
Amazon Web Services annual conference, re:Invent, was held in Las Vegas last week, and to say there is a lot to unpack would be somewhat of an understatement. As my colleague Stephen O’Grady put it, Amazon pack more announcements into a two-day window than most companies manage in three years.
This is the first of several posts we will be doing on various aspects of re:Invent, and in this post we will primarily focus on Deep Learning, Elastic GPUs and FPGAs, and touch on some of the interesting compute announcements at the end.
Elastic GPUs
Earlier this year Amazon announced the availability of their P2 instances, which featured up to 16GPUS for heavy machine learning. Given the comments over the years on GPU performance in AWS it is fair to say that the P2 instances were eagerly anticipated and went a long way towards resolving many of the previous complaints around virtualized GPUs.
However, not everyone needs even a full GPU, never mind a dedicated instance. This is what makes the Elastic GPU concept so interesting. Attach as you need it, do the work, and then move on.
The initial Elastic GPU offering allows you to take as little as 1/8th of a GPU and use it as you need, and then move on. The offering is limited to Windows for now, with plans for support in the Amazon Linux Deep Learning AMI soon. There is one significant area of concern with the lack of CUDA support.
1/8 GPU to a full GPU that you can attach to compute #reinvent << really can't say how much this changes things for lots of users
— Fintan Ryan (@fintanr) November 30, 2016
Elastic GPUs is a legitimate big deal, as are the P2 instances – and Amazons sheer volume of customers will expose GPUs to a very wide base. It is, however, worth taking note of the fact that both Google and Microsoft have GPU offerings in beta as well.
Deep Learning Frameworks
As Amazon CTO Werner Vogels recently highlighted, AWS have decided to invest heavily in MXNet as their deep learning framework of choice. In his blog post Werner noted there key factors developers and data scientists use when selecting a deep learning framework
The ability to scale to multiple GPUs (across multiple hosts) to train larger, more sophisticated models with larger, more sophisticated datasets. Deep learning models can take days or weeks to train, so even modest improvements here make a huge difference in the speed at which new models can be developed and evaluated.
Development speed and programmability, especially the opportunity to use languages they are already familiar with, so that they can quickly build new models and update existing ones.
Portability to run on a broad range of devices and platforms, because deep learning models have to run in many, many different places: from laptops and server farms with great networking and tons of computing power to mobiles and connected devices which are often in remote locations, with less reliable networking and considerably less computing power.
It is against these criteria that Amazon have chosen MXNet.
What is interesting here is not just that Amazon are backing a framework, it is how explicitly they are backing a specific framework. Stepping back a little, there is clearly an element of coalition theory emerging in the deep learning space as well. While Google and others may be building a coalition around Kubernetes, they have, as we have noted in the past, stolen a march on the industry with the general popularity of Tensorflow – everyone else is now responding, and MXNet, regardless of its technical merits, is front and centre in this battle.
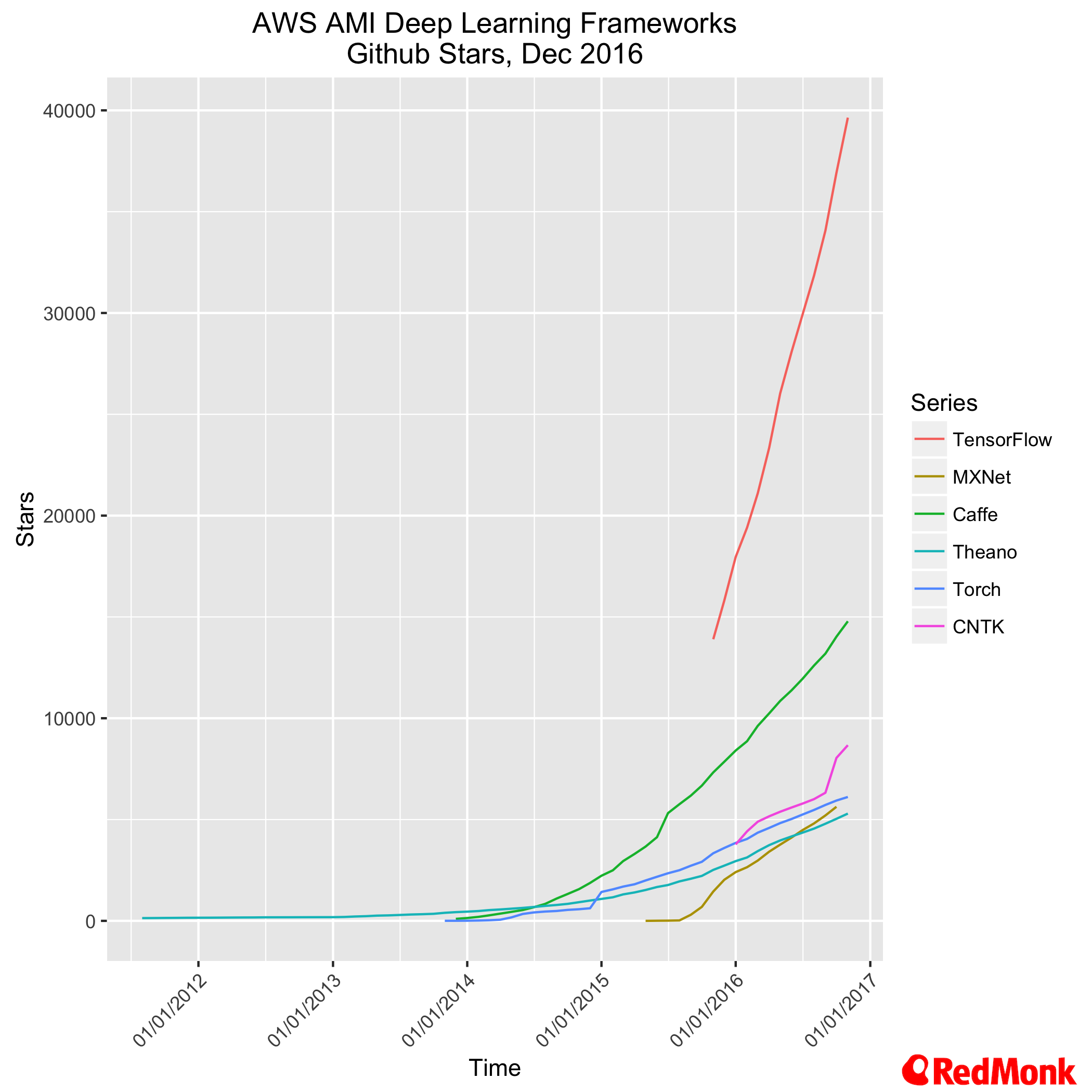
That said, Amazon have been very clear that they will support MXNet alongside a number of other popular deep learning frameworks such as Caffe, Torch, Theano, CNTK and of course Tensorflow.
Additionally, it is worth taking note of the development of Amazon DSSTNE (Deep Scalable Sparse Tensor Network Engine), and open source project from Amazon Labs. DSSTNE is focused on dealing with sparse training data – a very common problem once you step away from the headline deep learning examples of images or speech.
Now with all of this said, we have previously noted that most developers will access machine and deep learning via an api, and we still stand by that statement. At re:Invent we saw another manifestation of this approach in the announcements of Lex, Polly and Rekognition – all of which we will return to in due course.
FPGAs on Demand
Now Amazon are well known for going their own way, and their extensive use of FPGAs has not exactly been a secret in the industry. We had the pleasure of being in the company of Amazon Distinguished Engineer James Hamilton during the analyst event and he relished in describing how Amazon are both moving repetitive tasks to silicon and controlling the associated software update cycle, aspects of which he recapped again in his keynote last Tuesday.
With the announce of the new F1 instances Amazon are opening the possibilities of using FPGAs to a far wider audience than ever before.
FPGA dev kit, tool kits etc made available << chatted about verilog several times recently, genuinely this is huge #Reinvent
— Fintan Ryan (@fintanr) November 30, 2016
I had a set of conversations relatively recently with several leading financial services institutions, and one of the big reference points that I took away was a desire for, and shortage of, Verilog programmers. In any industry where speed is key, and the calculations are repetitive, offloading to FPGAs ultimately makes sense.
New F1 instance – customer programmable FPGAs << this is niche, but absolutely huge for specific industries #reinvent
— Fintan Ryan (@fintanr) November 30, 2016
This is a niche market, but it is a highly lucrative one. Right now, Amazon are set to completely own it. More importantly when you combine something like the F1 offering with the C5 Skylake instances you can begin to see some of the highest spending hedge funds, banks and trading floors moving some of their major workloads into Amazon. And with those workloads comes a massive amount of associated data which a whole host of other services can utilise.
As a little side note, even in the world of cloud you can always be a data center geek, and the pieces James Hamilton publishes are well worth some of your time.
General Compute Updates
We love ourselves some compute – @ajassy #reinvent pic.twitter.com/xP3LkSa5FW
— Fintan Ryan (@fintanr) November 30, 2016
In keeping with tradition, Amazon announced a set of new compute offerings, speed & feed revs and so forth. We already touched on the new C5 instances (think highly optimized compute tasks, machine learning), the other two worth explicitly calling out are the R4 instances which provide up to 488 GiBs of memory (think in memory databases, realtime analytics, Spark clusters and so forth) and the I3 instances which massive IO improvements (think high performance database workloads).
Credits: JTAG image by Andrew Magill on Flickr, CC2.0 license.
Disclaimers: Amazon paid my T&E for re:Invent. Amazon and Microsoft are current RedMonk clients.
Lambda kicks in, a serverless world made of messages - Enterprise Irregulars says:
May 9, 2017 at 5:06 pm
[…] fivethirtyeight media, which you can see over here. Fintan has written a couple of posts – one on Elastic GPUs, FPGAs, Deep Learning & Compute and another on Hybrid, Greengrass and the Future of On Premises […]