“You may have heard about our [directory assistance] 1-800-GOOG-411 service. Whether or not free-411 is a profitable business unto itself is yet to be seen. I myself am somewhat skeptical. The reason we really did it is because we need to build a great speech-to-text model … that we can use for all kinds of different things, including video search.
The speech recognition experts that we have say: If you want us to build a really robust speech model, we need a lot of phonemes, which is a syllable as spoken by a particular voice with a particular intonation. So we need a lot of people talking, saying things so that we can ultimately train off of that. … So 1-800-GOOG-411 is about that: Getting a bunch of different speech samples so that when you call up or we’re trying to get the voice out of video, we can do it with high accuracy.” – Marissa Mayer, Google
When I talk about the value of telemetry – a technology that allows remote measurement and reporting of information that I commonly use to refer to generated behavioral, usage and other potentially usable data – one of the first questions I usually get is predictable: “just how valuable is it, really?” One of my answers is Mayer’s example, above: “valuable enough that Google built and offered toll-free 411 services to get it.” So mainstream has the concept become that outlets like CNN are writing about it.
Which is right, because data is easily that important.
The Value of Data
Profits, says 37Signals’ Jason Fried in this Inc interview, should be the focus;not followers. Precious few survivors of the first dot com boom and bust cycle will take issue with that. But absent from that perspective is the realization that one may lead to the other far more directly than is commonly understood.
Much has been made of the lack of an obvious revenue model for properties like Twitter, and to a lesser extent, Facebook. But when looking at the organizations’ balance sheets (hypothetically speaking, of course, as most are private), it seems self-evident that the value of the data assets involved is seriously underreported. When you have, as Facebook does, enough data on hand that you can deliver a plausible “gross national happiness” index, it seems inarguable that there’s commercial value to be mined. Not from such a trivial metric, of course: who can reasonably be expected to pay for a “happiness” index? But consider instead the obvious commercial opportunities: is your brand trending up or down? How about your competitor’s? Is it viewed positively or negatively? And so on. The value of catching production issues, questions or concerns in real-time on social-media properties is potentially enormous, given the alternative: waiting to see monthly and quarterly sales fluctuations.
If you’re looking for concrete evidence of the value of this data, look to last week’s Bing and Google Twitter deals. As John Battele says:
Last week was big for Twitter. After years of speculation about whether the company was going to have a business model, Twitter announced two deals at our Web2 conference – first with Microsoft’s Bing, and second with Google. Details of the deals were not disclosed, but as Google’s Marissa Mayers admitted onstage, there were indeed financial terms.
You could also make the argument that Adobe’s $1.8B acquisition of Omniture was made with this very scenario in mind.
The economic value being assigned to data helps to explain why, while being sympathetic to questions about Twitter business models, I’ve never been overwhelmingly concerned. Where the revenue model for the dot com era “eyeballs” strategy was equal parts indistinct and aspirational, the Web 2.0 businesses are being built out in an era of customers increasingly predisposed to analytics and data driven decision making. In other words, there’s a market for their most valuable asset. True, it’s an asset that they merely enable, rather than pay to create, but for most users it’s a fair trade: they get functionality – social networking or otherwise – in exchange for their data, while the providers can mine that data for insights that in turn subsidize the production of the functionality that keeps users engaged and producing data.
Nor is that model limited to the large properties. There is, or will be, markets for data collected from enterprise of all shapes and sizes. Twitter and Facebook’s will be worth more, of course, because volume matters from a statistical perspective. Some datasets will be valuable merely in the aggregate, say your average small business, but the worth of data will continue to rise for businesses – even individuals, in some cases – that generate it. And most will. As asset values rise, the marketplaces that service them will inevitably follow; unless we’ve seen a repeal of the basic laws of economics.
So the future looks bright for data sales. If the would-be sellers and marketplaces can quell the privacy concerns, that is.
Privacy and Monetization of Data
After the conversation about the real value of data, the second most asked question I get is: “but what about the privacy?” As you might expect, given that violations of privacy laws can result in overwhelming financial penalties, jail time, or both. And even if you escape the official law, the court of public opinion is always willing to try and convinct you for questionable decision making, as Facebook learned (again).
But data collection, marketing and sales need not violate privacy laws, nor provoke customer outrage.
After all, it’s already being done, and the villagers have yet to show up with torches and pitchforks. Examples abound. And not just in monolithic, behind the scenes players such as Acxiom. Tim O’Reilly’s been using his book sales data for pattern analysis for years. Google, meanwhile, tells us what the world was thinking with Zeitgeist. The average consumer might not appreciate what, precisely, that means. But those of in the industry should: Google watches – intimately – how we interact with its search engine, and what we do with it. And uses that information, daily.
Even technically savvy and privacy sensitive communities will volunteer to share their telemetry if it provides an obvious benefit. The Debian Popularity Contest is the product of thousands – or is it millions? – of Debian users the world over, each of whom “phones home” their respective package choices. Individually, they are mundane and uninteresting. Collectively, however, the data is very interesting, highlighting as it does adoption and usage trends. How do they deal with the question of privacy? By acknowledging it openly and transparently, theoretical weaknesses and all:
Each popularity-contest host is identified by a random 128bit uuid (MY_HOSTID in /etc/popularity-contest.conf). This uuid is used to track submissions issued by the same host. It should be kept secret. The reports are sent by email or HTTP to the popcon server. The server automatically extracts the report from the email or HTTP and stores it in a database for a maximum of 20 days or until the host sends a new report. This database is readable only by Debian Developers. The emails are readable only by the server admins. Every day, the server computes a summary and post it on . This summary is a merge of all the submissions and does not include uuids.
Known weaknesses of the system:
1) Your submission might be eavesdropped. We evaluate the possibility to use public-key cryptography to protect the submission while in transit.
2) Someone who knows that you are very likely to use a particular package reported by only one person (e.g. you are the maintainer) might infer you are not at home when the package is not reported anymore. However this is only a problem if you are gone for more than two weeks if the computer is shut-down and 23 days if it is let idle.
3) Unofficial and local packages are reported. This can be an issue due to 2) above, especially for custom-build kernel packages. We are evaluating how far we can alleviate this problem.
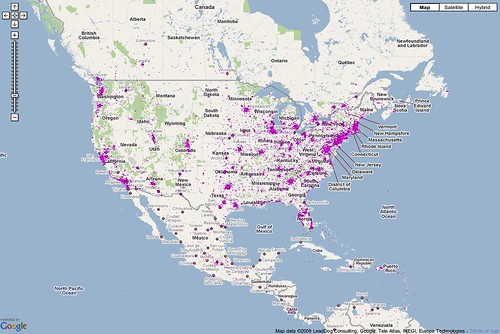
Debian is far from alone in these practices. The pink dot chart below was a favorite of Sun’s Jonathan Schwartz; each point indicates a piece of Sun software that had fed back basic telemetry to the firm.
Eclipse also collects user telemetry via its Usage Data Collector component. Specifically, according to the FAQ, it aggregates:
- Bundles (also known as plug-ins) that are started by the system.
- Commands accessed via keyboard shortcuts, and actions invoked via menus or toolbars.
- Perspective changes
- View and editor open, close, and activation events (activations occur when a view or editor is given focus).
What about the privacy concerns?
“It’s valuable to also note what we do not capture. We do not capture any personal information. We do not capture IP addresses. We do not capture any information that will allows us to identify the source of the information.”
What can you conclude from such data? Who knows? Here’s a non-authoritative (because I don’t know all the user strings), washed spreadsheet detailing the user counts of dynamic editing clients for PHP, Python and Ruby this year from January through October, 2009:
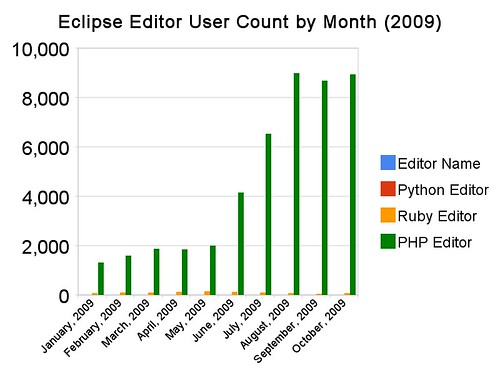
Definitive? Hardly. An interesting datapoint? I think so.
But maybe you’re in an enterprise so tightly firewalled that that telemetry cannot make it back to the aggregating servers; think you’re not being studied? Think again. If your employees visit websites, they are being studied.
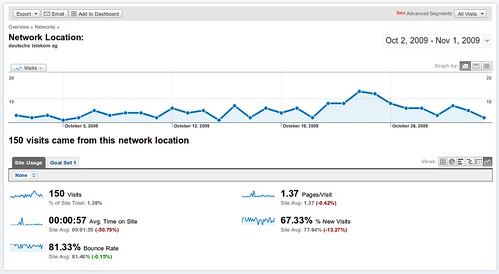
As they are if they use software-as-a-service tools like Google Apps, Salesforce.com or any of the 37Signals applications, for that matter.
The short and sweet version of the above is that more and more of what you do is, or will be soon, analyzed. The question is whether or not you believe that to be inherently and irredeemably wrong. It’s largely an academic question, of course. The SaaS vendors, at least, will go on exploiting your usage data whether you want them to or not.
The answer is that data collection and analysis is a tool: nothing more, and nothing less. It can be used for endeavors good, bad and indifferent. Is it consumer friendly when American Express uses data to punish you based on where you shop? Clearly the answer is no. But is it helpful for Google to be able to identify flu outbreaks via search data? Yes.
If data analytics are neither good or bad, then, success – both economically and in terms of public perceptions – will be determined by execution. Consider carefully what you decide to track, how you track it, how closely you guard your users privacy, and where you sell your data and in what form. Because a reputation once lost is not easily regained, as they say. While Facebook has been able to shrug off headlines such as “Facebook’s New Terms Of Service: ‘We Can Do Anything We Want With Your Content. Forever.’,” and concerns about the mining of Gmail accounts seem to be a distant memory, not everyone will be so fortunate. JetBlue and Northwest mostly recovered from their breaches of customer trust, but at what cost? As much as the economic opportunity that data represents will be an incentive, the user’s needs must always come first: be sure that you have a strong user advocate present and empowered in any and all discussions about the usage of telemetry data.
Marketplaces will have an important role to play with respect to privacy, as well. Just as we’re seeing in application stores – at times overzealously, it must be said – data marketplaces will have a responsibility to buyers and sellers alike to carefully consider what they accept and what they turn down. Certain cases will be obvious: no legal marketplace will broker the sales of stolen credit card number databases, for example. But other datasets may seem more innocuous: are offerings that include IP addresses inevitably privacy infringing? Questions like those will probably create a secondary market for data cleansing and normalization vendors; in partnership with marketplaces, they could offer anonymizing data as a service.
Irrespective of the privacy concerns, the collection and analysis of data is accelerating. If data isn’t already an asset you list on your balance sheet, it soon will be. Why not get a head start on the privacy questions, then, and start thinking about what can be sold and what can’t, now? As soon as the marketplaces open on a volume business, you’ll thank me.
