As long as we have been tracking the Kafka project, it’s been a force of nature. Originally written at LinkedIn over a decade ago by a team including Jay Kreps, Jun Rao and Neha Narkhede who subsequently left to commercialize the product at Confluent, Kafka was and arguably remains a highly differentiated data platform. Unlike traditional relational databases or similar data stores, Kafka was created to handle high volume streams of writes. With the high growth and rapid decentralization of infrastructure since it was created, streaming platforms are, if anything, even more fundamental today than they were a decade ago.
For the most part, the project has defined the streaming space. There has been Kafka and then there’s been everything else. It managed to achieve MySQL-like ubiquity in the space, and is invariably the first project discussed when the topic of streaming is raised.
Recently, however, chatter concerning a Kafka alternative has begun to pick up. For the first time in recent memory, the streaming conversation doesn’t begin and end with Kafka. Increasingly, its fellow Apache project Pulsar is talked about as a competitor, an alternative and – in some cases – a replacement.
Given this shift, the logical next step was checking on some of the rough metrics to get a sense for how the projects compared in terms of discussion, visibility and contributions.
First up was Stack Overflow.
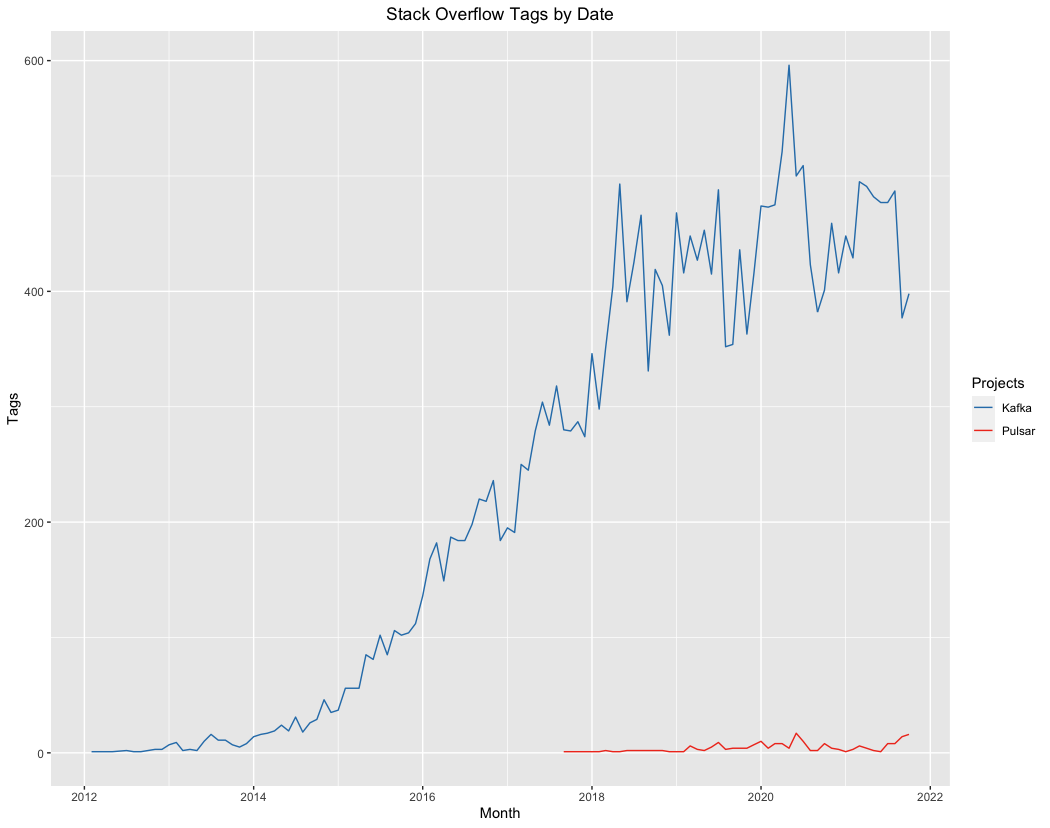
(click to embiggen)
As expected, Kafka dominates this comparison. First, because the project has been successful, but more importantly because it’s been available for a much longer period of time. Kafka was announced as a top level Apache project in October of 2012; Pulsar didn’t achieve that distinction until September of 2018. But that six year headstart notwithstanding, Pulsar’s lack of discussion here is mildly surprising given that the project’s own contact page directs users to Stack Overflow.
Looking at non-developer specific visibility, Pulsar doesn’t fare much better on Google Trends.
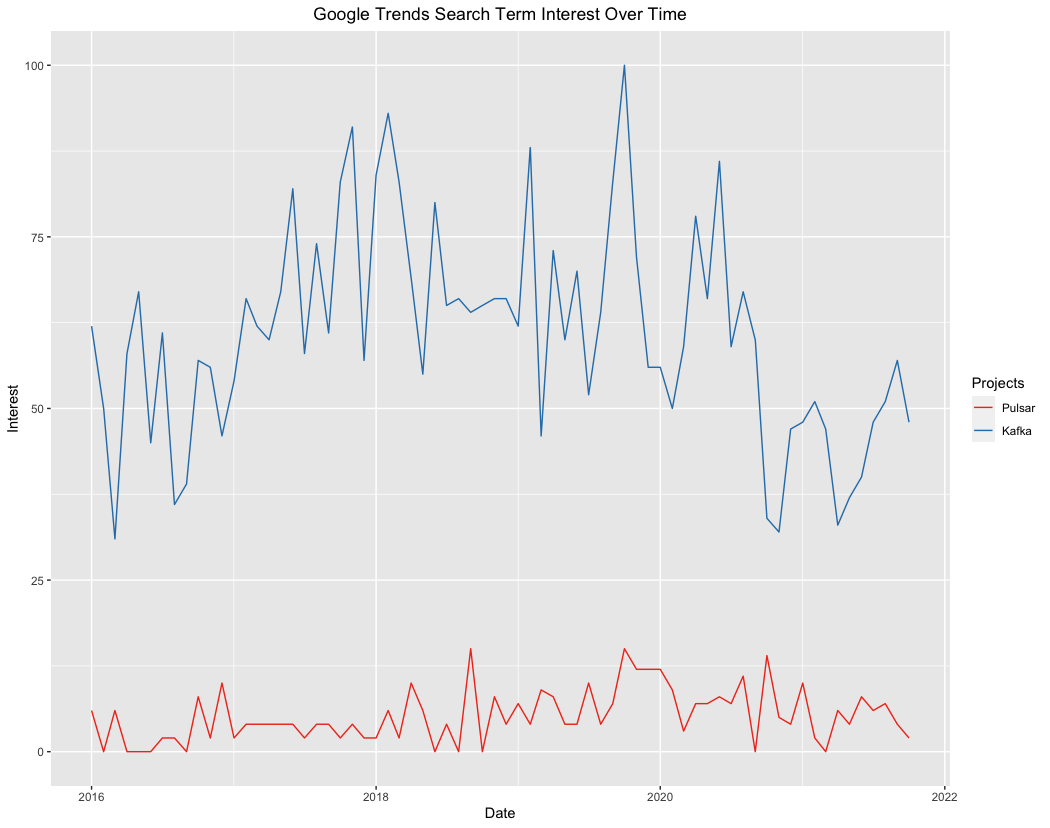
(click to embiggen)
To compare apples to apples these are measured as search terms, and they were both queried with Apache to distinguish the results from alternative meanings. Kafka handily outperforms Pulsar here. Some of this undoubtedly is a function of Kafka’s outsized visibility and age, of course, but whatever the causative factors Pulsar is substantially less discussed than its counterpart.
Kafka clearly still owns most of the public discussion metrics, but the star count on GitHub was a little more interesting.
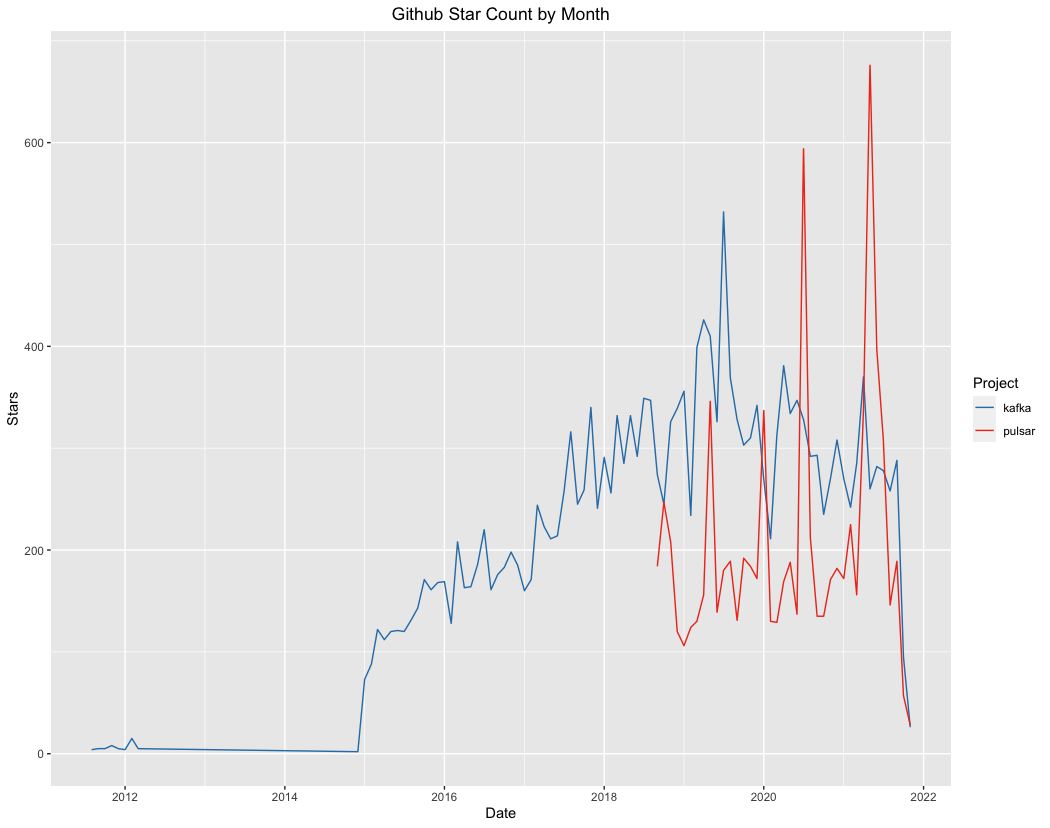
(click to embiggen)
Note that the measures here are of the mirrored Apache repositories on GitHub. What we can see is gradual growth for Kafka while Pulsar starts at a high level. It’s also interesting to note that the two highest starred months over the surveyed period – 676 stars in May of 2021 and 594 in July of 2020 – belong to Pulsar.
Stars are a very rough proxy for project interest, but it’s possible that the performance here is an early indicator of growing interest in Pulsar.
The data around commit counts is likewise notable.

(click to embiggen)
With the obvious caveat that commits are obviously not all created equal and that project quality and merit can be measured by neither lines of code nor contributions, it’s nevertheless interesting how quickly contributions to Pulsar have ramped up to a level that remains shy of Kafka but certainly competitive.
All of the above metrics, to be sure, are to be taken with a grain or three of salt. But that data is suggestive that the current uptick in chatter around Pulsar is not idle, but rather fueled in actual developer interest and contributions.
The next step, presumably, for advocates and users of the project such as Databricks, Datastax or Splunk (via Streamlio) is to address some of the projects current shortcomings in visibility by making some of the behind the scenes progress and work more apparent. It will be interesting to follow these metrics over the months ahead to get a more accurate read on whether Kafka finally has some worthwhile competition or whether it will remain the single, and often only, project mentioned when streaming is the subject.
Disclosure: Datastax and Splunk are RedMonk clients. Confluent and Databricks are not currently clients.
