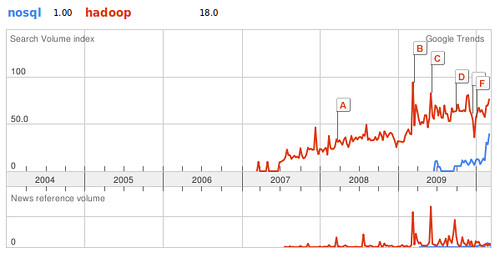
The simplest reason to pay attention to Hadoop is this: interest in non-relational approaches has never been higher than it is today. Whether you lump Hadoop into the NoSQL bucket then or not – Mike Olson, for one, does not – the growing popularity of both speak to the demand for data processing tools that are not relational databases. The trendline is clear.
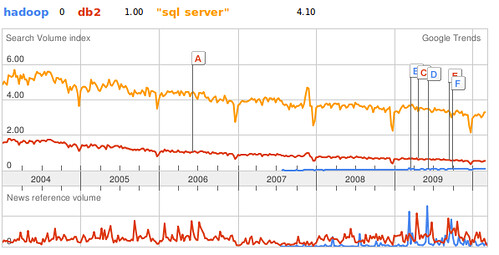
Not that this is a zero sum game, mind you. Relational databases (and filesystems, to be fair) have been the foundation for data persistence for decades, and their dominant role in application development is not likely to be threatened in the near future. Witness the popularity of Hadoop searches via DB2 or SQL Server (Oracle is too generic).
What is likely over, however, is the default assumption that if data must be stored, it must be stored in a relational database. “RDBMS is the answer, now what’s the question?” was always an antiquated notion, and it’s been rewarding to see our 2005 prediction that we’d see better diversity at the data layer (finally) coming true. Different tools for different jobs.
And for the job of processing large amounts of data, with linear scaling horizontally, it’s difficult to imagine a better tool than Hadoop. The brainchild of Doug Cutting, then with Yahoo now of Cloudera, Hadoop is a framework or set of components that draws on Google’s MapReduce and Google File System approaches to permit large scale computation. Which all sounds very impressive, but what does it mean to business people? For one enterprise user, it means getting an answer to a query in 13 minutes instead of a month: that’s the kind of efficiency that becomes possible with the Apache project.
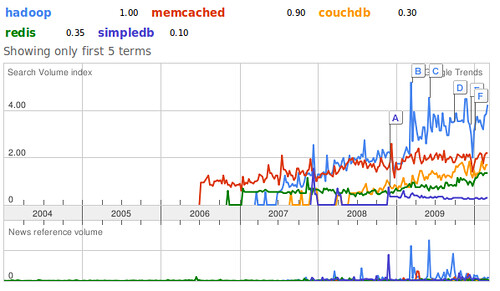
Of a few of the major non-relational projects that one might consider, Hadoop is demonstrably the most popular at the current time (projects like Cassandra and Voldemort were excluded for the obvious problems they present in terms of their search popularity).
Which is why it’s been no real surprise to see IBM embrace Hadoop. While some relational database vendors are Hadoop skeptics, Microsoft most notably, IBM’s been relatively aggressive in leveraging the project. Not at the expense of its traditional relational product set, but as an alternative for certain types of workloads.
The man spearheading the Hadoop charge at IBM has been Rod Smith, VP of Emerging Technologies, which was why we wanted to get him on camera. Given that I’ve been following his Big Sheets application with interest since Hadoopworld, we were pleased to be able to catch up with him for a couple of interviews during a recent trip to Boston.
If you’re interested, then, there are two videos below. The first is a bit more business focused, the second slightly more technical. In them we talk about Hadoop, obviously, but projects from Dumbo to Pig, IBM’s Big Sheets and the work done at the British Library, and Big Data more generally.
I’ll have more thoughts on the future of Hadoop shortly, though you get some of that in the interviews. In the meantime, enjoy.
IBM and Redmonk talk business about Hadoop and Big Data
IBM and Redmonk talk tech about Hadoop and Big Data
Disclosure: Cloudera, Microsoft and IBM are RedMonk customers, and IBM sponsored the above videos.
