TL; DR: For event driven computing at vast scale serverless is what comes next, but it requires a massive shift in mind-set for many developers.
Introduction
Around eighteen months ago Amazon announced AWS Lambda, a framework which allowed you to execute simple pieces of code in response to specific events such as a file being uploaded to Amazon S3, an event stream or a request to an API gateway.
While many people understood the potential of Lambda, outside of some early adopters the overall reaction to Lambda was relatively, and to our minds surprisingly, muted. Most enterprises carried on what they were already doing, developers spun up infrastructure in they way they were already used to, and so forth.
In the meantime, however, some developers saw the opportunity, and started to use serverless at scale, for use cases such as event based triggers, data ingestion and one of the more obvious fits for Serverless – Internet of Things.
Although developer adoption is still only in its very early stages, Amazons competitors fully understand the potential of Lamba. In the first four months of 2016 we have seen competing frameworks announced by IBM (OpenWhisk), Google (Google Cloud Functions) and Microsoft (Azure Functions).
Infrastructure and Paradigm Shifts
To understand serverless we need to step back a little and think about the purpose of infrastructure, and the differing approaches that people can take. Cohesive Networks have written about the concept of going over the top or all in on infrastructure:
The New Dividing Line: “All-In” vs. “Over-the-Top”
The new split we are seeing is customers making a choice of going all-in on a specific cloud provider’s PaaS platform, or choosing to retain more direct control of their infrastructure by doing more of the infrastructure work themselves “over-the-top” of one or more cloud service provider’s IaaS platform.
At its heart cloud computing is an abstraction layer, and as an industry we do love our abstractions. With each abstraction it also becomes possible to offload this layer to someone else to manage. So fifteen years ago we all bought servers, five years ago we all bought VMs, now, well we still buy VMs.
People may manage VMs at scale, they may use autoscaling and many other wonderful techniques, but the underlying model and mindset is still essentially that of running servers for various tasks. Even with containers, most people are still ultimately thinking of the underlying infrastructure they will deploy containers on (be it Docker Data Centre, Kubernetes or another offering), although offerings such as Google Cloud Engine and AWS Elastic Container Service are changing this.
The serverless mind-set is very different. Developers need to let go of their servers and their infrastructure completely for a certain class of task and workload. The abstraction layer is far above where people traditionally think. In most cases you will also, ultimately, buy into the walled garden of services your serverless function(s) need.
Now as we have seen in the past going all in with a particular provider has its risks. The shuttering of Parse by Facebook, illustrated this fact in spades. But for many companies, and in particular many start-up developers we speak too, the idea of never having to think about any underlying infrastructure – having no devops teams, no servers of any kind – is incredibly attractive.
As Paul Johnson eloquently, and succinctly, stated:
Serverless is about no maintenance
Current Commercial Offerings
Currently, as with many things in cloud computing, the big beast is Amazon with AWS Lambda. The other commercial offerings of note are
In terms of overall completeness AWS Lambda and Azure Functions have an edge on the competition. The depth of integration points into other services provided in AWS and Azure, in particular to streaming and data, is very impressive and both offerings provide easy API access to allow developers to invoke serverless functions.
It is no coincidence that node.js is by far the most supported, and most used language, around serverless computing. JavaScript consistently scores highly in our programming language rankings, and the node foundation highlighted the level of IoT interest in their most recent survey:
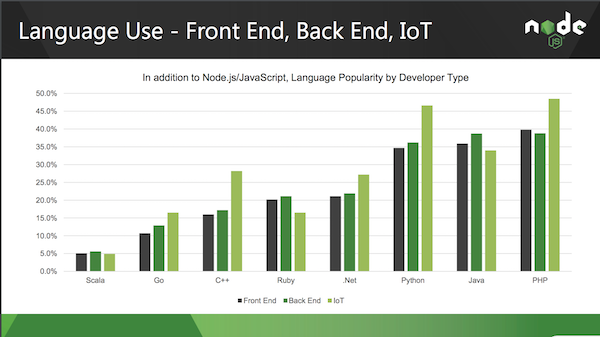
All of the commercial offerings support node by default. Support for other languages varies, with Microsoft having the greatest depth so far. We do expect to see more language expansion when sufficient demand arises, something already demonstrated by Amazon when they announced support for Python last year.
IBMs OpenWhisk offering supports running code in containers. In theory anything that can run in containers can be used. What this means in practical terms we have yet to fully understand, but it does provide some unique opportunities for differentiation.
With the commercial offerings we do need to circle back to the infrastructure question we raised earlier. As we mentioned, the aspect that makes serverless particularly attractive is the fact that you are not managing any infrastructure.
However, once you read past the marketing materials, only AWS Lambda and IBMs OpenWhisk offering via Bluemix remove the need for you to manage infrastructure. Both Azure Functions and Google Cloud Functions have ties back into how the underlying infrastructure is managed currently. We do anticipate this being fixed in all of the commercial offerings very quickly.
Overall pricing is still pretty opaque for all the offerings, but we can be pretty confident that all of the service providers will try to remain price competitive with each other, and will be vastly cheaper than maintaining VMs or other infrastructure. This will be a volume business, and, as I will return to later, the real margins are in other areas.
The Serverless Framework
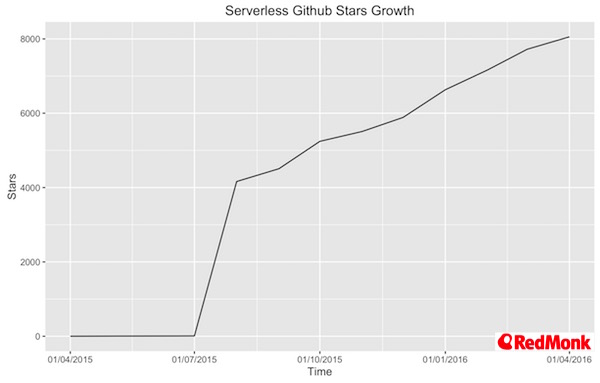
The first major project to emerge in the opensource arena has been the serverless framework, which focuses exclusively on building applications with AWS Lambda and API Gateway. At last check it had grown immensely in popularity on github:
Internet of Thing & Serverless
As we mentioned already one of the most natural applications for Serverless is the Internet of Things. Stripping away all the hype, at their core most IoT devices are essentially relatively dumb sensors combined with some control points.
In most IoT use cases you gather data from sensors, in general you will aggregate it in some form of gateway, possibly doing some basic control actions, and then the data is submitted to a system where it is processed and events triggered.
Now both Amazon and Microsoft fully understand this use case, and are pushing hard for people to link the last mile of devices through to their serverless frameworks. In both cases we see their entire IoT suites being linked up with their serverless offerings to provide a really easy way to both react to events, and more importantly, push sensor data into data lakes where it can be used for other purposes, such as machine learning for predictive analytics.
Competition to Containers?
This is the million-dollar question, and one we have been asked a number of times recently – could serverless remove the need for containers. The answer is, as always with areas such as this, it depends on the workload and type of application.
The Economics of Serverless
As we mentioned when we looked at each of the offerings, where pricing is available the pricing of executing a function which you need it is vastly cheaper than spinning up and down VMs to meet demand. There are multiple studies on how under utilised existing infrastructure is, even in the cloud. The ability to execute a function and use just the compute resources you need eliminates many of your utilisation questions in at least one area.
The serverless business has two distinct elements, data and compute. By using serverless companies can significantly reduce their costs for compute, and focus on the value of their data, paying for relatively high margin offerings, such as event streaming or database services, that in an over the top model they would manage themselves.
The opportunity for the cloud providers is huge. As I have mentioned a few times recently there are essentially two operating systems, cloud and mobile, and for cloud providers their current focus is on getting workloads into the cloud. Once you have workloads in the cloud you want to ensure data stays there.
In many respects Serverless turns the workloads discussion on its head. You now need to have your data in the cloud first to execute your compute functions in the first place. The stickiness, and value, of this approach for cloud providers is incredible. But so is the value for developers.
RedMonk and Serverless
At RedMonk we have been interested in Serverless from the moment we saw it emerging. If you want to dig a little deeper we are the co-organisers, along with A Cloud Guru, Implicit-Explicit and Serverless Code, of ServerlessConf which will run in New York on May 26th and 27th. James Governor will be there from RedMonk.
Our IoT Conference, ThingMonk, is coming up this September 13th and 14th in London, and we expect to see some more serverless and IoT content this year. You should come along.
Disclaimer: AWS, Docker, Cohesive Networks and IBM are current RedMonk clients.
Top 10 links for the week of Apr 25 - HighOps says:
May 1, 2016 at 10:43 am
[…] Serverless: Volume Compute for a New Generation […]
How to Use Spring Boot for Serverless Computing - says:
May 16, 2016 at 11:11 am
[…] Serverless Computing is a relatively new technology which allows developers to build event-driven code which scales and for which you only pay the time it’s running. OpenWhisk is IBM’s serverless computing offering hosted on Bluemix. […]
Francis Kim says:
May 17, 2016 at 12:12 pm
Go PHP & JavaScript! <3
AWS Lambda and the Spectrum of Compute | Linux Admins – News and Blog says:
January 25, 2018 at 11:27 pm
[…] a wide variety of scenarios. This makes perfect sense, as we noted previously Serverless is volume compute for a new generation of applications, with significant upside for the providers in usage of adjacent services, and […]