“Baseball Prospectus’ preseason PECOTA projection for the Boston Red Sox: 95-67, second place
Actual record for the Boston Red Sox: 95-67, second place” – Kiss ‘Em Goodbye: Boston Red Sox
Even if you don’t follow baseball, you can probably appreciate that predicting the performance of a baseball team over a 162 game season is a difficult task. Injuries, abnormally good or bad performances, trades, even weather can affect the outcome of any given season significantly. And yet the Baseball Prospectus guys were able to nail it to the game.
Who says predicting the future is hard?
Or maybe you think that sports are too anomalous, too trivial, and that the above is a superficial and ultimately irrelevant example. How, then, do you feel about politics? Because happily, Nate Silver – the original creator of the PECOTA algorithms used above to predict the Boston Red Sox’s unfortunate second place finish – has turned his extraordinary talents to the problem of predicting elections. Does it work? Yep. Really, really well. As Wikipedia puts it, “Silver’s predictions matched the actual results everywhere except in Indiana and the 2nd congressional district of Nebraska, which awards an electoral vote separately from the rest of the state.”
Still not convinced? Consider then, as we have before, the case of Google Flu trends. It’s using data that indicates, as the diagram below shows, a spike in flu related activity here in Maine.
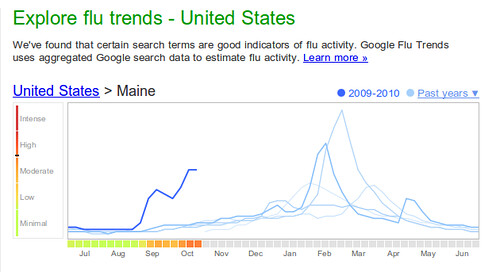
Which seems like an accurate conclusion in the wake of today’s piece in the Portland Press Herald entitled, “H1N1 widespread in Maine, top health official says.”
How are these predictions made possible? By an awareness and ability to use data. Maybe algorithms aren’t the magic bullet, but they’re damn close.
Which brings us back to the conference. When IBM’s head of Software Group Steve Mills talks, it’s usually in the vernacular of enterprise businesses, with a message tailored at same. Which makes sense; speaking in a language your customers understand is good business, and IBM’s been doing pretty well for itself recently. But one of his Monday comments at this week’s Information On Demand show in Las Vegas should, I think, be fairly universally appreciated. So much so that I’m inclined to believe that even Silver, whose business is a fair distance removed from enterprise software, would subscribe.
He said, in part, “that we’re moving into yet another wave of transformation.” More specifically, that “we’ve been living in a decade of process led transformation, and that we’re moving into an era of information led transformation.” Translated, the time of data driven decision making is at hand. So yes, designers: you may occasionally be asked to prove why 3 pixels is better than 5.
It would be naive, of course, to suggest that data driven decision making is somehow new. Repeat after me: there’s nothing new in technology. Everything from where products are placed within a supermarket to when your favorite TV shows are placed on the calendar is, and has been for a long while now, determined by a particular set of numbers. What’s different these days is that we have exponentially more numbers than we did before, better tools to attack them, and an understanding that if you aren’t using the numbers to improve your business – every aspect of it – your competitors will.
There are three primary components to this transition: market, server and client. There’s the data, too, but that deserves a post of its own.
Market
The technology industry has for the past several years been long on storage growth trivia, detailing for us all by the byte the incomprehensible amounts of data being generated yearly, monthly, even hourly. What we’ve been short on, however, have been stories about how that data is actually being put to good use. The idea certainly isn’t new; warehousing and business intelligence have been staples of the technology industry for decades. But just as cloud computing makes available resource volumes and types that were once out of reach of all but the largest businesses, the growing availability of better and lower cost technologies with an ever increasing supply of datasets dramatically upleveled the visibility of analytics for the average technologist. Perhaps more importantly, it’s received a boost from people like Silver and bestsellers like Freakonomics. For what seems like the first time you can have a conversation with a non-technologist about data and they get it. That’s important, because it widens the addressable market from numbers geeks to include people with actual budget. Not a bad development.
Server
One of the conversations I had at IOD followed a path you’ve heard here before many times: the breadth of persistence options for application developers has never been wider, and while the relational database will remain a popular option for years to come, the days of it being the only option are almost at an end. Consider IBM. For all of its investments in the relational space, the folks from New York seem to get the complementary roles non-relational tools can play as well as anyone; from CouchDB, where they employ Damien Katz, to Hadoop, where their M2 demo is one of the more interesting I’ve seen recently to Cassandra, which they are apparently contributing to. All three of which are part of – along with other projects like Drizzle, MongoDB, Riak, Tokyo Cabinet, and Voldemort – a new set of alternatives.
Whether you know the category as NoSQL or AltDB doesn’t really matter – they’ll still smell as sweet. And be as good a fit for those workloads that just aren’t quite appropriate for the relational databases you grew up with.
Fueling their respective popularity, not surprisingly, is the fact that most of the NoSQL/AltDB options are open source. The tools for making sense of mega data are available to anyone and everyone, which is a far cry from the days when warehouses meant an early retirement for data center systems integrators and software salespeople.
Client
It’s not enough, as anyone who’s viewed raw Apache server logs can tell you, to have access to a lot of data. You need a way to make sense of it; to parse it and present it back in a meaningful fashion. As far as we’ve come on the server side is as far as we’ll need to go with the client. True, the democratization of Business Intelligence tools is well underway – just take a look at what Flowing Data can do with information. It’s so useful it’s pretty. Excel may be enough for geniuses like Bill James, but us mere mortals will needs some help seeing the patterns. Think ManyEyes, but even more accessible.
Look for data visualization clients to be the next category for data driven innovation, then. Because it’s great to be able to manipulate the data, but it’s even better to be able to use it. With something this side of a Java query, I mean.
Disclosure: IBM, the organizer of the IOD show, is a client and comped hotel. Cloudera, a commercial sponsor of the Hadoop project, Basho (Riak), and Sun (Drizzle) are also RedMonk clients.

tecosystems » Infochimps and the Inevitability of Data Marketplaces says:
October 30, 2009 at 5:02 pm
[…] as the tools of data analytics are being democratized, as I mentioned yesterday, so too will the means of data acquisition. Infochimps illustrates this perfectly; if […]
tecosystems » You’re Going to Do What With My Data?: Privacy and Data as a Product says:
November 2, 2009 at 8:17 pm
[…] indistinct and aspirational, the Web 2.0 businesses are being built out in an era of customers increasingly predisposed to analytics and data driven decision making. In other words, there’s a market for their most valuable asset. True, it’s an asset […]
tecosystems » What’s in Store for 2010? A Few Predictions says:
November 13, 2009 at 9:28 am
[…] will continue. I’m fully in agreement with IBM’s Steve Mills when he says that we’re “moving into an era of information led transformation.” As margins […]
tecosystems » What the National League Cy Young Vote Can Teach Us About Data Driven Decision Making says:
November 24, 2009 at 5:02 pm
[…] would think that the coming transition to data driven decision making would be welcome. Cheered, even. But you would be wrong. And this […]
tecosystems » Data and its Sharp Stick vs Intuition says:
February 9, 2010 at 5:34 pm
[…] we don’t need high powered software executives like Steve Mills to tell us that the tide is turning towards data driven or evidence based decision making. We can […]
tecosystems » Why I’m Taking Statistics says:
April 7, 2010 at 3:45 pm
[…] head of Software Group Steve Mills said late last year that we are “moving into an era of information led transformation.” I […]