
TL; DR: NVIDIA continue to focus on providing the software components to accelerate their hardware business. Operationalizing AI at scale is starting to look easier with Kubernetes support.
NVIDIA’s annual GPU Technology Conference (GTC) was held last week in San Jose, and we had the opportunity to attend. As always at GTC there was a lot to digest.
We noted last year that NVIDIAs overall strategy around AI is to provide a consistent underlying platform for enterprises to use their GPUs for AI workloads. This became one of the front and centre messages from NVIDIA this year, as the keynote focused on the notion of an AI Platform available as an on premises offering via hardware such as the DGX-2 and across various cloud providers.
The software strategy is pretty simple – invest a lot of engineering resources into doing the heavy lifting around the low-level infrastructure to provide a platform to build on top of. The growth in their datacenter business shows that this approach is paying off.
![]()
AI for Good – Project Clara

In an era where many conversations around AI are turning negative, NVIDIA highlighted what, to me, was one of the most positive uses for AI I have seen – Project Clara .
In a nutshell Clara is a project to augment existing medical imaging technologies. In the technology world we view most hardware and software as relatively disposable and iterative. The same is not true in an area like healthcare. Budgets are tight and imaging machines represent extremely significant long-term investment decisions for health administrators. Imaging technologies stay in place for decades and given the pressures on health services around the world the rate of replacement is not going to change.
Clara allows clinicians to take existing images (e.g. MRI or CT scans, X-Rays etc) and dramatically enhance them using GPUs. Augmentation of an existing technology rather than completely replacing it. Under the hood there is a lot of processing power being dedicated to the work, and the stated plans are to make this available as either a hosted service or on-premises where required.
Now there are all sorts of other implications, like records transmission and so forth. Regulators will cast a very close eye on how this technology is used, but these are solvable problems.
To my mind, this is one of the best augment and improve rather than replace use cases I have seen. It is also a practical example of using the Kubernetes and GPUs, a topic we will return to later.
Tensorflow & TensorRT
There is no doubting the popularity of TensorFlow among developers. It is significantly out pacing all other AI and ML frameworks in terms of developer attention at the moment. There is still a question as to how much of this is experimentation versus enterprise usage, but whatever way you dissect the numbers it is the most popular project in the space at the moment.
![]()
One of the biggest headaches for developers using Tensorflow at any significant scale for inference in recent times has been leveraging TensorRT. While definitely possible to use, the packaging experience was less than optimal, with additional steps required to leverage some of TensorFlows capabilities. With the 1.7 release of TensorFlow, NVIDIA and Google have worked together to integrate TensorRT fully with TensorFlow. This is exactly the type of packaging exercise we consistently encourage here at RedMonk. It reduces friction, and that in turn will accelerate adoption
Why does this matter? Inference is far cheaper than training, but it can still be expensive. TensorRT optimizes deep learning models for inference and creates optimized runtimes for GPUs. With the TensorFlow/TensorRT integration, TensorRT will optimize compatible sub-graphs in the model (if you want to dig in further here, there is a good starting point on graphs and subgraphs in the TensorFlow documentation).
Perf improvement, circa 8x on inference in @tensorflow with @nvidia #TensorRT integration – @nvidia Ian Buck #GTC18 #NVEnlighten https://t.co/PC42kZj3KO
— Fintan Ryan (@fintanr) March 27, 2018
TensorRT already had support for a number of other frameworks via ONNX, and the new TensorFlow support helps widen its reach even further.
Kubernetes & GPUs
Boom! @kubernetes on @nvidia GPUs #GTC18 #nvenlighten << been coming for a while, but this is significant
— Fintan Ryan (@fintanr) March 27, 2018
The headline grabbing announcement from the operationalizing AI perspective was NVIDIAs support for Kubernetes. The demo given was very cute, scaling workloads from some on premises hardware into the cloud and back again.
The jazz hands part of @kubernetesio & @nvidia gpu’s #gtc18 #NVEnlighten << some significant engineering in the details pic.twitter.com/NH4sYdQ09n
— Fintan Ryan (@fintanr) March 27, 2018
As always, the devil is in the details. GPU support for Kubernetes builds on the work done around device plugins within the Kubernetes community (and spearheaded by NVIDIA and Google). While the device plugin work is available in Kubernetes 1.10, it is still only in beta and users need to use the NVIDIA specific device plugin with the usual set of prerequisites for software at this stage of development, along with some caveats like understanding how many GPUs you will need in a pod and so forth.
But, and this is a key but, it is still very early days and we fully expect to see the entire experience packaged up it something far more consumable for end users.
NVIDIA do not want to be in the Kubernetes distro business. As we have noted on a few occasions this is a crowded market space, and there is little, if any, marginal value for NVIDIA to get involved in this part of the space. Given that, and the solid work that has gone in the device plugin space, we would expect to see the major Kubernetes distributions adding GPU support in the near future.
So the thought arises, how long for @awscloud EKS, @Azure AKS, and @GCPcloud GKE to get direct GPU support? #GTC18 #nvenlighten
— Fintan Ryan (@fintanr) March 27, 2018
However, the really big question for me is how quickly we will see GPU support arriving into Amazon EKS, Azure AKS and Google GKE, and how well these disparate offerings can be knitted together on the application and management plains.
As we have noted before access to all of these services, from a consumer/developer perspective, will be via a common interface. Could we see true cross cloud portability for GPU workloads within managed offerings?
Expanding the NVIDIA GPU Cloud
The NVIDIA GPU Cloud (NGC) was announced at last year’s GTC, and the underlying work has continued, with monthly updates to the deep learning containers and support now available for AWS, Google, Oracle Cloud and Alibaba.
Stat: 20K orgs using #containers from @nvidia GPU Cloud (NGC), 30 base containers, and now certified on @awscloud, @OracleCloud, @GCPcloud and @alibaba_cloud #gtc18 #nvenlighten
— Fintan Ryan (@fintanr) March 27, 2018
As the footprint of GPUs continues to expand across the cloud providers we anticipate the official support matrix expanding.
CUDA
CUDA is a core building block for NVIDIA, and its usage is a good proxy for NVIDIAs overall growth, with the caveat that download numbers in and of themselves are always subjective. Saying that, downloads doubled last year to a cumulative eight million in the ten years since CUDA was first released.
Stat: CUDA downloads of almost 4M last year #GTC2018 << doubling total to 8M, thats growth
— Fintan Ryan (@fintanr) March 27, 2018
We did raise a question around the CUDA 9.0 licensing changes, and there was an acknowledgement that the changes to terms could have been communicated far better. The underlying thinking has far more to do with the NVIDIA enterprise support matrix rather than anything else.
The Cambrian Explosion of Neural Networks
One area that NVIDIA were very keen to highlight was the growth, or Cambrian explosion as they prefer to call it, in the number of new models for neural networks. We had the opportunity to discuss this in significantly more detail with Will Ramey, NVIDIAs head of Developer Relations.
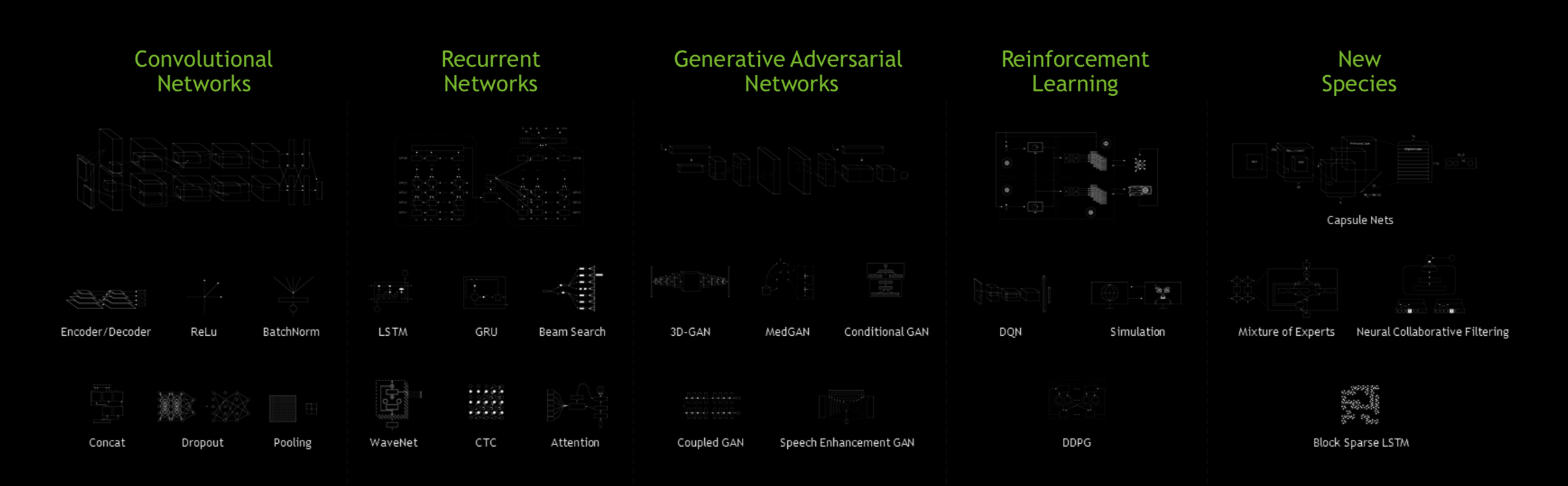
This is a layer at which NVIDIA can provide significant value. As specific patterns become more popular NVIDIA invest in providing tuned implementations of the kind of routines which occur in deep neural networks, specifically in cuDNN, which is available as part of the Deep Learning SDK. The focus here is exclusively on performance, and as these models become more frequently used at scale every optimization will help.
Ethics
Ethics featured again this year, and while CEO Jensen Haung was keen to talk about the responsibility of the technology industry in areas such as autonomous vehicles, especially in light of the tragic events a week previously, some of the wider issues were left unaddressed. It is clear Jensen is thinking about these things, it is less clear if his thoughts are yet cascading through the wider entire organisation.
The wider ethics and AI question was raised during one of the analyst sessions, and once again the answer essentially amounted to “we are a platform – that problem will need to be solved in the software above us”. Which is, sadly, the same answer as we got last year.
But to my mind it marks a significant moment with the CEO of a company like NVIDIA uses his keynote to talk about ethics. There is a long way to go across the entire tech industry, but every step forward is welcome.
Disclaimer: NVIDIA paid for my T&E. NVIDIA, Google, Amazon, Microsoft, Oracle and Red Hat are current RedMonk clients.
Darren Hague says:
April 24, 2018 at 11:31 am
“However, the really big question for me is how quickly we will see GPU support arriving into Amazon EKS, Azure AKS and Google GKE”
In the case of GKE this has been around for a month or two now, and even has Terraform support. I agree that we need to see it across the other cloud providers too – and who knows, even OpenStack?
Fintan Ryan says:
April 24, 2018 at 11:34 am
I should have clarified that I meant non-beta support, but it is a great to see it in GKE.