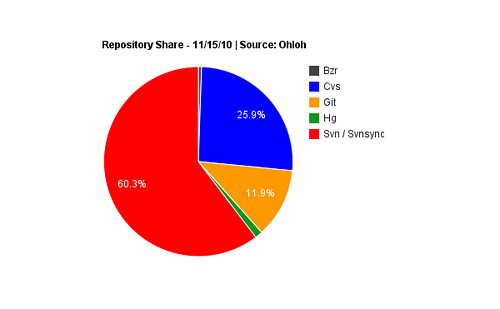
Interesting, but the specificity of this graph is counterintuitively working against us, telling us less than it could about the larger adoption trend. Let’s look at the same data, but filter by repository type rather than repository name.
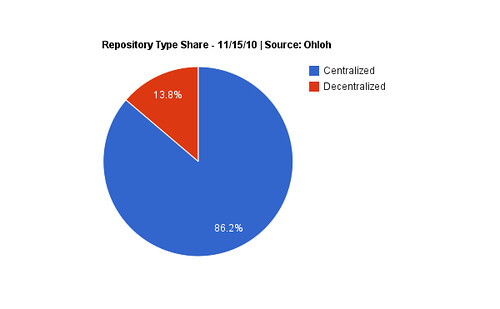
This is more clear: centralized repositories still dominate the market. Provided that we assume that this dataset is representative of the wider version control landscape. And while the sample size is more than adequate, there are actually caveats to this data: Github, for example, is not indexed by Ohloh to the best of my knowledge. Of course, neither are the countless inside-the-firewall CVS deployments at enterprises all over the world. In short, while the data is by necessity imperfect, it can be used for making educated guesses at adoption. That centralized tooling significantly outnumbers decentralized alternatives seems to be a safe conclusion; the uncertainty lies rather in how big the lead is.
Also, how long that lead will last.
Because the more logical explanation for the fear of forking doesn’t lie in the relative scarcity of distributed version control: it is nothing more or less complicated than the fact that it is a fundamentally different way to develop software. Doubtless its champions would cringe at the comparison, but development with DVCS tools has more in common with how bacteria reproduce than with humans: forking promotes distributed, peer to peer evolution, in which many copies evolve more rapidly than a single one could linearly.
As has been pointed out in this space before, even smart people struggle initially with the concept of distributed development. “I don’t believe in it,” is what an otherwise pragmatic CTO type of a major exchange told me a few weeks ago about distributed version control generally, Git specifically. “My developers work next to each other – they keep bugging me about it – but if we had branches everywhere we’d be stepping all over each other.” This remains, for better or for worse, the majority opinion in the enterprise. But the enterprise isn’t the only one with trust issues when it comes to decentralized development. Here, for example, is Brian Aker – a believer in active forking – on the subject:
On a related note there was a recent phone call that O’Reilly put together with a number of open source leads. It was amazing to hear how many folks on the call where terrified of how Github has lowered the bar for forking. Their fear being a loss of patches. It was crazy to listen too.
Joel Spolsky captured perfectly the disconnect that even smart developers can have when initially trying to wrap their minds around a Mercurial:
My team had switched to Mercurial, and the switch really confused me, so I hired someone to check in code for me (just kidding). I did struggle along for a while by memorizing a few key commands, imagining that they were working just like Subversion, but when something didn’t go the way it would have with Subversion, I got confused, and would pretty much just have to run down the hall to get Benjamin or Jacob to help.
When developers arrive at that point in the DVCS learning process, there seem to be essentially two paths forward. The easier is to give up. Lick your wounds and retreat to Subversion if you’re lucky, CVS if you’re not. The harder thing to do is to try again. To trust that the growing if still nascent traction for DVCS tools will more than offset the initial discomfort with the model. Typically, this leads to an epiphany, which arrives in two parts. First, you realize that DVCS enabled forking isn’t bad. Core to this phase is the realization that an increasing number of successful open source projects are by choice built using distributed version control systems. Riak has been DVCS from day one, only recently migrating from Bitbucket (Mercurial) to Github (Git). Speaking of GitHub [coverage], they’ve got a few projects you’ve probably heard of: jQuery, Memcached, MongoDB, Redis, Rails, and the Ruby language itself. Git, for its part, was originally written to manage the development of the Linux kernel. Developers are smart: once they’re better acquainted with this history, it becomes harder to sustain the mindset that distributed version control is somehow wrong. If it was, the continued traction would be improbable.
From there, deeper experience triggers the realization that DVCS tools are good. Great, in fact. That distributed development, and the friction-less forking it enables, is actually a real positive for development speed. Spolsky went through just such a conversion, and would up convincing himself that decentralized development “is too important to miss out on. This is possibly the biggest advance in software development technology in the ten years I’ve been writing articles here.”
Technology is, more often than not, a pendulum: swinging back and forth between extremes [coverage]. This is not the case with version control software. It is possible – likely, from a historical standpoint – that distributed tools such as Git will be themselves replaced by as yet unforeseen source code management tooling. But we will not be going back in the other direction. The advantages to distributed development are too profound to be abandoned. Organisms that evolve more quickly adapt more quickly, and Darwin tells us that organisms that adapt more quickly survive. Distributed source code tools are proving this true in code every day.
In other words, it might be time to get over your fear of forking.

Brian Aker says:
November 16, 2010 at 3:05 pm
Hi!
Since I made that comment there is one new observation I have made. GitHUB has begun to feel like the Sourceforge of the distributed revision control world. It feels like it is littered with half started, never completed, or just never merged trees. If you can easily takes changes from the main tree, the incentive to have your tree merged back into the canonical tree is low.
You can look at it in either two ways.
If you count up all of the hours and energy going into abandoned trees then you begin to worry about “all of that wasted work”. It takes a lot of effort to keep projects going, and if all new energy is focused in this direction I don’t know that we can keep a sustainable amount of focus to produce the sort of software that we do today. While consulting this last year I’ve run into a number of shops where a developer has made changes to an open source project, and placed these into production without any vetting (and in most of these cases they had a github/launchpad/etc sort of tree, or they pulled from some random person’s tree). They didn’t use a released piece of software, and often the code they had used was just thrown over the wall by some devs in some other company. It is the “we hired a smart guy who tinkered with our debian distribution/kernel” problem all over again.
The other way to look at it, is that Github/Launchpad are today’s Burgess Shale. We are in the equivalent of a cambrian explosion and the diversification we are seeing is similar to what we saw when Sourceforge first launched. If this is the case then we will see some stabilization in the next few years. In the database world, we are certainly in the middle of one of these periods.
If I put all of this into perspective and apply it to the MySQL Ecosystem, I fully believe that the forking we saw was enabled by the move to bzr/launchpad. Without that move it would have been a lot harder to make that shift for most of the forks and distributions (and I believe it has also slowed down the evolution of most, since almost all of the forks/distributions are heavily tied to downstream changes that Oracle makes). Beyond Drizzle, none of the other forks have any significant contributions, and they are all stuck waiting for Oracle to fix bugs for them and/or hoping that the changes they make don’t conflict with what Oracle is doing.
Cheers,
-Brian
sogrady says:
November 16, 2010 at 3:43 pm
@Brian Aker: from the original post, it’s probably clear which side I come down on. The concerns you note are very real: more code doesn’t just introduce maintainability and discovery problems, it means that production deployments must be even more rigorous. Not just “what are you putting in production,” but “which version,” and “what’s been applied to that version.”
In one sense, this is nothing new, because the availability of source has permitted such tinkering for quite some time. The proliferation of versions that we’re seeing from the accelerating use of DVCS systems, however, throws additional fuel on this fire.
As in most cases, it becomes a question of cost/benefit. Do the costs – the aforementioned challenges on the development and consumption sides – outweigh the benefits, or vice versa?
My opinion, based on the evidence I have at my disposal, is that DVCS is provably a net benefit. Besides comments such as Linus’ which reflect on the ability to develop certain projects of software only with distributed version control software, there are the volumes of shared experience – and project commitments – to the technologies.
What this means will necessarily vary on a project by project basis, and it may mean that not every project should consider DVCS migration. It definitely means, however, that project dynamics will be substantially more fluid in the years ahead.
Brian Aker: O’Grady’s Fear of Forking, Let a thousand flowers bloom | Weez.com says:
November 16, 2010 at 4:09 pm
[…] the article “Fear of Forking” there was a quote pulled from me about my observations from a yearly call done by the folks at […]
Brian Aker says:
November 16, 2010 at 4:52 pm
@sogrady I’m all in favor of distributed revision control. If BZR/Mercurial/Git had not appeared I would have stuck with Bitkeeper.
I believe that for companies making a business off of developing open source software, that DVCS is a double edged sword. DVCS creates an environment that is friendlier to contributors, I believe this has been established in an overwhelming way by now. Software coming from a single central repository systems is a lot harder to fork and maintain. Far from impossible, but the workload goes up by a lot.
What does this mean for the hybrid open source projects? I believe that if Postgres had moved to a DVCS system earlier, that some of the commercial vendors in that ecosystem would have had an easier path to contribute back to the project (in addition to the social, and code quality issues).
You are right that being able to modify code and put it into production is nothing new, that is a benefit of open source. What I am seeing though is a willingness to do it and try to maintain it, and that trend I believe may have some unfortunate consequences for most companies. There will be lessons that will need to be turned into policies so that organizations don’t find that they are orphaned on unknown branches.
I can’t imagine going back to world to the world of the single central repository.
Links 17/11/2010: Chrome OS and Android Explained, Linux 2.6.37-rc2 | Techrights says:
November 17, 2010 at 4:21 pm
[…] Fear of Forking Bacteria – viruses too – evolve more quickly than do humans. If you’re reading this, that should not be a surprise. The precise mechanisms may be less than clear, but the implications should be obvious. Part of their advantage, from an evolutionary standpoint, is scale. There are a lot more of them than us, and each act of bacterial reproduction represents an opportunity for change, for improvement. Just as important, however, is the direct interchange of genetic material. As Johnson says, it sounds preposterous – absurd, even – because we are used to linear inheritance, not peer to peer. […]
Josh Berkus says:
November 22, 2010 at 2:21 am
Stephen, Brian,
PostgreSQL recently threw the switch for our final move from CVS to Git. You know what? It was a relief. It allowed our tools to support the development which was already going out.
The thing a lot of CTOs don’t seem to understand is that developers are actually doing parallel development in their organization already. If they’re stuck on SVN/CVS, they’re just doing it via private folders and copy-and-paste. That’s a far worse situation than branching & forking; it means that, if a developer’s laptop dies, some of his code is lost forever. And it means that lines of development which stall suffer horrible bit-rot and have to be rewritten for inclusion in the next next version.
This is difficult for executives to grasp because they operate under the illusion that their dev team is a “well-oiled machine” with everyone working in the same direction at the same time. Nothing could be further from the truth, but it’s very hard to tell them that.
No question it was hard for me to get used to merges and rebasing and Git’s esoteric command syntax. But once I did, I realized that this was how I’d always thought of our team’s code, I’d just never been able to make my VCS do it before.
Mark says:
November 22, 2010 at 4:28 pm
A comment on your analogy: forking and merging via a DVCS is actually
closer to recombination (e.g., sex in human populations) than horizontal
transfer (e.g., exchange of pathogenicity genes among evolutionarily
unrelated bacteria). The reason for this is that recombination takes
place in the context of a common ancestor, such that benificial mutations
unique to each parent can generally be combined additively — file
level merges are usually easy to resolve by combining bug fixes at different
locations in otherwise identical code; forks that add new files/modules
are trivial to merge as long as the parents have not diverged the overall
architecture/API. If forks evolve through many commits without merging,
then code and API may drift enough to make merges more difficult, in the
same way that reproductive isolation of a population will lead to speciation.
Horizontal transfer, on the other hand, can take place between two species
with no recent common ancestor. The transferred module must, therefore,
be relatively self-sufficient (e.g., a virulence cassette), and there will
be fewer degrees of freedom for combining useful features from both parents
(this is akin to, e.g., lifting some zlib functions and tuning them for the
needs of your own code base).
So, great article, but I think that the distributed model is actually closer
to human biology than you think =)
Pat says:
November 25, 2010 at 6:10 am
I think you missed a key point.
Assuming,
* the original developer(s) of an open source project are familiar with SVN,
* are checking in their project to sourceforge.net (SVN)
* their project is not a heavily used / contributed to by outsiders (i.e. the vast majority),
* learning git, finding various git tools for things like merge, understanding git takes time
Thus,
* Any outside contributions are easily applied by the original developers using SVN,
* If the original developers abandon the project, it is unlikely that they care enough about the project’s continuation to incur the cost to switch to git,
* the likelihood of outside developers wanting to adopt the project is low ( low traffic when the project was more active)
Therefore,
* It is likely then that the project’s original developers will realize no net benefit to switching to git, et.al.
* The cost of switching to git, et.al. is incurred by the original developer with an uncertain benefit to the original developer.
* the *potential* cost of not switching to git, et.al. that is incurred by the outside community is higher ( because the project has a higher like being completely abandoned ) However, the project may not be worth continued development.
So while the “fear of forking” may be voiced I suspect it is a variation of fear of someone else getting rich from a developer’s “1337” code and not sharing.
Robert Hodges says:
November 28, 2010 at 5:17 pm
We don’t use DVCS in our Java projects but the reason is more prosaic than fear of forking: Eclipse plug-in support is pretty shaky for anything other than CVS and SVN. As soon as DVCS plug-ins get better and we are confident we can merge without getting confused and/or corrupting source we’ll move.
I, for one, welcome our new Android forking overlords says:
January 27, 2011 at 12:37 pm
[…] of technology and ideas. Forking allows for a biological metaphor for systems design. As Stephen explains: Bacteria – viruses too – evolve more quickly than do humans. If you’re reading this, that […]
Announcing MepSQL, continuing the "Cambrian Explosion" of MySQL forks | OpenLife.cc says:
February 10, 2011 at 4:01 pm
[…] Some time ago Stephen O'Grady and Brian Aker had an interesting Blogo-dialogue about what they call the "Cambrian Explosion" of […]
Forking: Development Coordination Technique or Project Correction Tactic? | Apprenda says:
February 4, 2014 at 11:07 am
[…] “I don’t believe in it,” is what an otherwise pragmatic CTO type of a major exchange told me a few weeks ago about distributed version control generally, Git specifically. “My developers work next to each other – they keep bugging me about it – but if we had branches everywhere we’d be stepping all over each other.” (Read more here) […]