For the better part of twenty years, Microsoft Excel has been the most popular spreadsheet application on the planet. In a very real sense, it is the driver of Office revenues, because while office workers will use alternatives to Powerpoint and Word, you can pry Excel from their cold, dead fingers.
So how do you replace it?
You don’t. Many have tried. All have failed. Excel has, at least as measured by marketshare, been chewing up and spitting out competing products for well over a decade.
The best strategy in competing with Office generally, as evidenced by the success of Google Docs, is to reframe the debate. To compete where Office does not. As Sun Tzu tells us, “You can be sure of succeeding in your attacks if you only attack places which are undefended.”
But what territory, precisely, has Excel left undefended? It’s the gold standard for analysts the world over, and it’s actually somewhat frightening how many businesses are run purely on top of it. Excel isn’t online yet, but it will be and even if it doesn’t get there, Google Docs did. So that’s out. Leaving what?
How about big data?
Excel has been used on big data for years, it’s true. But not directly on big data. With a row limit of around 65,000 [Update: Mike Cullina writes in to say the 65K limit was eliminated in the last release, 2007 – the new limit is 1M plus], it certainly can’t be used as a direct window into data warehouses or marts. So instead analysts use it to front end views or other subsets of the original dataset. Which, by the way, has probably been heavily cleansed and normalized.
Want to ask questions of the entire dataset? Or of datasets, plural? Terrific. Learn SQL, find and be very nice to a DBA, and beg for the access you need. Also, be prepared to wait days or even weeks for your answer. Working on big data is hard, remember.
Unless you have a new back end, one designed to reduce complicated questions into a set of tasks that can be individually executed on multiple machines. A back end like Hadoop.
The good news about Hadoop, you’ve already heard: it’s very, very good at carving up large workloads when you can supply it with adequate hardware. The bad news, however, is that the front ends for the tool are, to put it charitably, a bit behind. See this slide from Kevin Weil’s presentation at NoSQL East
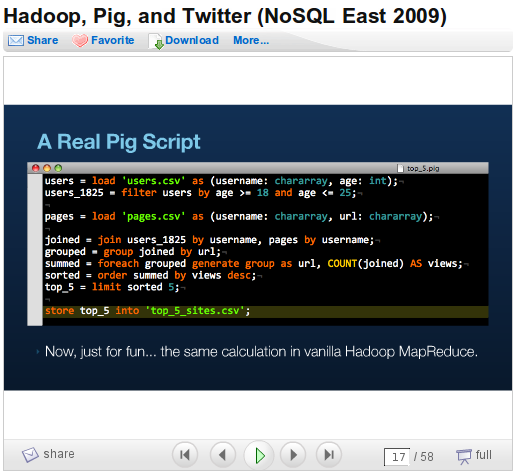
And that’s the simple interface. Anybody who knows SQL is in good shape, but I think it’s safe to say Hadoop is just a tad less accessible to analyst-types than Excel.
Which is where IBM’s Big Sheets comes in. Called M2 at the time of Rod Smith’s presentation from HadoopWorld, you can think of it as a spreadsheet-like front end (with elements of DabbleDB, ManyEyes, and others) for Hadoop datasets.
If you can’t see the promise in the slides, just wait for the video from HadoopWorld. Or just trust me: Big Sheets is the real deal, and the shape of things to come. Maybe it’ll be Big Sheets, maybe something totally different: the concept is real.
Should Microsoft be worried? Not in the short term. Excel is near perfectly adapted to its environment, and is in no danger of being replaced by an alternative, whether that’s Big Sheets, Google Docs or OpenOffice.org Spreadsheets. But environments are not static; they have a way of changing, and it certainly appears that we’re in the midst of a change now.
Data hypergrowth has pretty much become a cliche at this point: how many times can you hear “we’re going to produce more data in the next [small time period] that we have in human history” before you stop hearing it? Less apparent, however, has been the impact on individual analysis. Take the Twitter datasets recently released by the Infochimps guys: the monthly base tab separated values spreadsheet is 1.7 GB. The hourly version, it can be assumed, is a bit larger.
Point being: a lot of us are going to be working with large datasets soon, if we’re not already. And while the current toolset of choice – Excel – has its strengths, that doesn’t happy to be one of them. So either it gets there, or someone goes island hopping beyond the most popular spreadsheet product in history and defines the user interface and experience for Big Data.
Adapt or die, as they say.
Disclosure: Both IBM and Microsoft are RedMonk clients; Google is not.
