TL; DR – NVIDIA are firing on all cylinders across their business, and making strategic moves to cement their place in the emerging AI ecosystem.
We attended NVIDIA’s GPU Technology Conference (GTC) in San Jose last month. The buzz around the conference was quite exceptional, attendees that we spoke with are working on some exceptional research and practical applications in the fields of AI and Deep Learning.
NVIDIA were keen to cite statistics about the conference and their wider community, with the conference having a 3X growth rate over the last five years to 7000 attendees. More interestingly they noted that their GPU developer community has grown 11X to 511,000 over the last five years. The latter figure, while hardly surprising given the wider industry shift, is still a significant expansion of their community.
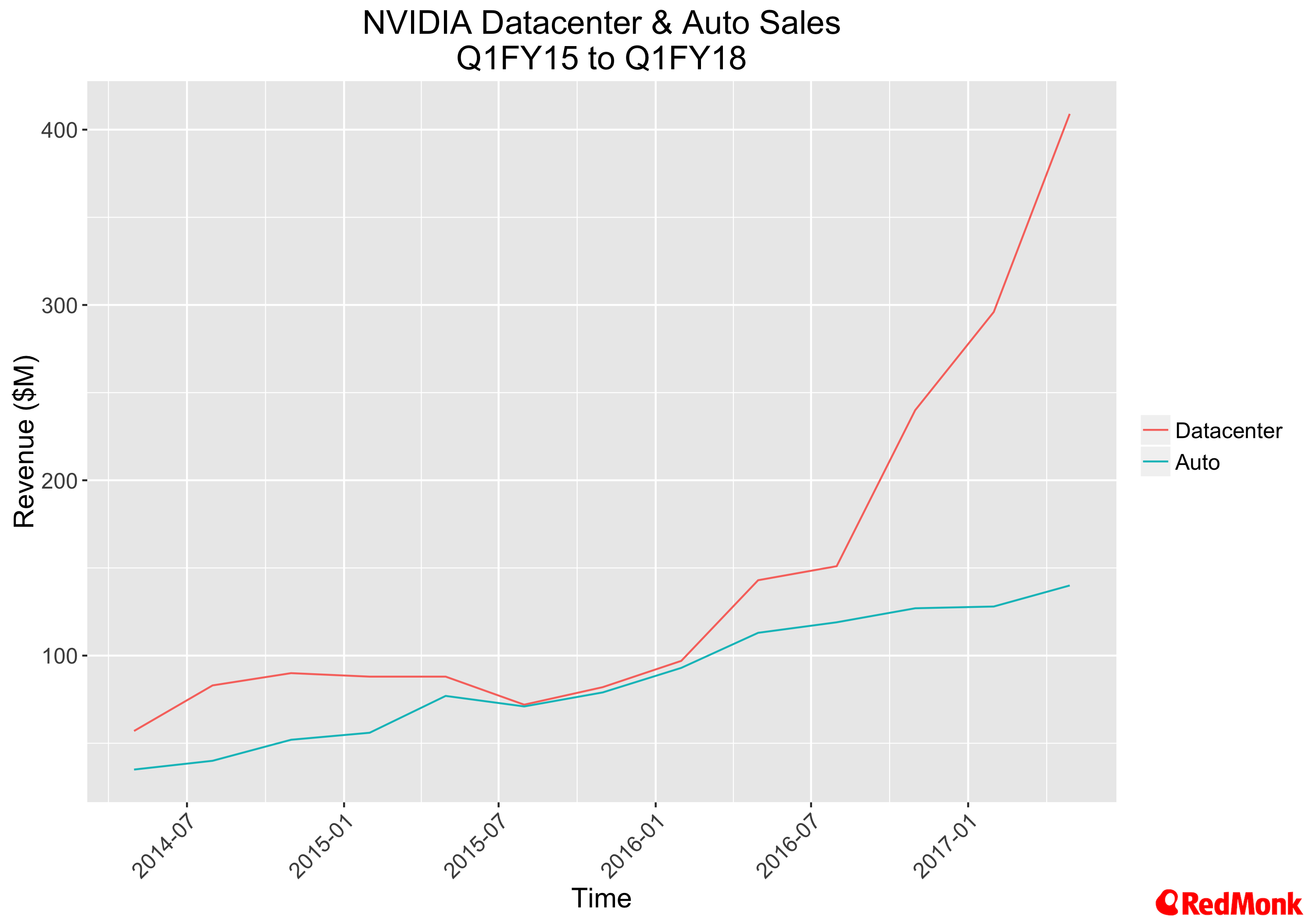
While the statistics above are very impressive there was one other number that came out during the conference that was astounding. The NVIDIA data centre business has seen growth of 280% year on year, fuelled in no small way by the demand that is being seen by their partners with Amazon, Microsoft, Google, Alibaba, Baidu and IBM.
On the software side of the house, NVIDIA made several significant announcements, and the most strategic of these is, in our opinion, the NVIDIA GPU Cloud and associated tooling, which we discuss in more detail below.
When A Cloud Is a Portal – The NVIDIA GPU Cloud
During GTC NVIDA announced the NVIDIA GPU Cloud. The naming is a little confusing here. It is true to say that NVIDIA have a cloud offering of sorts, but the intention here is to easily manage, scale and drive workloads to the major cloud providers.
Now at RedMonk we are always talking about the value of packaging, and this is a packaging exercise across the most important aspects of deep learning and AI. As we recently noted there is a transition happening in the world of data science, where the infrastructure is finally becoming a service to be used, rather than the focus of much of the work in and of itself.
NVIDA get this. Indeed, one of NVIDIA’s big themes during the event was the cost of AI expertise, and the fact that last thing you want such people spending their time on is infrastructure. You want them to experiment, iterate, and scale up and down fast.
There are three key components being brought to the table to enable this. Firstly, the hardware aspect from local workstations (albeit workstation is a generous phrase for the DGX Station. This is a far cry from the SPARCStation IPC I started my own career on) through to local datacenters and onto the cloud. Secondly the NVIDIA GPU Cloud Deep Learning Stack, and finally the availability of pre-trained models. It is the latter two we will focus on here.
NVIDA GPU Cloud Deep Learning Stack

NVIDA are investing significant engineering resources into creating and maintaining baseline software stacks, sensibly packaged as containers, for AI specialists, data scientists and developers to use.
They are packaging up the various NVIDA components, such as CUDA, NCCL and TensorRT with the major machine learning frameworks in use today. Their chosen frameworks are
- Mxnet
- Caffee2
- TensorFlow
- Microsoft Cognitive Toolkit
- PyTorch
These choices make perfect sense, in our own research we see the vast majority of deep learning workloads moving to one of these five frameworks, with TensorFlow in particular taking a significant lead.
As a packaging exercise keeping this matrix of components up to date and in sync is a non-trivial exercise, and NVIDIA are addressing a significant gap in the market by providing support to customers who wish to use the various components across a variety of environments.
This is a critically important strategic move for NVIDIA. It is a cliché to say software is eating the world, but it is a cliché for a reason. The risk for vendors primarily associated with providing hardware is how easily they can be dropped from any strategic conversations. By packaging up the various components and becoming an essential building block of both the software and hardware toolchains NVIDIA ensure their place in the conversation going forward. As we like to say at RedMonk in any software revolution the best packager almost always wins.
Pre-Trained Models
The exact details on what NVIDIA will offer in terms of both pre-trained models and data sets are still being clarified. However, this approach makes a huge amount of sense. As enterprises begin to get comfortable with transfer learning, there are significant commercial opportunities opening for many.
Data sets is a relatively new area of competition. We have seen IBM and Google make significant investments in public and proprietary datasets in recent times (IBM’s purchase of the Weather Channel for example), and making clean, easy to use and frequently updated datasets available to researchers is extremely valuable.
The commercial environment around trained models and algorithms is still forming, but start-ups like Algormithia have been leading the way here for some time. It will be interesting to see where NVIDIA brings it.
TensorRT – Optimizing Performance
Performance tuning is a time consuming and laborious business, but the benefits can be incredible. It is why, to this day, we find ourselves deeply impressed with the work that people and the compiler, linker and library layers do to make performance gains easier for the rest of the technology community to access.
The latest iteration of TensorRT has updated optimizations for the Caffe framework, and, significantly, support for TensorFlow. This allows developers to develop and train models in both TensorFlow and Caffe, and when they are ready to deploy them into production leverage TensorRT to optimize the model for inference. This is in part, again, a packaging exercise.
Why is this significant? Well for one it opens options up to Googles recently announced TPU. If you can take your trained TensorFlow model and get relatively similar results to what Google is offering with the TPU, you may choose to go the NVIDIA route due to the availability across various cloud providers and edge processing locations.
Strategic Partnerships
There were several significant partner announcements during the event, but to our mind one sticks out – SAP AI for the Enterprise. SAP customers are sitting on a treasure trove of data, and SAP are actively working on ways to help their customers leverage this data to improve their business process. SAP have been working on this for a while, and the SAP Leonardo announcements at their recent Sapphire event are the main public manifestation of this.
Digging under the covers a little you can see the business value in the offerings that are being developed. During GTC SAP were keen to talk about their Brand Impact offering, citing a case study with Audi, where they ran a real time evaluation on Audis brand placement at a sports event. It may seem like a relatively trivial thing, but getting this type of feedback in real-time is invaluable to a marketing organisation.
As we have noted previously most developers will use machine learning via an API, and the offerings from SAP fall squarely into this trend. From the NVIDIA perspective, any growth for SAP in this area is a win for NVIDIA as well.
Alongside the partnership with SAP, NVIDIA also announced deepening relationships with both Amazon Web Services and Microsoft Azure, with both companies announcing support for the latest GPUs, alongside investments in their respective deep learning frameworks of choice.
AI on the Edge
Possibly the largest coming change in how AI is deployed is the shift towards the edge, be it in complex devices such as autonomous vehicles to more simplistic use cases such as phones and watches.
In most of these cases we are looking at a model trained in the cloud, with inference on the edge. NVIDIAs focus in this area is their Xavier offering, their low powered offering and too this end NVIDIA announced that they are open sourcing their Xavier DLA platform in July.
The Ethical Dilemma?
For all the technological advances discussed during GTC, the elephant in the room is still the question of ethics and AI. We asked some questions related to ethics during the analyst session, and the answers attempted to skirt around the issues rather than addressing them head on. This is disappointing.
In the same week that one of NVIDIAs major partners, Microsoft, were focused on putting the ethics of Artificial Intelligence front and centre in their overall message, the response of “we are a platform company” is not good enough anymore. Not just for NVIDIA, but for everyone involved in the industry.
We would hope to see the strong links into academia that are held by all firms creating the platforms for AI to succeed expanded to supporting programs research and such as the Ethics in Artificial Intelligence program currently underway at Oxford. As the saying goes, with great power comes great responsibility.
Disclaimers: NVIDIA paid my T&E. NVIDIA, Google, Microsoft, Amazon, IBM and SAP are current RedMonk clients.
Ralph says:
June 14, 2017 at 11:33 pm
This was a great post on the technology and recent advancement. Until you started talking about ethics. This is a technology post, not philosophy.
Not to discount the importance of the topic, but it’s really not the right venue or audience.