Yesterday Felipe Hoffa from the Google Dev Rel team published some interesting research looking at corporate usage of GitHub. Given my post on the danger of GitHub astroturfing yesterday I was keen to dig in.
“For this analysis we’ll look at all the PushEvents published by GitHub during 2017.”
Headlines concerning cloud companies.
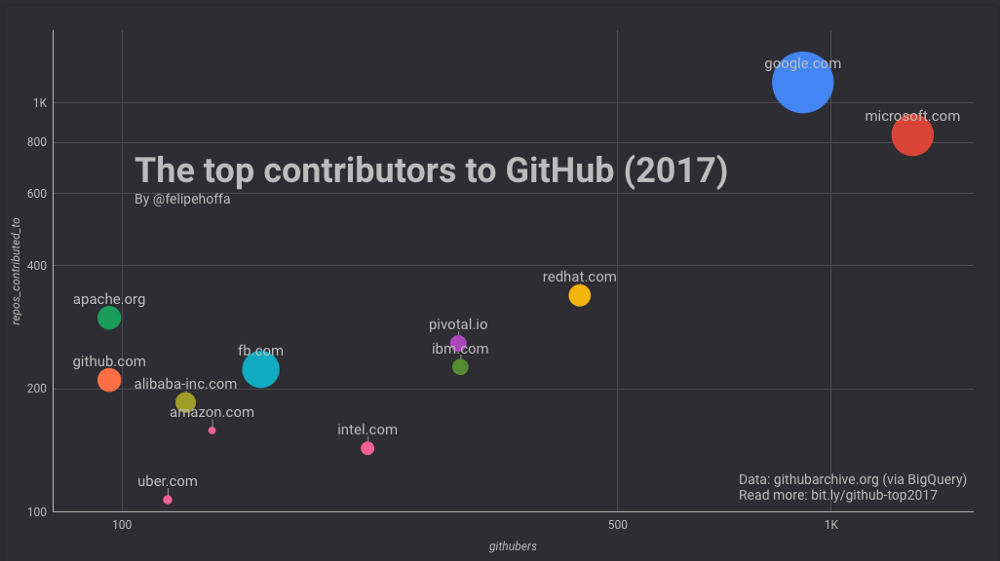
- Microsoft appears to have ~1,300 employees actively pushing code to 825 top repositories on GitHub.
- Google displays ~900 employees active on GitHub, who are pushing code to ~1,100 top repositories.
- Amazon appears to have only 134 active employees on GitHub, pushing code to only 158 top projects.
So all the usual caveats on using GitHub data notwithstanding, and the limits of this particular analysis, Microsoft has the most contributors by some distance, some 45% more than than Google, but they’re working on a smaller number of top projects. Amazon Web Services meanwhile barely shows up as a contributor. Nothing really surprising in any of this, but even in 2017 it’s possible to sit back and marvel at how far into open source Microsoft is these days.
What is surprising on the other hand, at least at a glance within the limits of this methodology, is that Pivotal is currently contributing as much software to open source projects as IBM. Given IBM has built deservedly solid reputation over time as an open source contributor across various core infrastructure projects, and is at least 150 times bigger than Pivotal, this is fairly impressive. I noticed that in the twitter thread about the post initially only us.ibm.com email addresses were being counted, but it still really stood out, at least to me.
On the same thread was a pointer to another information resource gleaned from GitHub.
if you guys interested in total stars.. https://t.co/N7ra94M0bI 🙂 (always up to date)
— Lipis (@Lipis) October 24, 2017
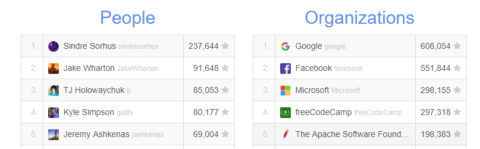
So I went to check it out. The site include corporate contributions by company names but also stars that individuals have earned and – holy shit – Sindre Sorhus. What can you say about Sindre Sorhus?

237, 644 stars? To be honest I couldn’t see how the maths add up with the lipis service. But well north of 100k stars at a glance on Sindre’s GitHub page is pretty amazing for an individual. Sindre curates awesome, a curated list of awesome lists. Nearly 68k stars, 314 contributors. Avajs (great name, by the way) looks like his “day job”.
Hats off to Sindre for making things people like.
disclosure: AWS, IBM, Microsoft, and Pivotal are all clients, but this analysis is independent.
related: So where all the GitHub link farms at? Astro-turfing in software development.
Sean Dague says:
October 26, 2017 at 1:21 am
Because IBM’s mail infrastructure is based on Lotus Notes, it’s not really conducive to Open Source (for a lot of reasons). As such most IBMers doing any volume of Open Source do so on alternative mail infrastructure. A good instance of this getting missed is someone like Phil Estes, who is a Docker Captain, reasonably active – https://github.com/estesp – and yet docker doesn’t show up as a project for IBM, though it does for Microsoft.
It was a very early lesson of Jonathan Corbett when doing gitdm to analyze the Linux kernel, that email domains are very partial stories, and leave large chunks of the space uncovered. If you are actually trying to understand the space you need to do better than that. Having lived through many a bad statistics system hyper analyzing the OpenStack project, it is mostly amusing to watch everyone make all the same mistakes each time.
Nigel Jones says:
May 25, 2018 at 3:57 pm
Ditto – I’ve been working on an apache project, a little github (more to follow). Similarly using gmail.com address…. and I see many examples of this
jgovernor says:
October 26, 2017 at 9:49 am
yeah Sean, i am sure that’s absolutely right. email domains is certainly a problematical proxy. that said the data is there, so people are going to try and analyse it, whether or not its “funny”. i raised the issue in the post myself, and there will always be gaps in the telemetry.
maybe ibm could curate a list of email addresses or GitHub IDs of employees that are contributing to help with this stuff when people do analysis? it would be useful frankly from all vendors.
Sean Dague says:
October 26, 2017 at 11:04 am
IBMers on github regularly join the IBM org – https://github.com/IBM which currently has 932 members (only about 50% of those make it public by looking at the list right now). That’s probably as good as any list for publishing these things.
The experience I’ve had with interacting with the statistics in OpenStack (gitdm, bitergia stuff, blackduck, and stackalytics), is that pulling numbers and making graphs ends up with very incomplete versions of the story. You need domain knowledge with the projects and communities to be able to spot check and realize your analysis dropped something kind of important. Stackalytics has numerous correction mechanisms built into for this, org / time for all contributors (which you can upload and fix), and being able to discount particular changesets are largely machine generated. The domain counting ends up also *really* heavily undercounting Chinese organization contributions, as for similar reasons on challenges with mail infrastructure, they all tend to use gmail.
It is a reason why in Science efforts like this are peer reviewed before publication, and that strong justifications are made for why certain thresholds are taken. Like the 20 new stars this year? What 20 vs. 10 vs. 0? For instance in rerunning the queries nodejs only shows up as a valid repository once you drop the required stars count to 5 (it doesn’t change the top 5 ranking, as MS, Google, IBM all contribute to it), however the fact that the baseline query excludes nodejs as a project, seems weird.
Or the fact that the metric of maximization is # of repositories contributed to is the metric of record. vs. Commits, PRs merged, LOC, or anything else. And why that should be defined as “Contributed most to Open Source”? It’s fine to give answers to these. But they should have answers. And the data should be looked at in a few dimensions to make sure there isn’t overfit on one metric class.
To me the real story of this should mostly be, Microsoft really has showed up big in Open Source. For all the past history, and detractors, and people that don’t want to believe it, they as an organization really have embraced open source as good as any large company. It’s not just marketing. That’s super cool, and good for all of us that believe strongly in Open Source.
jgovernor says:
October 26, 2017 at 1:45 pm
amen sean.
Ant Stanley says:
October 26, 2017 at 3:57 pm
Would say this data is deeply misleading. For example the Apache MXnet repo doesn’t appear in any of the searches, despite having 11K stars and contributors from Amazon, Baidu and a number of universities, majority of whom clearly identify who their employer is. That’s a single example. There are loads others. I would double check Felipe’s original queries to understand how he is sourcing the data.
Chris Ferris says:
October 27, 2017 at 6:49 pm
James, IBMers have a nasty habit of contributing to OSS using their personal, not corporate email. This means that they are mostly dark matter when it comes to GH analytics. Sean did a great job of highlighting this, but as another example, when you scour Apache for IBM contributors a certain [email protected] is nowhere to be found, despite Sam Ruby being one of the more prolific contributors to Apache projects over the years.
As to the list, well we’ve been trying to do that. We even created a tool to map GHid to corporate email that they could register with; but some feel somehow that this is too big brother for their tastes.
I agree with Sean, that MSFT DOES deserve credit for their collective 180 degree turnaround when it comes to open source, but I also feel that it is equally important to call out when “studies” like the one you linked, or even the Octoverse report are based on bad data, and then used to market complete nonsense claims such as Microsoft is the largest open source contributor. That’s as much nonsense as Pivotal is equal to IBM. Also complete nonsense.
jgovernor says:
October 27, 2017 at 9:05 pm
thanks Chris. would be only too happy to try and tease out some analysis of the dark data, and perhaps encourage your colleagues not to fear being more declarative.
Nigel Jones says:
May 25, 2018 at 3:58 pm
In the case of Apache projects, anyone who’s a committer will have an @apache.org email address, and typically use that …