The biggest question for those looking at containers over the coming year is going to be how to deploy and orchestrate containers at scale. While this is a multifaceted problem two parts of the equation are particularly interesting. Firstly we have continuous integration, a topic I will be touching on frequently. Secondly we have the question of deployment, scaling and orchestration.
For the latter, a number of solutions and approaches are emerging, but the project currently grabbing most of the headlines is Kubernetes. Given that the project is just over a year old, its rapid growth in mindshare has been very impressive.
The announcement of the Cloud Native Foundation at Oscon, and the contribution of Kubernetes as a seed technology, shows a commitment from Google to help Kubernetes become a very widely accepted technology. Leaving aside Google’s own commercial reasons for getting people interested in GCE, the various organizations involved in the Cloud Native Foundation all have their own vested interests in getting Kubernetes to run well on their platform of choice. For developers this is ultimately a good thing, as it will provide a level of portability and greater choice in the longer term.
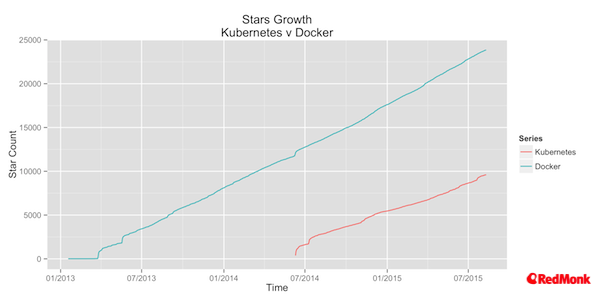
Taking github stars as an indication of interest, the growth of Kubernetes been very strong over the last year, and it has a trajectory that is pretty comparable to that of Docker.
Contributions and Issues
One of the statements that Google are very fond of rolling out is that the number of contributors to Kubernetes 1.0, at 400. While a true statement, it is far more interesting to look at the percentage of contributions via commits and issues by the top ten contributing companies versus all other contributors. 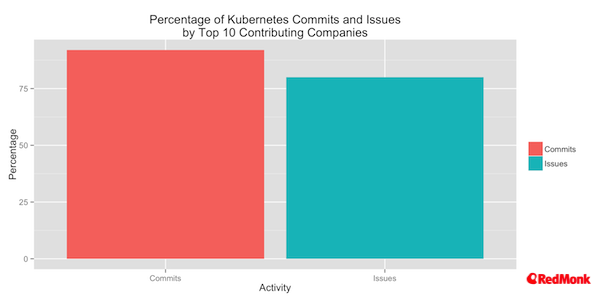
As we can see, the top ten companies contribute over 90% of the commits, and open almost 80% of the issues.
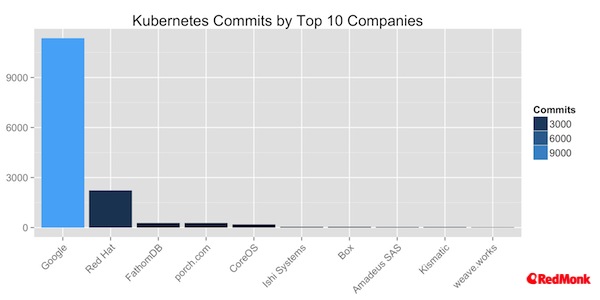
Looking at the commits in more detail we see that Google, as one would expect, followed by Redhat, dominate the direct code contributions to the Kubernetes project.
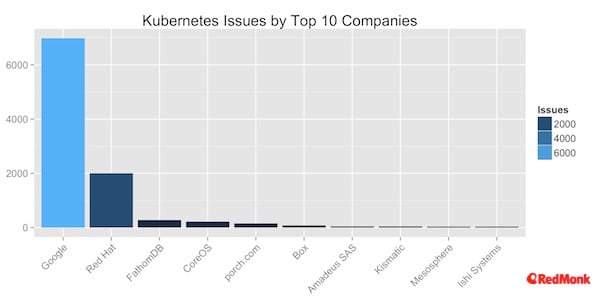
Doing a comparison on issues we see a very similar trend as expected.
What is a contribution?
One significant piece of data we are missing here is the impact of advocacy on the growth in both interest in, and usage of, Kubernetes. While most documentation changes are caught on Github, correlating the impact of people speaking at conferences, meetups and so forth is much harder.
Kelsey Hightower at CoreOS rightly highlighted the fact that github only stats do not reflect advocacy and teaching on twitter a few weeks ago. Personally, I strongly agree with Kelsey on this point. A large part of the success of Linux can be put down to advocacy and community, rather than direct contributions. Trying to put some reasonable metrics around the impact of advocacy is an area I plan to focus on over the coming months (suggestions very welcome!).
Upcoming?
The next few months are going to be interesting to watch as we see the various commercial offerings emerge around Kubernetes. Google will continue to lead the code contributions, but we should expect increased contributions from other companies and the interplay with CI will only grow, companies such as Cloudbees are already doing interesting work in this area and we can expect others to follow.
Disclosure: RedHat, CoreOS and Meteor (owners of FathomDB) are current RedMonk clients.
Top 10 links for the week of Aug 10 - HighOps says:
August 15, 2015 at 7:58 am
[…] The Rapid Evolution of Kubernetes […]
The History of Containers | Red Hat Enterprise Linux Blog says:
August 28, 2015 at 1:41 pm
[…] the past year, Red Hat has contributed substantially to Kubernetes in various areas, as we work to bring the concepts of atomic, immutable infrastructure to […]
Driving the state of the art. Cloud natives and the appliance of science - Enterprise Irregulars says:
March 17, 2016 at 12:58 pm
[…] But by 2015 Google realised that open sourcing the code itself, rather than just publishing papers about its approaches, made sense. Why watch somebody else create another Hadoop or Mesos when Google could build a community around stuff it actually built – and so Kubernetes was born. Things got really interesting when Google’s engineers met engineers at Red Hat they deeply respected. When we write the history of Google this will be seen as a seminal moment, when the appliance of science became properly a community-based activity. The decision to open source some of Google’s core machine learning technology – TensorFlow – followed naturally on the obvious and growing success of a better, more collaborative model for applied science. […]